【TensorFlow安装秘籍】:从零基础到实战部署,一步到位
发布时间: 2024-06-22 12:28:04 阅读量: 74 订阅数: 42 

TensorFlow安装教程

# 1. TensorFlow基础理论
TensorFlow是一个开源机器学习库,它提供了构建和训练神经网络模型所需的工具和基础设施。本章将介绍TensorFlow的基本理论,包括:
- **张量和变量:**TensorFlow中用于表示数据和模型参数的数据结构。
- **计算图:**TensorFlow使用计算图来表示神经网络模型,其中节点表示操作,而边表示数据流。
- **训练过程:**TensorFlow使用反向传播算法来训练神经网络模型,通过最小化损失函数来更新模型参数。
# 2. TensorFlow编程实践
### 2.1 TensorFlow的安装与环境配置
#### 2.1.1 不同平台的安装方式
TensorFlow支持多种平台,包括Windows、macOS和Linux。安装步骤因平台而异:
- **Windows:**
- 下载适用于Windows的TensorFlow安装包。
- 双击安装包并按照提示进行操作。
- 验证安装:打开命令提示符并输入`python -c "import tensorflow as tf; print(tf.__version__)"。`
- **macOS:**
- 通过Homebrew安装:`brew install tensorflow`。
- 通过pip安装:`pip install tensorflow`。
- 验证安装:打开终端并输入`python -c "import tensorflow as tf; print(tf.__version__)"。`
- **Linux:**
- 通过apt-get安装:`sudo apt-get install python3-tensorflow`。
- 通过pip安装:`pip install tensorflow`。
- 验证安装:打开终端并输入`python -c "import tensorflow as tf; print(tf.__version__)"。`
#### 2.1.2 环境变量的配置和验证
安装TensorFlow后,需要配置环境变量以使系统能够找到TensorFlow安装目录。
- **Windows:**
- 右键单击“计算机”并选择“属性”。
- 单击“高级系统设置”。
- 在“环境变量”选项卡中,在“系统变量”下找到“Path”变量。
- 单击“编辑”并添加TensorFlow安装目录的路径。
- **macOS和Linux:**
- 打开终端并输入以下命令:
```
export PATH=/path/to/tensorflow/bin:$PATH
```
- 将`/path/to/tensorflow/bin`替换为TensorFlow安装目录的路径。
验证环境变量配置:
- **Windows:**
- 打开命令提示符并输入`python -c "import tensorflow as tf; print(tf.__version__)"。`
- **macOS和Linux:**
- 打开终端并输入`python -c "import tensorflow as tf; print(tf.__version__)"。`
如果命令成功执行,则TensorFlow已正确安装并配置。
### 2.2 TensorFlow基础数据结构与操作
#### 2.2.1 张量(Tensor)和变量(Variable)
- **张量(Tensor):**
- 张量是TensorFlow中的基本数据结构,表示一个多维数组。
- 张量可以具有任意形状和数据类型。
- 创建张量:`tf.constant([[1, 2], [3, 4]])`。
- **变量(Variable):**
- 变量是可变的张量,用于存储模型参数或其他状态信息。
- 变量在训练过程中更新。
- 创建变量:`tf.Variable(tf.random.normal([784, 10]))`。
#### 2.2.2 常用数学运算和数据处理
TensorFlow提供了一系列数学运算和数据处理操作,包括:
- **数学运算:**
- 加法:`tf.add(a, b)`
- 乘法:`tf.multiply(a, b)`
- 指数:`tf.exp(a)`
- 对数:`tf.log(a)`
- **数据处理:**
- 归一化:`tf.nn.l2_normalize(a)`
- 激活函数:`tf.nn.relu(a)`
- 池化:`tf.nn.max_pool(a, ksize, strides)`
### 2.3 TensorFlow神经网络模型构建
#### 2.3.1 神经网络的基本原理
神经网络是一种机器学习模型,由相互连接的神经元组成。神经元接收输入,应用激活函数,并产生输出。神经网络通过训练优化权重和偏差,以最小化损失函数。
#### 2.3.2 TensorFlow中神经网络模型的搭建
TensorFlow提供了一系列层和模型,用于构建神经网络模型。
- **层:**
- 卷积层:`tf.keras.layers.Conv2D`
- 全连接层:`tf.keras.layers.Dense`
- 池化层:`tf.keras.layers.MaxPooling2D`
- **模型:**
- 顺序模型:`tf.keras.Sequential`
- 函数式模型:`tf.keras.Model`
构建一个简单的全连接神经网络:
```python
import tensorflow as tf
# 创建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=10, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(units=10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
```
# 3. TensorFlow实战应用
### 3.1 图像处理与识别
#### 3.1.1 图像预处理和增强
图像预处理是图像识别任务中的重要步骤,它可以提高模型的准确性和鲁棒性。TensorFlow提供了丰富的图像预处理操作,包括:
- **调整大小和裁剪:**`tf.image.resize()`和`tf.image.crop_to_bounding_box()`用于调整图像大小和裁剪特定区域。
- **颜色空间转换:**`tf.image.rgb_to_grayscale()`和`tf.image.hsv_to_rgb()`用于将图像从一种颜色空间转换到另一种颜色空间。
- **归一化和标准化:**`tf.image.per_image_standardization()`和`tf.image.per_image_whitening()`用于将图像像素值归一化或标准化,以减少照明和对比度变化的影响。
- **数据增强:**`tf.image.random_flip_left_right()`和`tf.image.random_brightness()`用于对图像进行随机翻转、旋转、缩放和亮度调整,以增加训练数据的多样性。
#### 3.1.2 卷积神经网络(CNN)在图像识别中的应用
卷积神经网络(CNN)是图像识别的强大工具,它利用卷积运算从图像中提取特征。TensorFlow提供了构建和训练CNN模型的全面支持,包括:
- **卷积层:**`tf.keras.layers.Conv2D()`用于执行卷积运算,提取图像中的特征。
- **池化层:**`tf.keras.layers.MaxPooling2D()`和`tf.keras.layers.AveragePooling2D()`用于对特征图进行池化操作,减少特征图的尺寸并增强鲁棒性。
- **全连接层:**`tf.keras.layers.Dense()`用于将提取的特征映射到最终的输出类别。
- **损失函数:**`tf.keras.losses.SparseCategoricalCrossentropy()`用于计算模型预测和真实标签之间的交叉熵损失。
- **优化器:**`tf.keras.optimizers.Adam()`用于优化模型参数,最小化损失函数。
### 3.2 自然语言处理
#### 3.2.1 文本预处理和特征提取
自然语言处理任务通常需要对文本数据进行预处理,包括:
- **分词:**`tf.strings.split()`用于将文本分割成单词或词组。
- **去停用词:**`tf.strings.regex_replace()`用于删除常见的停用词,如介词和连词。
- **词干化和词形还原:**`tf.keras.preprocessing.text.Tokenizer()`用于对单词进行词干化或词形还原,以减少词汇量。
- **特征提取:**`tf.keras.layers.Embedding()`用于将单词映射到稠密向量,以捕获单词的语义信息。
#### 3.2.2 循环神经网络(RNN)在自然语言处理中的应用
循环神经网络(RNN)是处理序列数据的强大工具,它可以学习序列中的长期依赖关系。TensorFlow提供了构建和训练RNN模型的全面支持,包括:
- **LSTM层:**`tf.keras.layers.LSTM()`用于处理长序列数据,它可以捕获序列中的长期依赖关系。
- **GRU层:**`tf.keras.layers.GRU()`是LSTM层的变体,它具有更简单的结构和更快的训练速度。
- **注意力机制:**`tf.keras.layers.Attention()`用于将RNN模型的输出加权,以关注序列中更重要的部分。
- **损失函数:**`tf.keras.losses.SparseCategoricalCrossentropy()`用于计算模型预测和真实标签之间的交叉熵损失。
- **优化器:**`tf.keras.optimizers.Adam()`用于优化模型参数,最小化损失函数。
### 3.3 机器学习算法实现
#### 3.3.1 监督学习与非监督学习
机器学习算法可分为监督学习和非监督学习。监督学习需要带标签的数据,而非监督学习则不需要。
- **监督学习:**`tf.keras.models.Sequential()`用于构建监督学习模型,它可以处理回归和分类任务。
- **非监督学习:**`tf.keras.models.Model()`用于构建非监督学习模型,它可以处理聚类、降维和生成式建模任务。
#### 3.3.2 TensorFlow中机器学习算法的实现
TensorFlow提供了丰富的机器学习算法实现,包括:
- **线性回归:**`tf.keras.models.Sequential([tf.keras.layers.Dense(units=1)])`用于构建线性回归模型。
- **逻辑回归:**`tf.keras.models.Sequential([tf.keras.layers.Dense(units=1, activation='sigmoid')])`用于构建逻辑回归模型。
- **决策树:**`tf.keras.models.Sequential([tf.keras.layers.DecisionTreeClassifier()])`用于构建决策树模型。
- **支持向量机:**`tf.keras.models.Sequential([tf.keras.layers.SVM()])`用于构建支持向量机模型。
- **聚类:**`tf.keras.models.Sequential([tf.keras.layers.KMeans()])`用于构建K均值聚类模型。
- **降维:**`tf.keras.models.Sequential([tf.keras.layers.PCA()])`用于构建主成分分析(PCA)模型。
# 4. TensorFlow模型部署与优化
### 4.1 TensorFlow模型的导出与部署
#### 4.1.1 模型的保存和加载
在训练好TensorFlow模型后,需要将其保存起来以便后续部署和使用。TensorFlow提供了`tf.saved_model`模块来保存和加载模型。
```python
# 保存模型
tf.saved_model.save(model, "my_model")
# 加载模型
loaded_model = tf.saved_model.load("my_model")
```
#### 4.1.2 模型的部署方式和注意事项
TensorFlow模型可以部署在多种平台上,包括:
- **本地部署:**将模型部署在本地服务器或计算机上,直接为本地应用程序提供服务。
- **云部署:**将模型部署在云平台上,如AWS、Azure或Google Cloud,以获得可扩展性和高可用性。
- **移动部署:**将模型部署在移动设备上,如智能手机或平板电脑,以实现边缘计算。
在部署模型时,需要考虑以下注意事项:
- **硬件要求:**模型的部署平台需要满足模型的硬件要求,如内存、CPU或GPU性能。
- **软件环境:**部署平台需要安装必要的软件环境,如TensorFlow和相关依赖项。
- **数据预处理:**部署模型时,需要对输入数据进行预处理,使其与训练数据一致。
- **模型监控:**部署后需要监控模型的性能,以确保其准确性和效率。
### 4.2 TensorFlow模型的性能优化
#### 4.2.1 模型架构优化
模型架构优化是指通过调整模型的结构来提高其性能。常用的优化方法包括:
- **修剪:**移除模型中不重要的层或节点,以减少计算量。
- **量化:**将模型中的浮点参数转换为低精度数据类型,如int8或int16,以减少内存占用和计算量。
- **蒸馏:**使用一个较大的教师模型来训练一个较小的学生模型,以提高学生模型的性能。
#### 4.2.2 训练过程优化
训练过程优化是指通过调整训练超参数来提高模型的性能。常用的优化方法包括:
- **学习率调整:**调整学习率以控制模型训练的速度和收敛性。
- **正则化:**添加正则化项到损失函数中,以防止模型过拟合。
- **数据增强:**对训练数据进行增强,如旋转、翻转或裁剪,以增加数据的多样性。
### 4.3 TensorFlow模型的监控与管理
#### 4.3.1 模型监控指标的定义
在部署模型后,需要监控其性能以确保其准确性和效率。常用的监控指标包括:
- **准确率:**模型对新数据的预测准确性。
- **损失函数:**模型在训练和验证数据集上的损失值。
- **推理时间:**模型处理单个输入所需的时间。
- **内存占用:**模型在部署平台上占用的内存量。
#### 4.3.2 模型管理与版本控制
随着模型的更新和迭代,需要对其进行管理和版本控制。常用的管理方法包括:
- **版本控制:**使用Git或其他版本控制系统来跟踪模型的更改。
- **模型注册:**将模型注册到模型注册表中,以便于跟踪和管理。
- **模型评估:**定期评估模型的性能,以确定是否需要更新或重新训练。
# 5.1 TensorFlow分布式训练
### 5.1.1 分布式训练的原理和优势
分布式训练是一种将训练任务分配给多个计算节点(如GPU或CPU)同时执行的技术。其原理是将训练数据集划分为多个子集,每个节点负责训练一个子集,然后将各节点的训练结果汇总起来更新模型参数。
分布式训练的主要优势包括:
- **缩短训练时间:**通过并行计算,分布式训练可以显著缩短大型模型的训练时间。
- **提高模型性能:**分布式训练可以利用更多的数据和计算资源,从而训练出性能更好的模型。
- **扩展模型规模:**分布式训练可以支持训练超大规模的模型,这些模型在单个节点上无法训练。
- **容错性:**分布式训练系统通常具有容错性,即使某个节点发生故障,训练过程也可以继续进行。
### 5.1.2 TensorFlow中分布式训练的实现
TensorFlow提供了多种分布式训练策略,包括:
- **MirroredStrategy:**将模型副本复制到所有节点,每个节点训练模型副本的完整副本。
- **ParameterServerStrategy:**将模型参数存储在单独的节点(称为Parameter Server)上,而计算节点从Parameter Server获取参数并更新本地副本。
- **CollectiveAllReduceStrategy:**使用AllReduce操作在节点之间聚合梯度,从而更新模型参数。
分布式训练的实现涉及以下步骤:
1. **创建分布式策略:**选择并创建合适的分布式策略,如MirroredStrategy或ParameterServerStrategy。
2. **配置分布式数据集:**将训练数据集划分为多个子集,并创建分布式数据集对象。
3. **构建分布式模型:**使用分布式策略包装模型,使其能够在多个节点上训练。
4. **训练分布式模型:**使用分布式数据集训练模型,并使用分布式策略更新模型参数。
**代码示例:**
```python
import tensorflow as tf
# 创建分布式策略
strategy = tf.distribute.MirroredStrategy()
# 配置分布式数据集
dataset = tf.data.Dataset.from_tensor_slices(features).batch(32)
dataset = strategy.experimental_distribute_dataset(dataset)
# 构建分布式模型
with strategy.scope():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# 训练分布式模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(dataset, epochs=10)
```
**代码逻辑分析:**
- 创建分布式策略MirroredStrategy,该策略将模型副本复制到所有节点。
- 配置分布式数据集,将训练数据集划分为多个子集。
- 使用分布式策略包装模型,使其能够在多个节点上训练。
- 使用分布式数据集训练模型,并使用分布式策略更新模型参数。
# 6.1 TensorFlow 2.0的新特性和改进
### 6.1.1 Keras集成和简化API
TensorFlow 2.0与Keras深度集成,提供了一个更加简洁易用的API。Keras是一个高级神经网络API,它允许用户快速构建和训练神经网络模型。通过集成Keras,TensorFlow 2.0简化了模型构建过程,使开发人员能够专注于模型的逻辑和性能,而不是底层实现细节。
### 6.1.2 性能优化和可扩展性增强
TensorFlow 2.0在性能和可扩展性方面进行了重大改进。它引入了Eager Execution模式,该模式允许即时执行操作,从而提高了训练和调试的效率。此外,TensorFlow 2.0还支持分布式训练,允许在多台机器上并行训练模型,从而缩短训练时间并提高模型性能。
```
# TensorFlow 2.0中使用Eager Execution模式
import tensorflow as tf
# 创建一个张量
x = tf.constant([[1, 2], [3, 4]])
# 立即执行一个操作
y = tf.reduce_mean(x)
# 打印结果
print(y)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供有关 Python 中 TensorFlow 安装的全面指南,从基础知识到高级实践。涵盖广泛的主题,包括:
* 安装秘籍:逐步指南,从零基础到实战部署
* 黑匣子揭秘:常见问题的深入分析
* 安装原理:底层机制的深入剖析
* 终极指南:最佳实践,轻松上手
* Docker 容器安装:释放 GPU 加速的强大性能
* GPU 安装:释放超级计算力
* 依赖库安装:解决兼容性问题
* 版本选择与兼容性:避免踩坑,高效安装
* 自动化与脚本化:解放双手,高效部署
* 性能优化:让您的安装飞起来
* 疑难杂症大全:彻底解决安装难题
* 操作系统兼容性:跨平台部署,无缝衔接
* 云平台集成:云上部署,轻松自如
* 框架比较:优劣分析,做出最佳选择
* 安全注意事项:保障数据安全,防患未然
* 最佳实践指南:稳定高效,事半功倍
* 分布式训练环境配置:大规模训练,高效协作
* 容器编排系统集成:自动化部署,轻松管理
* 自动化测试实践:持续集成,确保质量
* 持续集成和持续部署结合:自动化部署,持续交付
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决兼容性难题:Aspose.Words 15.8.0 如何与旧版本和平共处

# 摘要
Aspose.Words是.NET领域内用于处理文档的强大组件,广泛应用于软件开发中以实现文档生成、转换、编辑等功能。本文从版本兼容性问题、新版本改进、代码迁移与升级策略、实际案例分析
【电能表软件更新完全手册】:系统最新状态的保持方法

# 摘要
电能表软件更新是确保电能计量准确性和系统稳定性的重要环节。本文首先概述了电能表软件更新的理论基础,分析了电能表的工作原理、软件架构以及更新的影响因素。接着,详细阐述了更新实践步骤,包括准备工作、实施过程和更新后的验证测试。文章进一步探讨了软件更新的高级应用,如自动化策略、版
全球视角下的IT服务管理:ISO20000-1:2018认证的真正益处
# 摘要
本文综述了IT服务管理的最新发展,特别是针对ISO/IEC 20000-1:2018标准的介绍和分析。文章首先概述了IT服务管理的基础知识,接着深入探讨了该标准的历史背景、核心内容以及与旧版标准的差异,并评估了这些变化对企业的影响。进一步,文章分析了获得该认证为企业带来的内部及外部益处,包括服务质量和客户满意度的提升,以及市场竞争力的增强。随后,
Edge与Office无缝集成:打造高效生产力环境
# 摘要
随着数字化转型的加速,企业对于办公生产力工具的要求不断提高。本文深入探讨了微软Edge浏览器与Office套件集成的概念、技术原理及实践应用。分析了微软生态系统下的技术架构,包括云服务、API集成以
开源HRM软件:选择与实施的最佳实践指南(稀缺性:唯一全面指南)

# 摘要
本文针对开源人力资源管理系统(HRM)软件的市场概况、选择、实施、配置及维护进行了全面分析。首先,概述了开源HRM软件的市场状况及其优势,接着详细讨论了如何根据企业需求选择合适软件、评估社区支持和技术实力、探索定制和扩展能力。然后,本文提出了一个详尽的实施计划,并强调
性能优化秘籍:提升Quectel L76K信号强度与网络质量的关键

# 摘要
本文首先介绍了Quectel L76K模块的基础知识及其性能影响因素。接着,在理论基础上阐述了无线通信信号的传播原理和网络质量评价指标,进一步解读了L76K模块的性能参数与网络质量的关联。随后,文章着重分析了信号增强技术和网络质量的深度调优实践,包括降低延迟、提升吞吐量和增强网络可靠性的策略。最后,通过案例研究探讨了L76K模块在不同实际应用场景中
【SPC在注塑成型中的终极应用】:揭开质量控制的神秘面纱
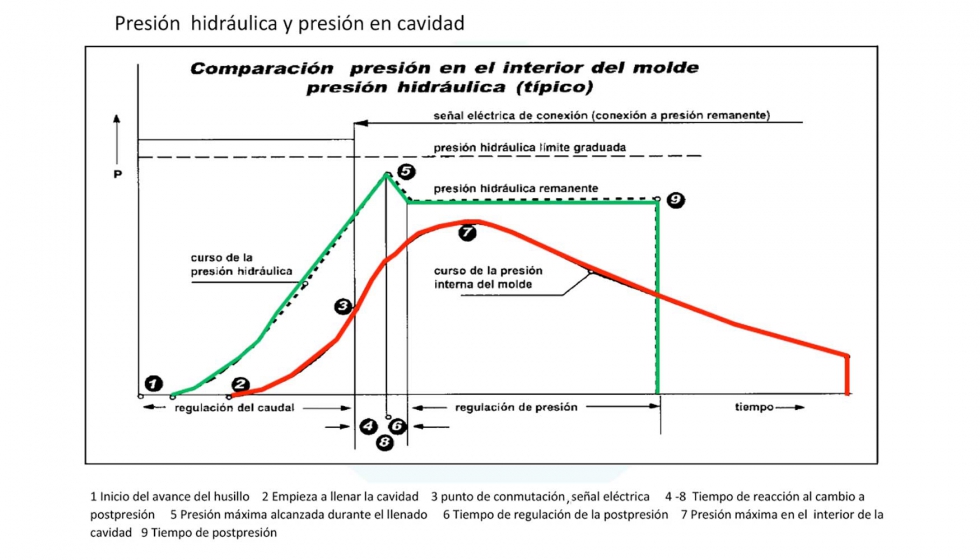
# 摘要
统计过程控制(SPC)是确保注塑成型产品质量和过程稳定性的关键方法。本文首先介绍了SPC的基础概念及其与质量控制的紧密联系,随后探讨了SPC在注塑成型中的实践应用,包括质量监控、设备整合和质量改进案例。文章进一步分析了SPC技术的高级应用,挑战与解决方案,并展望了其在智能制造和工业4.0环境下的未来趋势。通过对多个行业案例的研究,本文总结了SPC成功实施的关键因素,并提供了基于经验教训的优化策略。本文的研究强调了SPC在
YXL480高级规格解析:性能优化与故障排除的7大技巧

# 摘要
YXL480作为一款先进的设备,在本文中对其高级规格进行了全面的概览。本文深入探讨了YXL480的性能特性,包括其核心架构、处理能力、内存和存储性能以及能效比。通过量化分析和优化策略的介绍,本文揭示了YXL480如何实现高效能。此外,文章还详细介绍了YXL480故障诊断与排除的技巧,从理论基础到实践应用,并探讨了性能优化的方法论,提供了硬件与软
西门子PLC与HMI集成指南:数据通信与交互的高效策略

# 摘要
本文详细介绍了西门子PLC与HMI集成的关键技术和应用实践。首先概述了西门子PLC的基础知识和通信协议,探讨了其工作原理、硬件架构、软件逻辑和通信技术。接着,文章转向HMI的基础知识与界面设计,重点讨论了人机交互原理和界面设计的关键要素。在数据通信实践操
【视觉SLAM入门必备】:MonoSLAM与其他SLAM方法的比较分析

# 摘要
视觉SLAM(Simultaneous Localization and Mapping)技术是机器人和增强现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )