避免HDFS数据丢失:8个最佳实践与写入缓存优化指南
发布时间: 2024-10-30 04:14:49 阅读量: 5 订阅数: 9 
# 1. HDFS简介与数据丢失风险
## HDFS简介
Hadoop分布式文件系统(HDFS)是Hadoop框架的核心组件之一,设计用来运行在廉价硬件上并提供高吞吐量的数据访问,特别适合大规模数据集的存储和处理。HDFS具有高容错性,能够自动处理硬件故障,并提供了数据副本以确保数据的可靠性。
## 数据丢失风险
尽管HDFS具有容错能力,数据丢失的风险依然存在。这些风险包括但不限于硬件故障、软件缺陷、操作失误和网络安全问题。在HDFS中,如果NameNode发生故障,可能导致文件系统的元数据丢失,从而影响数据的可访问性。DataNode的故障可能导致数据块丢失,减少数据的冗余性。因此,对于HDFS的数据保护与备份策略显得至关重要。接下来的章节将深入探讨HDFS的数据备份最佳实践,以及如何优化HDFS以确保数据的持久性和完整性。
# 2. HDFS数据备份的最佳实践
在企业级数据存储中,备份数据以防止数据丢失是一项基本但至关重要的工作。本章旨在深入探讨HDFS数据备份的最佳实践,这不仅包括了技术层面的配置和实施,同时也涵盖了如何通过策略和工具优化备份流程,以应对不同场景下的数据保护需求。
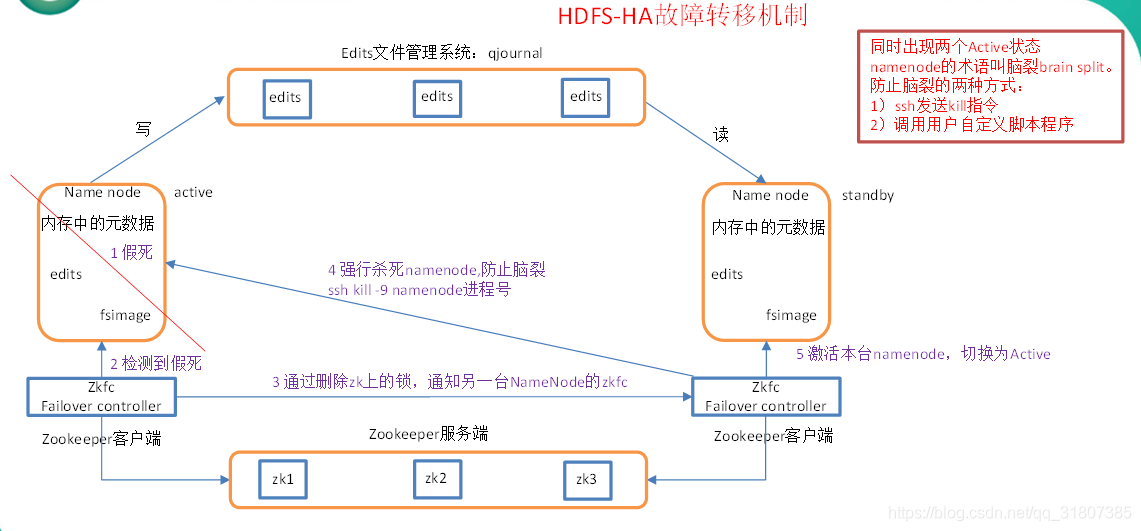
## 2.1 HDFS的高可用性架构
HDFS设计之初即考虑到了数据的高可用性,以确保在硬件故障或网络问题时,数据能够持续可用且不丢失。HDFS的高可用性主要依赖于NameNode的高可用配置以及DataNode的故障转移和数据复制机制。
### 2.1.1 NameNode的高可用配置
在HDFS中,NameNode扮演着元数据管理的核心角色,其高可用性对整个文件系统的稳定性至关重要。高可用的NameNode通常通过以下两种机制来实现:
- **共享存储法**:在这种配置中,多个NameNode实例共享一个外部的存储系统,比如NFS、ZooKeeper等,来存储文件系统的元数据。当主NameNode出现故障时,备用的NameNode可以接管共享存储,实现快速的故障转移。
- **远程协调法**:在这种配置中,通过一个远程协调服务(如ZooKeeper)来实现NameNode之间的状态同步。任何时候只有一个NameNode处于活跃状态,而另一个则作为热备,当活跃NameNode失效时,热备节点会立即接管服务。
高可用配置的实现需要在`hdfs-site.xml`中进行相应的配置,具体包括启用高可用、设置ZooKeeper的连接信息、指定共享存储的位置等。
### 2.1.2 DataNode的故障转移与数据复制
DataNode在HDFS集群中负责存储实际的数据块。为了保证数据的高可用,DataNode同样需要有故障转移的机制,并且要保证数据块的多个副本均匀分布在整个集群中。
DataNode故障转移主要依赖于其心跳机制。DataNode会定期向NameNode发送心跳包,如果超过设定的阈值没有收到心跳,NameNode会将此DataNode标记为宕机,并触发数据块的重新复制过程。
数据复制的策略通常由`dfs.replication`配置项来控制,默认值为3,意味着每个数据块会有三个副本。HDFS会自动处理副本的创建与删除,以确保每个数据块的副本数符合预设值。
```xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 其他配置项 -->
</configuration>
```
## 2.2 定期的数据备份策略
除了实时的高可用性机制,定期的备份策略也是保护数据免受意外损失的有效手段。HDFS提供了包括快照管理和使用工作流自动化备份的策略。
### 2.2.1 快照的创建与管理
快照是HDFS的一个功能,允许用户在任意时刻复制目录的状态。与传统的备份方法相比,快照提供了数据状态的瞬时备份,而不必复制整个数据集,从而大幅提高了备份效率。
创建和管理HDFS快照涉及以下步骤:
1. 启用命名空间的快照功能。
2. 创建快照点。
3. 恢复快照数据(如需要)。
4. 删除不再需要的快照。
```bash
# 启用快照功能
hdfs dfsadmin -allowSnapshot /path/to/directory
# 创建快照点
hdfs dfs -createSnapshot /path/to/directory snapshot_name
# 恢复快照数据
hdfs dfs -restoreSnapshot /path/to/directory snapshot_name
# 删除快照
hdfs dfs -deleteSnapshot /path/to/directory snapshot_name
```
### 2.2.2 使用Oozie工作流进行周期性备份
Oozie是Apache Hadoop的一个子项目,用于管理Hadoop作业的工作流。通过配置Oozie工作流,可以周期性地执行备份操作,并且可以轻松集成其他Hadoop生态系统组件,如Hive、Pig等。
Oozie工作流通常由一个DAG(有向无环图)定义,这个图指定了各个操作的依赖关系以及执行顺序。备份操作可以通过编写一个shell脚本,然后在Oozie中调用这个脚本的方式来实现。
```xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="backup-workflow">
<start to="backup-op"/>
<action name="backup-op">
<shell xmlns="uri:oozie:shell-action:0.1">
<exec>bash /path/to/backup/script.sh</exec>
</shell>
<ok to="end"/>
<error to="kill"/>
</action>
<kill name="kill">
<message>Backup failed, error message: ${wf:errorMessage(wf:lastErrorNode())}</message>
</kill>
<end name="end"/>
</workflow-app>
```
## 2.3 多副本存储策略的优化
HDFS默认采用三副本存储策略来保证数据的可靠性和可用性。然而,在不同场景下,可能需要对副本因子进行动态调整,以达到性能优化的目的。
### 2.3.1 理解HDFS的副本放置策略
HDFS设计了一套副本放置策略,旨在最大限度地减少数据丢失的风险,同时提供较好的读写性能。其核心规则包括:
- 第一个副本存放在上传文件的DataNode上,减少网络传输。
- 第二个副本放在与第一个副本不同的机架上,以应对机架失效。
- 剩余的副本均匀分布在其他机架的DataNode上。
### 2.3.2 动态调整副本因子以优化性能
在一些特定情况下,可能需要根据实际业务需求调整副本因子,比如读写操作频繁的文

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Hadoop快照性能基准测试:不同策略的全面评估报告

# 1. Hadoop快照技术概述
随着大数据时代的到来,Hadoop已经成为了处理海量数据的首选技术之一。而在Hadoop的众多特性中,快照技术是一项非常重要的功能,它为数据备份、恢复、迁移和数据管理提供了便利。
## 1.1 快照技术的重要性
Hadoop快照技术提供了一种方便、高效的方式来捕获HDFS(Hadoop Distributed File System)文件系统
系统不停机的秘诀:Hadoop NameNode容错机制深入剖析
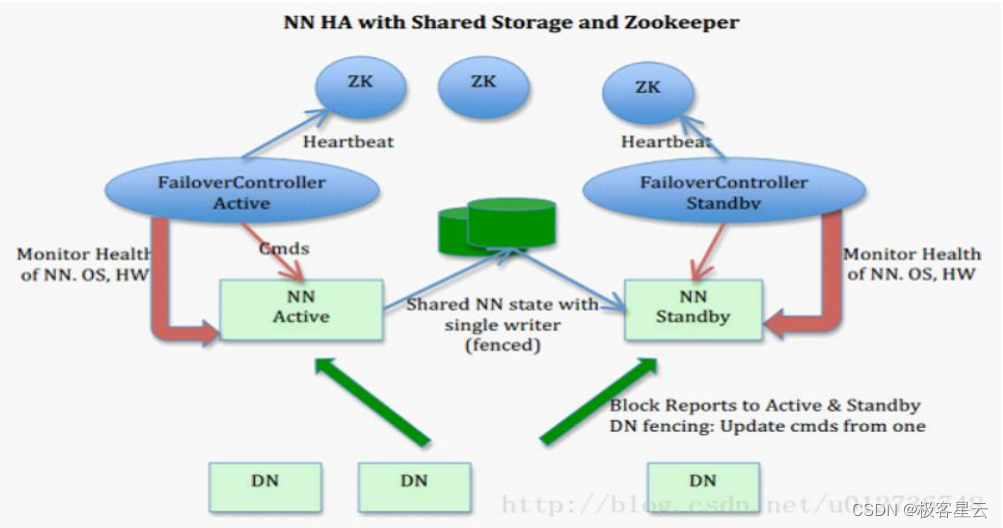
# 1. Hadoop NameNode容错机制概述
在分布式存储系统中,容错能力是至关重要的特性。在Hadoop的分布式文件系统(HDFS)中,NameNode节点作为元数据管理的中心点,其稳定性直接影响整个集群的服务可用性。为了保障服务的连续性,Hadoop设计了一套复杂的容错机制,以应对硬件故障、网络中断等潜在问题。本章将对Hadoop NameNode的容错机制进行概述,为理解其细节
【HDFS版本升级攻略】:旧版本到新版本的平滑迁移,避免升级中的写入问题
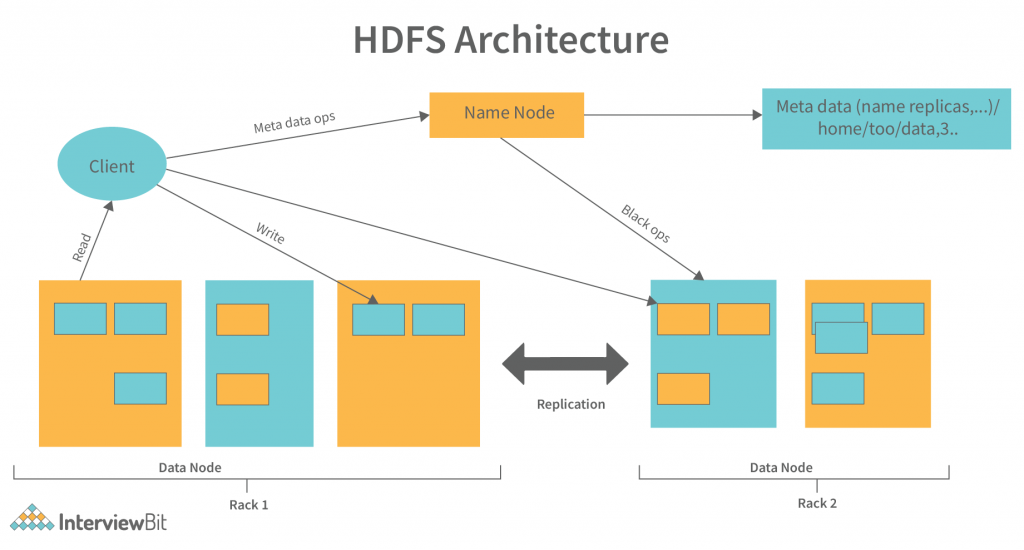
# 1. HDFS版本升级概述
Hadoop分布式文件系统(HDFS)作为大数据处理的核心组件,其版本升级是确保系统稳定、安全和性能优化的重要过程。升级可以引入新的特性,提高系统的容错能力、扩展性和效率。在开始升级之前,了解HDFS的工作原理、版本演进以及升级的潜在风险是至关重要的。本章将概述HDFS版本升级的基本概念和重要性,并
Hadoop资源管理与数据块大小:YARN交互的深入剖析
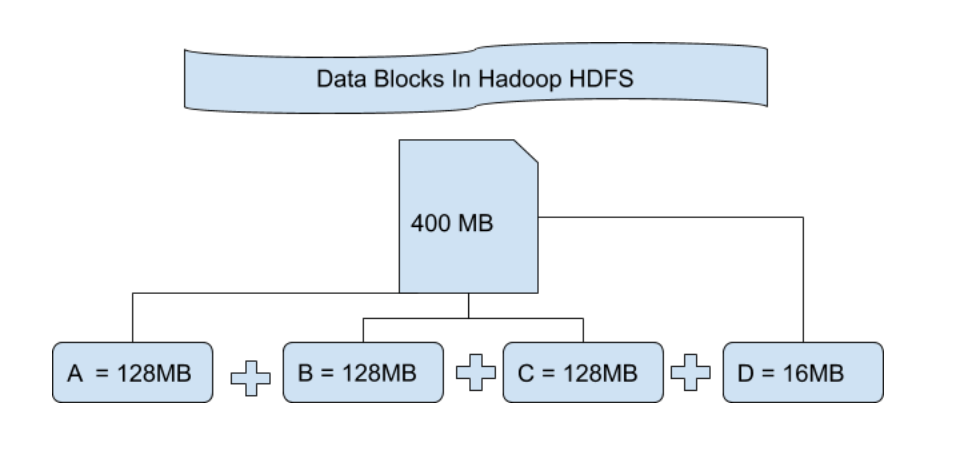
# 1. Hadoop资源管理概述
在大数据的生态系统中,Hadoop作为开源框架的核心,提供了高度可扩展的存储和处理能力。Hadoop的资源管理是保证大数据处理性能与效率的关键技术之一。本章旨在概述Hadoop的资源管理机制,为深入分析YARN架构及其核心组件打下基础。我们将从资源管理的角度探讨Hadoop的工作原理,涵盖资源的分配、调度、监控以及优化策略,为读者提供一个全
企业定制方案:HDFS数据安全策略设计全攻略

# 1. HDFS数据安全概述
## 1.1 数据安全的重要性
在大数据时代,数据安全的重要性日益凸显。Hadoop分布式文件系统(HDFS)作为处理海量数据的核心组件,其数据安全问题尤为关键。本章旨在简述HDFS数据安全的基本概念和重要性,为读者揭开HDFS数据安全之旅的序幕。
## 1.2 HDFS面临的威胁
HDFS存储的数据量巨大且类型多样,面临的威胁也具有多样性和复杂性。从数据泄露到未授
HDFS写入数据IO异常:权威故障排查与解决方案指南

# 1. HDFS基础知识概述
## Hadoop分布式文件系统(HDFS)简介
Hadoop分布式文件系统(HDFS)是Hadoop框架中的核心组件之一,它设计用来存储大量数据集的可靠存储解决方案。作为一个分布式存储系统,HDFS具备高容错性和流数据访问模式,使其非常适合于大规模数据集处理的场景。
## HDFS的优势与应用场景
HDFS的优
数据同步的守护者:HDFS DataNode与NameNode通信机制解析
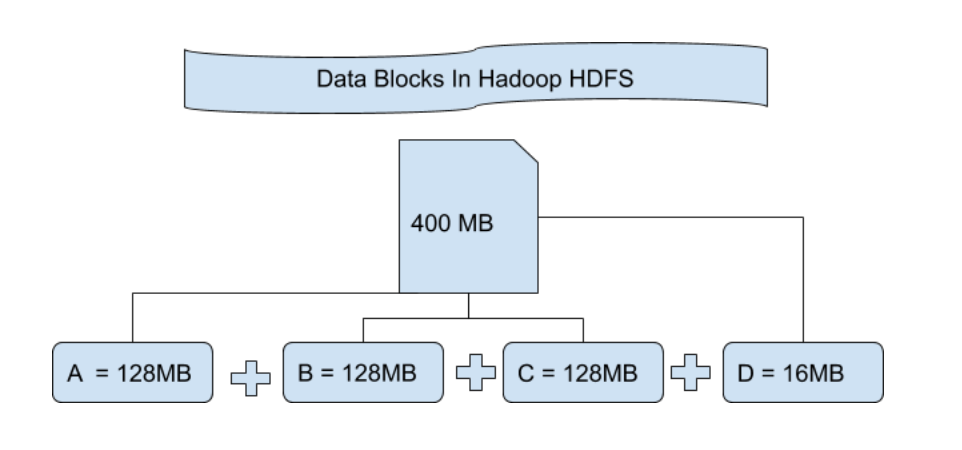
# 1. HDFS架构与组件概览
## HDFS基本概念
Hadoop分布式文件系统(HDFS)是Hadoop的核心组件之一,旨在存储大量数据并提供高吞吐量访问。它设计用来运行在普通的硬件上,并且能够提供容错能力。
## HDFS架构组件
- **NameNode**: 是HDFS的主服务器,负责管理文件系统的命名空间以及客户端对文件的访问。它记录了文
数据完整性校验:Hadoop NameNode文件系统检查的全面流程
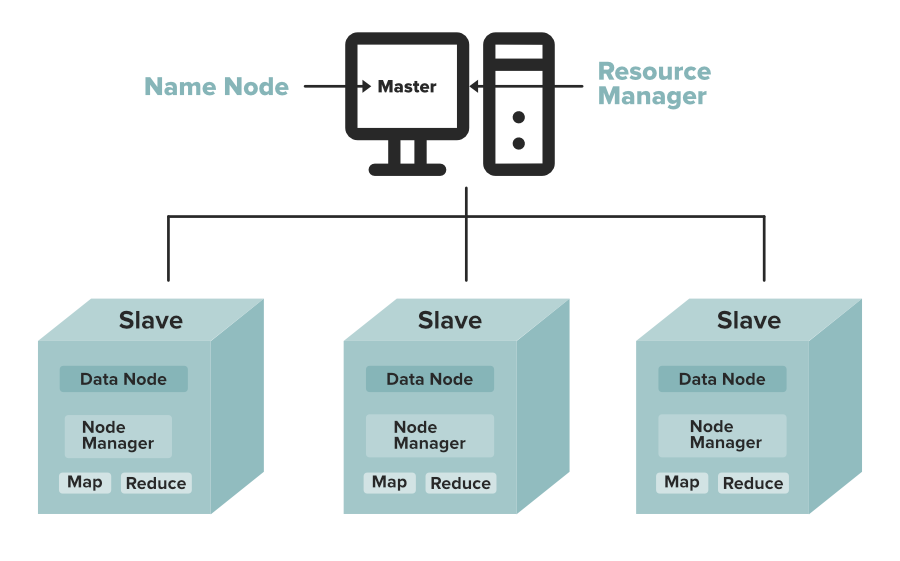
# 1. Hadoop NameNode数据完整性概述
Hadoop作为一个流行的开源大数据处理框架,其核心组件NameNode负责管理文件系统的命名空间以及维护集群中数据块的映射。数据完整性是Hadoop稳定运行的基础,确保数据在存储和处理过程中的准确性与一致性。
在本章节中,我们将对Hadoop NameNode的数据完
【Hadoop 2.0快照与数据迁移】:策略与最佳实践指南
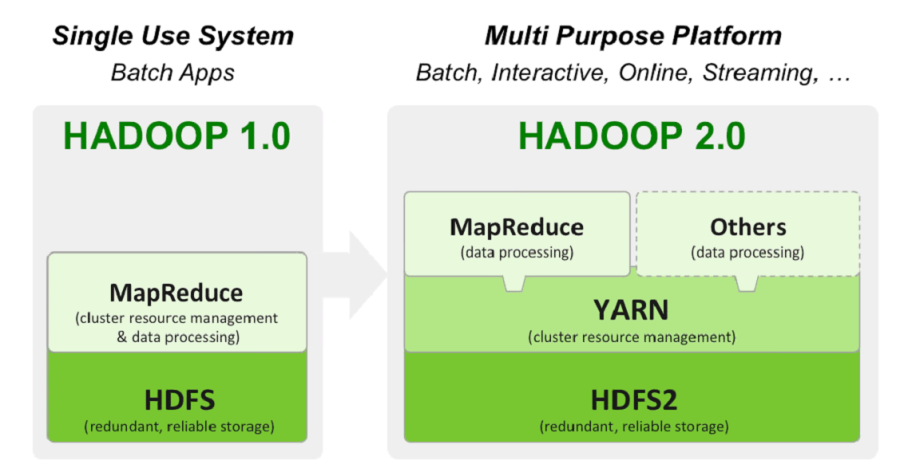
# 1. Hadoop 2.0快照与数据迁移概述
## 1.1 为什么关注Hadoop 2.0快照与数据迁移
在大数据生态系统中,Hadoop 2.0作为一个稳定且成熟的解决方案,其快照与数据迁移的能力对保证数据安全和系统可靠性至关重要。快照功能为数据备份提供了高效且低干扰的解决方案,而数据迁移则支持数据在不同集群或云环境间的移动。随着数据量的不
HDFS数据本地化:优化datanode以减少网络开销

# 1. HDFS数据本地化的基础概念
## 1.1 数据本地化原理
在分布式存储系统中,数据本地化是指尽量将计算任务分配到存储相关数据的节点上,以此减少数据在网络中的传输,从而提升整体系统的性能和效率。Hadoop的分布式文件系统HDFS采用数据本地化技术,旨在优化数据处理速度,特别是在处理大量数据时,可以显著减少延迟,提高计算速度。
## 1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )