网络安全威胁情报预警:识别和应对网络攻击
发布时间: 2024-07-21 07:20:17 阅读量: 47 订阅数: 23 

网络安全威胁情报TI标准分析研究.pdf
# 1. 网络安全威胁情报概述**
网络安全威胁情报是有关网络威胁和攻击者的信息,旨在帮助组织识别、预防和应对网络攻击。它提供有关威胁行为者、攻击技术、恶意软件和漏洞的实时信息,使组织能够做出明智的决策并实施有效的安全措施。
威胁情报收集和分析对于网络安全至关重要。它使组织能够了解当前的威胁格局,识别潜在的风险,并制定应对计划。通过利用威胁情报,组织可以提高其检测和响应网络攻击的能力,从而降低其安全风险。
威胁情报的类型包括内部威胁情报(例如日志分析和安全事件监控)和外部威胁情报(例如商业威胁情报服务和开源威胁情报社区)。组织应利用各种来源来收集和分析威胁情报,以获得对威胁格局的全面了解。
# 2. 威胁情报的识别和收集
威胁情报的识别和收集是网络安全威胁情报预警的关键步骤,它为后续的分析、评估、预警和响应提供了基础。威胁情报可以从内部和外部来源收集,每种来源都有其独特的优势和劣势。
### 2.1 内部威胁情报收集
内部威胁情报是指从组织内部收集的信息,包括日志、事件和安全监控数据。通过分析这些数据,组织可以识别和了解内部威胁,例如恶意软件感染、数据泄露或内部人员滥用权限。
#### 2.1.1 日志分析
日志文件记录了系统和应用程序的活动,是识别威胁的重要来源。通过分析日志,组织可以检测异常活动,例如未经授权的访问、可疑文件操作或网络攻击尝试。
```python
import re
# 打开日志文件
with open('system.log') as f:
# 逐行读取日志文件
for line in f:
# 匹配可疑活动模式
match = re.search(r'\[ERROR\] Unauthorized access attempt from IP: (\d+\.\d+\.\d+\.\d+)', line)
if match:
# 获取可疑 IP 地址
ip_address = match.group(1)
# 记录可疑活动
print(f'Detected unauthorized access attempt from {ip_address}')
```
#### 2.1.2 安全事件监控
安全事件监控系统(SEM)收集和分析来自各种来源的安全事件数据,例如防火墙、入侵检测系统和防病毒软件。通过监控这些事件,组织可以实时检测威胁并采取适当的响应措施。
```mermaid
sequenceDiagram
participant User
participant SEM
participant SIEM
User->SEM: Send security events
SEM->SIEM: Forward security events
SIEM: Analyze security
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏名为“网络”,深入探讨了网络管理的各个方面。它提供了一系列全面的文章,涵盖了从网络流量分析到网络自动化的各个主题。
通过网络流量分析,您可以监控、分析和优化网络流量,以确保网络的平稳运行。网络自动化秘籍提供了使用脚本和工具提高网络效率的实用技巧。网络延迟诊断与优化指导您解决网络延迟难题,而网络拥塞分析与解决则帮助您缓解网络拥塞,提高网络性能。
本专栏旨在为网络管理员提供全面的资源,帮助他们有效管理和优化其网络,从而提高网络性能和用户体验。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
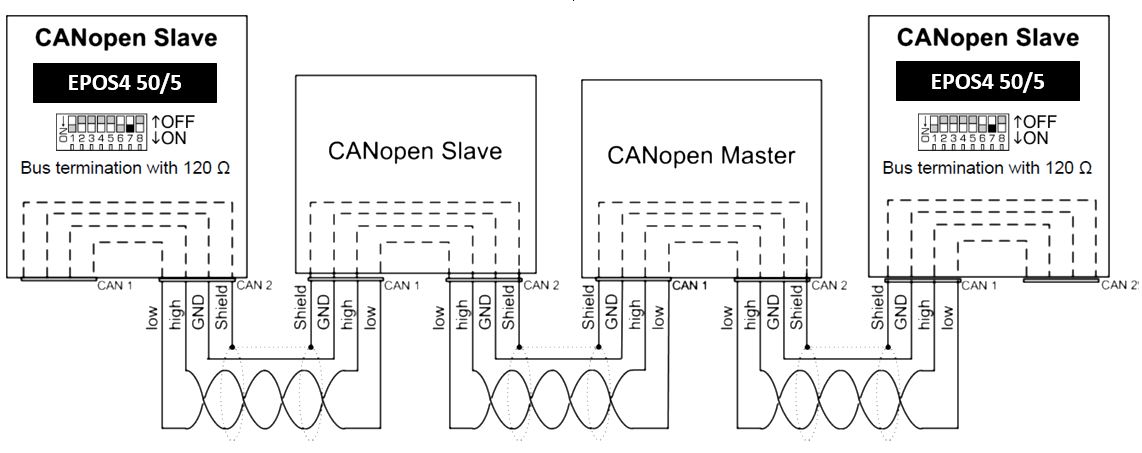
CANopen与Elmo协同工作:自动化系统集成的终极指南
# 摘要
本文综合介绍了CANopen协议和Elmo伺服驱动器的基础知识、集成和协同工作实践,以及高级应用案例研究。首先,概述了CANopen通信模型、消息对象字典、数据交换和同步机制,接着详细讲解了Elmo伺服驱动器的特点、配置优化和网络通信。文章深入探讨了CANopen与Elmo在系统集成、配置和故障诊断方面的协同工作,并通过案例研究,阐述了其在高级应用中的协同功能和性能调优。最后,展望了
【CAT021报文实战指南】:处理与生成,一步到位

# 摘要
CAT021报文作为特定领域内的重要通信协议,其结构和处理技术对于相关系统的信息交换至关重要。本文首先介绍了CAT021报文的基本概览和详细结构,包括报文头、数据字段和尾部的组成及其功能。接着,文章深入探讨了CAT021报文的生成技术,包括开发环境的搭建、编
【QoS终极指南】:7个步骤精通服务质量优化,提升网络性能!
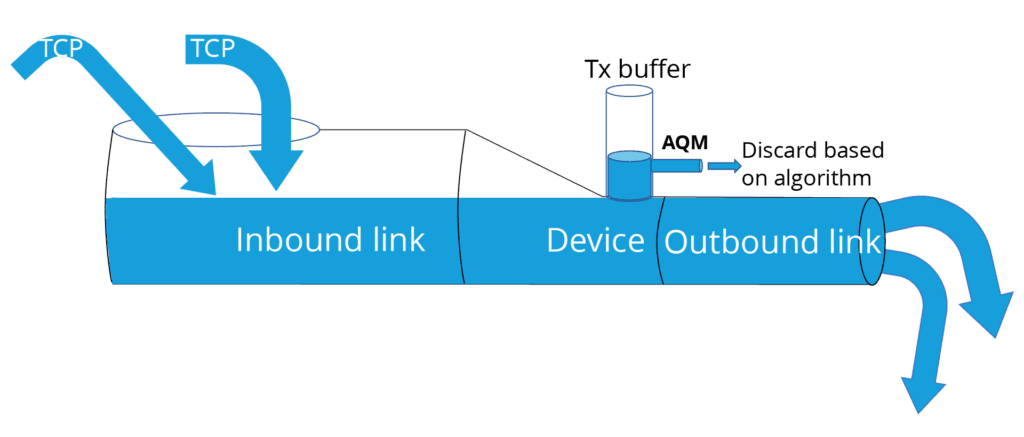
# 摘要
服务质量优化(QoS)是网络管理和性能保障的核心议题,对确保数据传输效率和用户体验至关重要。本文首先介绍了QoS的基础知识,包括其概念、重要性以及基本模型和原理。随后,文章详细探讨了流量分类、标记以及QoS策略的实施和验证方法。在实战技巧部分,本文提供了路由器和交换机上QoS配置的实战指导,包括VoIP和视频流量的优化技术。案例研究章节分析了QoS在不同环境下的部署和
【必备技能】:从零开始的E18-D80NK传感器与Arduino集成指南

# 摘要
本论文旨在介绍E18-D80NK传感器及其与Arduino硬件平台的集成应用。文章首先简要介绍E18-D80NK传感器的基本特性和工作原理,随后详细阐述Arduino硬件和编程环境,包括开发板种类、IDE安装使用、C/C++语言应用、数字和模拟输入输出操作。第三章深入探讨了传感器与Arduino硬件的集成,包括硬件接线、安全
ArcGIS空间数据分析秘籍:一步到位掌握经验半变异函数的精髓
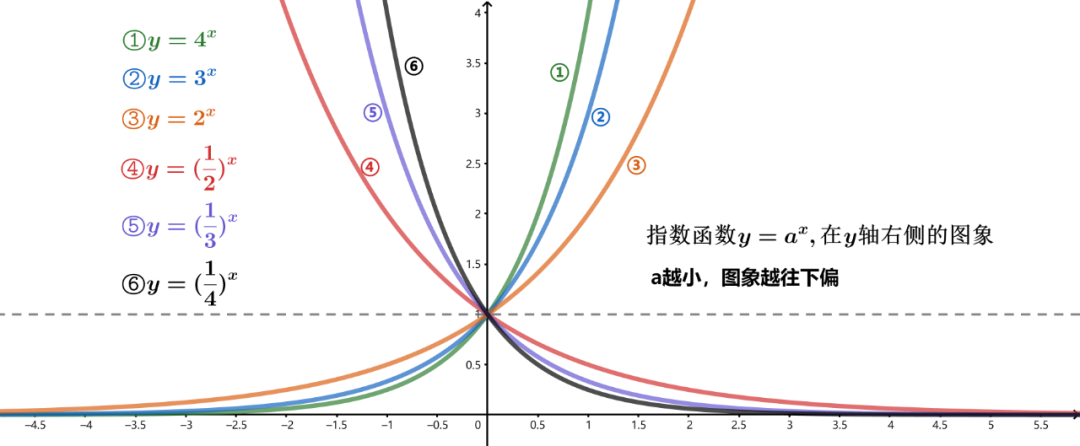
# 摘要
空间数据分析是地理信息系统(GIS)研究的关键组成部分,而半变异函数作为分析空间自相关性的核心工具,在多个领域得到广泛应用。本文首先介绍了空间数据分析与半变异函数的基本概念,深入探讨了其基础理论和绘图方法。随后,本文详细解读了ArcGIS空间分析工具在半变异函数分析中的应用,并通过实际案例展示了其在环境科学和土地资源管理中的实用性。文章进一步探讨了半变异函数模型的构建、空间插值与预测,以及空间数据模拟的高
【Multisim14实践案例全解】:如何构建现实世界与虚拟面包板的桥梁
# 摘要
本文详细介绍了Multisim 14软件的功能与应用,包括其基本操作、高级应用以及与现实世界的对接。文章首先概述了Multisim 14的界面布局和虚拟元件的使用,然后探讨了高级电路仿真技术、集成电路设计要点及故障诊断方法。接着,文章深入分析了如何将Multisim与实际硬件集成,包括设计导出、PCB设计与制作流程,以及实验案例分析。最后,文章展望了软件的优化、扩展和未来发展方向,涵
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )