揭秘MATLAB数值积分误差:掌握误差来源,优化计算策略
发布时间: 2024-05-23 22:07:16 阅读量: 296 订阅数: 47 

# 1. 数值积分简介**
数值积分是一种近似计算积分值的方法,当解析求解积分困难或不可能时,它在科学计算和数据分析中发挥着至关重要的作用。数值积分的基本原理是将积分区间划分为子区间,然后在每个子区间上使用特定的积分规则近似计算积分值。常见的积分规则包括梯形法则、辛普森法则和高斯求积法。
# 2. 误差来源
### 2.1 截断误差
截断误差是数值积分方法中固有的误差,它是由对被积函数的泰勒展开式进行截断造成的。
#### 2.1.1 泰勒展开式
对于一个在区间 `[a, b]` 上连续可微的函数 `f(x)`,其在点 `x = c` 处的泰勒展开式为:
```
f(x) = f(c) + f'(c)(x - c) + f''(c)(x - c)^2/2! + ... + f^(n)(c)(x - c)^n/n! + R_n(x)
```
其中,`R_n(x)` 是余项,表示展开式中省略的高阶导数项。
#### 2.1.2 梯形法则和辛普森法则的误差估计
**梯形法则**的截断误差估计为:
```
|E_T| <= (b - a)^3 * max(|f'''(x)|) / 12 * n^2
```
**辛普森法则**的截断误差估计为:
```
|E_S| <= (b - a)^5 * max(|f^{(4)}(x)|) / 180 * n^4
```
其中,`n` 是子区间数。
### 2.2 舍入误差
舍入误差是由于计算机使用浮点数表示实数时产生的误差。
#### 2.2.1 浮点数表示
浮点数使用科学计数法表示实数,即:
```
x = m * 2^e
```
其中,`m` 是尾数,`e` 是指数。尾数和指数都使用有限位数表示,因此浮点数只能表示有限精度的实数。
#### 2.2.2 舍入误差的影响
舍入误差会导致数值积分结果与精确值之间的差异。例如,对于函数 `f(x) = x^2`,使用梯形法则在区间 `[0, 1]` 上进行积分,如果使用单精度浮点数,则结果为 `0.33333334`,与精确值 `1/3` 存在误差。
### 2.3 其他误差来源
除了截断误差和舍入误差外,数值积分还可能受到其他误差来源的影响,包括:
#### 2.3.1 函数奇异性
如果被积函数在积分区间内存在奇异点(例如,分母为零),则数值积分方法可能会产生较大的误差。
#### 2.3.2 数据噪声
如果被积函数的数据存在噪声,则数值积分结果也会受到影响。
# 3.1 积分算法选择
### 3.1.1 梯形法则
梯形法则是一种基本的数值积分方法,它将积分区间等分为 n 个子区间,然后用每个子区间的梯形面积来近似积分值。梯形法则的公式为:
```python
def trapezoidal_rule(f, a, b, n):
"""
梯形法则计算积分
参数:
f: 被积函数
a: 积分下限
b: 积分上限
n: 子区间个数
返回:
积分值
"""
h = (b - a) / n
sum = 0
for i in range(1, n):
sum += f(a + i * h)
return h * (0.5 * f(a) + sum + 0.5 * f(b))
```
**逻辑分析:**
1. 计算子区间的宽度 `h`。
2. 初始化累加器 `sum` 为 0。
3. 循环遍历子区间,计算每个子区间的梯形面积并累加到 `sum` 中。
4. 返回积分值,其中包括端点处的梯形面积和中间子区间的梯形面积。
**参数说明:**
* `f`: 被积函数
* `a`: 积分下限
* `b`: 积分上限
* `n`: 子区间个数
### 3.1.2 辛普森法则
辛普森法则是一种比梯形法则更精确的数值积分方法,它使用抛物线来近似每个子区间的积分值。辛普森法则的公式为:
```python
def simpson_rule(f, a, b, n):
"""
辛普森法则计算积分
参数:
f: 被积函数
a: 积分下限
b: 积分上限
n: 子区间个数
返回:
积分值
"""
h = (b - a) / n
sum_even = 0
sum_odd = 0
for i in range(1, n, 2):
sum_even += f(a + i * h)
for i in range(2, n, 2):
sum_odd += f(a + i * h)
return h / 3 * (f(a) + 4 * sum_even + 2 * sum_odd + f(b))
```
**逻辑分析:**
1. 计算子区间的宽度 `h`。
2. 初始化偶数子区间和 `sum_even` 和奇数子区间和 `sum_odd` 为 0。
3. 循环遍历偶数子区间,计算每个偶数子区间的函数值并累加到 `sum_even` 中。
4. 循环遍历奇数子区间,计算每个奇数子区间的函数值并累加到 `sum_odd` 中。
5. 返回积分值,其中包括端点处的函数值和偶数、奇数子区间的函数值。
**参数说明:**
* `f`: 被积函数
* `a`: 积分下限
* `b`: 积分上限
* `n`: 子区间个数
# 4. 实践应用
### 4.1 数值积分在科学计算中的应用
数值积分在科学计算中有着广泛的应用,尤其是在物理学和工程学领域。
#### 4.1.1 物理学中的积分
在物理学中,数值积分被用于求解各种微分方程,例如:
- **牛顿第二定律:**
```
F = ma
```
其中,F 为力,m 为质量,a 为加速度。通过对加速度 a 进行数值积分,可以得到速度和位移。
- **麦克斯韦方程组:**
```
∇ × E = -∂B/∂t
∇ × B = μ0(J + ε0∂E/∂t)
```
其中,E 为电场,B 为磁场,J 为电流密度,ε0 为真空介电常数,μ0 为真空磁导率。通过对麦克斯韦方程组进行数值积分,可以求解电磁场的分布。
#### 4.1.2 工程学中的积分
在工程学中,数值积分被用于求解各种工程问题,例如:
- **流体力学:**
```
ρv = const
```
其中,ρ 为流体的密度,v 为流体的速度。通过对速度 v 进行数值积分,可以得到流体的流量。
- **热传导:**
```
Q = kA(dT/dx)
```
其中,Q 为热量,k 为热导率,A 为传热面积,dT/dx 为温度梯度。通过对温度梯度 dT/dx 进行数值积分,可以得到热量 Q。
### 4.2 数值积分在数据分析中的应用
数值积分在数据分析中也有着重要的应用,尤其是用于概率和统计分析。
#### 4.2.1 概率密度函数的积分
概率密度函数 f(x) 的积分表示事件发生的概率。通过对概率密度函数 f(x) 进行数值积分,可以求得事件发生的概率。
#### 4.2.2 累积分布函数的积分
累积分布函数 F(x) 的积分表示事件发生概率的累积和。通过对累积分布函数 F(x) 进行数值积分,可以求得事件发生概率的累积和。
### 4.3 数值积分的应用实例
**例 1:计算抛物线下的面积**
```python
import numpy as np
# 定义抛物线函数
def f(x):
return x**2
# 积分区间
a = 0
b = 1
# 使用梯形法则进行数值积分
n = 100 # 积分步长
h = (b - a) / n
integral = 0
for i in range(1, n):
integral += f(a + i * h)
integral *= h
print("抛物线下的面积:", integral)
```
**例 2:计算正态分布的概率**
```python
import numpy as np
# 定义正态分布的概率密度函数
def f(x):
return 1 / (np.sqrt(2 * np.pi) * sigma) * np.exp(-(x - mu)**2 / (2 * sigma**2))
# 积分区间
a = -3
b = 3
# 正态分布的参数
mu = 0
sigma = 1
# 使用辛普森法则进行数值积分
n = 100 # 积分步长
h = (b - a) / n
integral = 0
for i in range(1, n, 2):
integral += f(a + i * h)
for i in range(2, n, 2):
integral += 2 * f(a + i * h)
integral *= h / 3
print("正态分布的概率:", integral)
```
# 5. 高级技巧
### 5.1 蒙特卡罗积分
#### 5.1.1 原理和算法
蒙特卡罗积分是一种基于随机抽样的数值积分方法。其基本思想是:通过生成大量随机样本点,并计算每个样本点的函数值,然后利用这些函数值的平均值来近似积分值。
蒙特卡罗积分算法步骤如下:
1. 在积分域内随机生成 $N$ 个样本点 $x_1, x_2, ..., x_N$。
2. 计算每个样本点的函数值 $f(x_1), f(x_2), ..., f(x_N)$。
3. 计算积分近似值:
$$I \approx \frac{1}{N} \sum_{i=1}^N f(x_i)$$
#### 5.1.2 优缺点
**优点:**
* 对积分域的形状和函数的连续性没有要求。
* 适用于高维积分问题。
**缺点:**
* 收敛速度较慢,需要大量的样本点。
* 对于具有尖峰或奇异性的函数,精度较差。
### 5.2 有限元法
#### 5.2.1 原理和算法
有限元法是一种将积分域划分为有限个小单元的数值积分方法。每个小单元内,函数被近似为一个简单的多项式。通过求解小单元内的积分,可以得到整个积分域的积分近似值。
有限元法算法步骤如下:
1. 将积分域划分为 $N$ 个有限元。
2. 在每个有限元内,选择一个形状函数 $N_i(x)$,使得:
$$f(x) \approx \sum_{i=1}^n N_i(x) f_i$$
其中,$f_i$ 为有限元内的函数值。
3. 求解每个有限元内的积分:
$$I_i = \int_{element_i} f(x) dx \approx \int_{element_i} \sum_{i=1}^n N_i(x) f_i dx$$
4. 计算整个积分域的积分近似值:
$$I \approx \sum_{i=1}^N I_i$$
#### 5.2.2 在数值积分中的应用
有限元法在数值积分中的应用主要体现在以下方面:
* 对于复杂积分域的积分问题,有限元法可以将积分域划分为多个小单元,从而简化积分计算。
* 对于具有奇异性的函数积分问题,有限元法可以通过局部精细划分来提高积分精度。
# 6.1 数值积分误差的理解和优化
数值积分误差的理解和优化是数值积分领域的关键问题。通过深入理解误差来源,我们可以采取适当的措施来优化积分算法,从而提高计算精度和效率。
**误差来源的理解**
数值积分误差主要来源于截断误差、舍入误差和其他误差来源。截断误差是由于积分算法在近似积分值时舍弃了高阶导数项造成的,而舍入误差则是由于计算机浮点数表示的有限精度造成的。其他误差来源还包括函数奇异性和数据噪声。
**误差优化的策略**
为了优化数值积分误差,我们可以采取以下策略:
* **选择合适的积分算法:**根据积分函数的性质和精度要求,选择合适的积分算法,如梯形法则、辛普森法则或高斯求积法。
* **自适应积分:**使用自适应积分算法,根据误差估计动态调整积分步长,以平衡精度和效率。
* **误差控制:**设定误差容限,并使用误差估计和自适应步长来控制积分误差。
**具体优化步骤**
以下是一些具体的优化步骤:
* **估计截断误差:**使用泰勒展开式或其他方法估计积分算法的截断误差。
* **评估舍入误差:**了解计算机浮点数表示的精度限制,并评估其对积分结果的影响。
* **控制其他误差来源:**通过适当的函数变换或数据预处理,减轻函数奇异性或数据噪声的影响。
* **选择自适应积分算法:**根据误差估计和精度要求,选择合适的自适应积分算法,如 Romberg 积分或 Clenshaw-Curtis 积分。
* **设定误差容限:**根据应用场景和精度要求,设定合理的误差容限。
通过遵循这些优化策略,我们可以显著提高数值积分的精度和效率,为科学计算、数据分析等领域提供可靠的积分结果。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MATLAB 数值积分的全面指南!本专栏深入探讨了数值积分的方方面面,从入门指南到高级技巧和应用。您将了解积分误差的来源并优化计算策略,掌握各种算法的优缺点,并探索 MATLAB 数值积分在工程、图像处理、机器学习、金融建模、科学计算、物理模拟、优化问题、数据分析、控制系统、计算机图形学、生物信息学、医学成像、材料科学和航空航天等领域的广泛应用。通过本专栏,您将掌握数值积分的强大功能,并将其应用到各种现实世界问题中,从理论到实践,从微积分到数据科学,从科学发现到工程创新。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
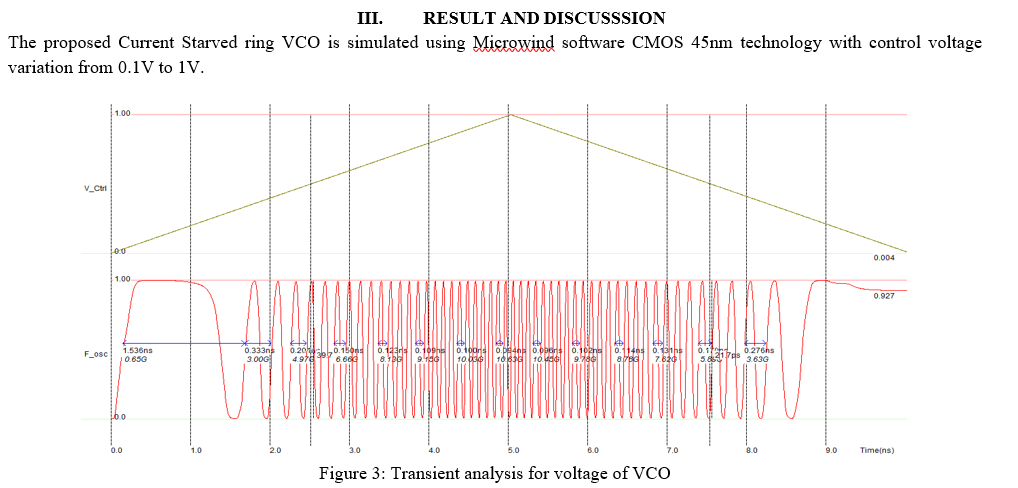
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
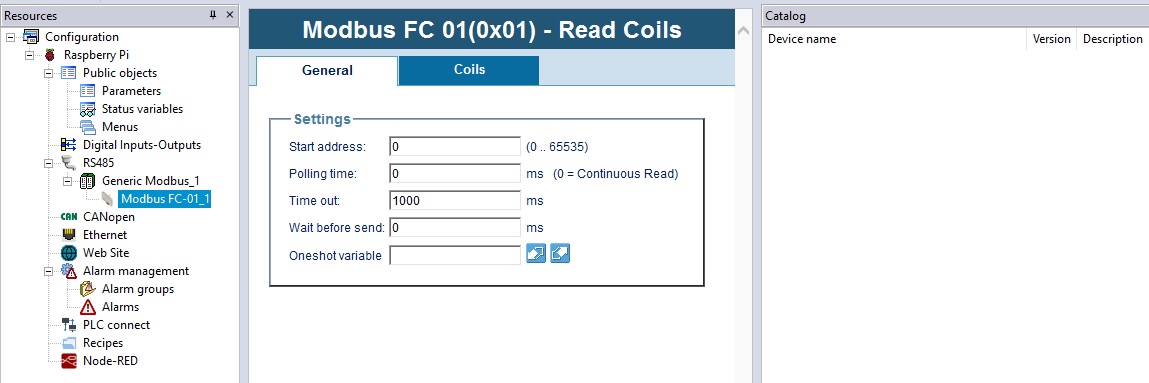
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )