AQS内部实现:FIFO队列
发布时间: 2024-01-10 13:51:09 阅读量: 35 订阅数: 33 

(FIFO)串口接收和发送.zip_FIFO 串口 接收_fsmc和fifo_stm32 fifo队列_stm32 实现队列_串
# 1. 介绍AQS(AbstractQueuedSynchronizer)
## 1.1 AQS的概述
AQS(AbstractQueuedSynchronizer)是Java并发库中提供的一个用于构建锁和同步器的基础框架。AQS通过使用一个FIFO(先进先出)队列来管理等待获取资源的线程,并在资源可用时选择一个或多个线程去获取资源。AQS提供了一些方法,允许子类实现对资源的独占访问(如ReentrantLock)或共享访问(如CountDownLatch)。
## 1.2 AQS的作用和使用场景
AQS是Java并发编程中非常重要的一个组件,它提供了一种底层的机制,用于控制多个线程之间对共享资源的访问。AQS的作用主要有两个方面:
- 提供了一种可靠的线程阻塞和唤醒机制,使得线程能够安全地等待和获取资源。
- 允许开发者通过继承AQS的方式来实现自定义的同步器,从而构建出不同种类的锁和同步器。
AQS的使用场景非常广泛,包括但不限于以下几个方面:
- 实现各种不同类型的锁,如独占锁(ReentrantLock)、共享锁(Semaphore)、读写锁(ReentrantReadWriteLock)等。
- 实现各种同步器,如倒计时器(CountDownLatch)、屏障(CyclicBarrier)、信号量(Semaphore)等。
- 实现线程安全的数据结构,如阻塞队列(BlockingQueue)等。
- 实现一些并发算法,如线程池、并发集合等。
通过使用AQS,开发者可以方便地实现线程的同步和互斥,提高应用程序的并发性能和可靠性。接下来,我们将详细介绍AQS内部的实现原理。
# 2. AQS内部实现的基本原理
在上一章节中,我们介绍了AQS的概述和使用场景。本章节将深入探讨AQS内部的基本原理,包括其数据结构和核心方法。
### 2.1 AQS的数据结构
AQS内部使用一种名为`Node`的数据结构来表示等待线程。每个`Node`对象都包含一个等待状态`waitStatus`和一个指向前驱节点和后继节点的指针。这样形成了一个双向链表的结构,用于维护等待队列。
此外,AQS还维护了一个表示当前拥有资源的线程的指针,以及一个表示同步状态的变量。
### 2.2 AQS的核心方法
AQS的核心方法主要包括以下几个:
- `acquire(int arg)`:尝试获取资源,如果获取失败,则将当前线程加入等待队列,并使线程进入阻塞状态。
- `release(int arg)`:释放资源,并唤醒等待队列中的下一个线程。
- `tryAcquire(int arg)`:尝试直接获取资源,成功则返回true,失败则返回false。
- `tryRelease(int arg)`:尝试直接释放资源,成功则返回true,失败则返回false。
- `tryAcquireShared(int arg)`:尝试获取共享资源,成功则返回true,失败则返回false。
- `tryReleaseShared(int arg)`:尝试释放共享资源,成功则返回true,失败则返回false。
这些方法的实现是AQS实现同步的核心。它们通过操作等待队列和同步状态来实现线程的等待和唤醒,从而实现资源的获取和释放。
以上是AQS内部实现的基本原理的简要介绍。在接下来的章节中,我们将继续探讨AQS内部实现的FIFO队列,并介绍如何使用它。
# 3. 什么是FIFO队列
FIFO队列是指先进先出队列(First-In-First-Out Queue),简称FIFO队列。在FIFO队列中,首先被插入的元素最先被删除,而最后被插入的元素最后被删除,元素的删除顺序和插入顺序完全一致。FIFO队列在计算机科学领域有广泛的应用。
#### 3.1 FIFO队列的定义和特性
FIFO队列是一种常见的线性数据结构,它具有以下特性:
- 队列中的元素遵循先进先出原则,即首先被插入的元素最先被删除,最后被插入的元素最后被删除。
- 队列只允许在队尾进行插入操作(Enqueue),在队首进行删除操作(Dequeue)。
- 队列的长度可以动态变化,可以根据实际需求进行扩展或缩小。
- 队列的大小可以有限制,当队列已满时,继续插入元素将导致队列溢出错误。
- 队列的查询操作(Peek)可以查看队首元素的值,但不会删除该元素。
#### 3.2 FIFO队列的应用场景
FIFO队列在各种场景中都有广泛应用,例如:
- 任务调度:多个任务按照先后顺序排队执行,保证公平性。
- 缓冲区管理:处理多个生产者和消费者之间的数据传输,避免数据丢失。
- 线程池:控制线程的执行顺序,确保任务按照提交的先后顺序执行。
- IO操作处理:处理输入输出请求时,保证请求的顺序执行。
FIFO队列的应用场景非常广泛,因为它能够有效地管理和控制多个操作的执行顺序,保证数据的有序处理。
下面将介绍AQS内部实现的FIFO队列,以及它在多线程编程中的使用。
# 4. AQS内部实现的FIFO队列
在本章中,我们将深入探讨AQS内部实现的FIFO队列,了解其数据结构和实现原理。深入理解AQS内部实现的FIFO队列将有助于我们更好地使用和理解AQS。
#### 4.1 FIFO队列的数据结构
AQS内部实现的FIFO队列采用双向链表作为其数据结构。每个节点都包含了指向前驱节点和后继节点的引用,从而构成一个链表结构。这种双向链表的特性使得在队列头部和尾部的操作都能在O(1)的时间复杂度内完成,非常适合用于构建FIFO队列。
```java
// Java双向链表节点定义
static final class Node {
volatile Node prev;
volatile Node next;
volatile Thread thread;
}
```
#### 4.2 FIFO队列的实现原理
AQS内部实现的FIFO队列主要依靠CAS操作(Compare And Swap)来实现节点的入队和出队操作。通过CAS操作,可以确保在并发情况下仍能保持队列的FIFO特性,并且避免了使用锁造成的性能损耗。
```java
// Java中通过CAS操作实现入队
private boolean casTail(Node expect, Node update) {
return UNSAFE.compareAndSwapObject(this, tailOffset, expect, update);
}
```
通过了解AQS内部实现的FIFO队列的数据结构和实现原理,我们可以更好地理解AQS的内部工作机制,为我们使用AQS提供了更多的思路和方法。
以上是文章的第四章节内容,如需了解其他章节内容,请告诉我。
# 5. 如何使用AQS内部实现的FIFO队列
AQS内部实现的FIFO队列可以在多线程并发场景下提供可靠的队列操作,下面我们将介绍如何使用AQS内部实现的FIFO队列,并给出一个生产者-消费者模型的示例。
#### 5.1 使用示例:生产者-消费者模型
```java
// Java示例代码
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
class MyQueue {
private final AbstractQueuedSynchronizer sync = new AbstractQueuedSynchronizer() {
@Override
protected boolean tryAcquire(int ignore) {
// 实现自定义的获取逻辑
return // 自定义的获取逻辑
}
@Override
protected boolean tryRelease(int ignore) {
// 实现自定义的释放逻辑
return // 自定义的释放逻辑
}
};
public void produce(Object item) {
// 生产者生产物品并加入队列
sync.acquire(1);
// 将物品加入队列
// ...
sync.release(1);
}
public Object consume() {
// 消费者从队列取出物品并消费
sync.acquire(1);
// 从队列取出物品
// ...
sync.release(1);
return // 物品
}
}
```
#### 5.2 使用AQS内部实现的FIFO队列的注意事项
- 在使用AQS内部实现的FIFO队列时,需要实现自定义的获取逻辑和释放逻辑,以确保队列操作的正确性。
- 当使用AQS内部实现的FIFO队列时,需要注意对共享资源的访问控制,避免出现死锁等问题。
通过以上示例,我们可以看到如何使用AQS内部实现的FIFO队列,并且需要注意的事项。接下来,我们将总结AQS内部实现的FIFO队列的优缺点。
# 6. 总结
### 6.1 AQS内部实现的FIFO队列的优缺点
AQS内部实现的FIFO队列有以下优点和缺点:
优点:
- 实现简单、高效:AQS内部实现的FIFO队列使用基于链表的数据结构,在插入和删除元素时具有良好的性能。
- 支持公平性:AQS内部实现的FIFO队列可以保证任务的执行按照先入先出的顺序进行,从而实现公平调度。
缺点:
- 不支持优先级:AQS内部实现的FIFO队列不支持优先级排序,所有任务都是按照先入先出的原则进行调度。
- 不支持动态扩容:AQS内部实现的FIFO队列的长度是固定的,不支持动态扩容,一旦达到队列的最大长度,后续的任务将无法添加。
### 6.2 对AQS内部实现的FIFO队列的改进和扩展的展望
尽管AQS内部实现的FIFO队列已经具备了一定的功能和性能,但仍然有一些改进和扩展的空间:
改进:
- 支持优先级调度:可以在AQS内部实现的FIFO队列的基础上引入优先级的概念,实现根据任务优先级进行调度。
- 支持动态扩容:可以对AQS内部实现的FIFO队列进行改造,支持在队列满时自动扩容,以适应变化的任务量。
扩展:
- 支持其他数据结构:可以基于AQS的思想,实现其他类型的队列,如双向队列、循环队列等,以满足更多场景的需求。
- 支持并发操作:可以将AQS内部实现的FIFO队列扩展为支持并发操作的队列,以提高多线程环境下的性能。
通过不断改进和扩展,AQS内部实现的FIFO队列可以更好地满足不同场景下的需求,提供更加丰富和灵活的功能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏从Java并发编程的角度,围绕AQS(AbstractQueuedSynchronizer)源码展开,深入探讨了其内部实现原理及相关类库的源码解析。首先介绍了AQS的概念及作用,从理解AQS的角度出发,分析了其内部实现中涉及的原子操作、FIFO队列、状态管理等核心内容,为读者打下坚实的理论基础。接着,通过对ReentrantLock、ReentrantReadWriteLock、Semaphore、CountDownLatch、CyclicBarrier、FutureTask等类库源码的解析,进一步深入讨论了AQS的具体应用场景及实现细节。同时,还对线程池原理、ConcurrentSkipListMap、ForkJoinPool、LockSupport、AtomicInteger、StampedLock、Phaser等相关主题进行了源码解析,为读者呈现了一幅全面而深入的并发编程知识图景。通过本专栏的学习,读者将深刻理解Java并发编程中AQS的核心作用与原理,从而能够更加灵活地应用于实际开发中,提高多线程编程水平。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
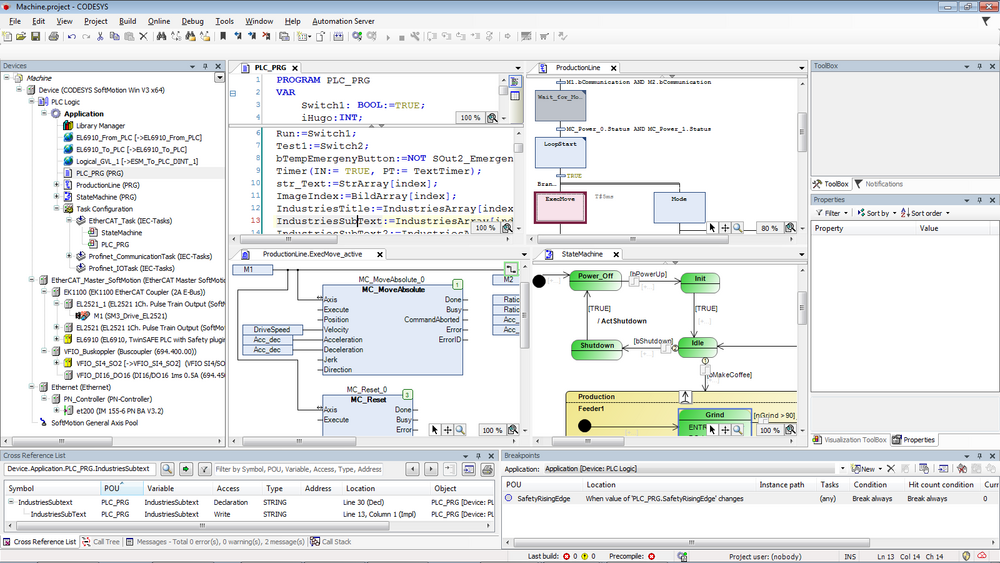
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
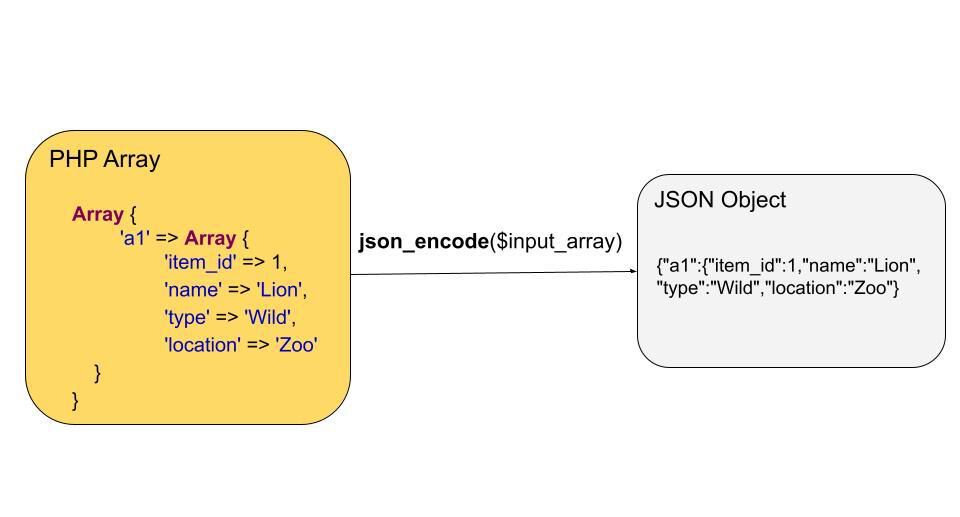
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
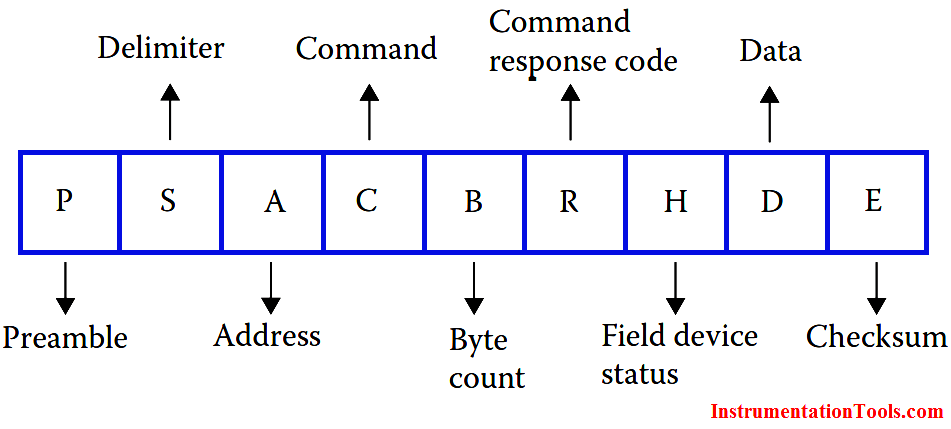
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )