理解线程池在Java_Python_C++等语言中的异同
发布时间: 2024-03-12 08:40:31 阅读量: 41 订阅数: 22 

C++实现的线程池
# 1. 线程池的基本概念
## 1.1 线程池是什么?
在计算机编程领域,线程池(Thread Pool)是一种线程使用模型,它包含了一组线程,等待请求分配工作。当有任务到来时,线程池中的线程会唤醒执行任务,任务执行完毕后,线程则返回线程池中,等待下一个任务。
## 1.2 线程池的作用及优势
线程池的作用主要在于提高多线程任务处理的效率和性能。通过线程池,可以避免频繁创建和销毁线程所带来的性能开销,合理控制并发线程数量,提高系统的稳定性和响应速度。
线程池的优势包括:
- 降低系统资源消耗:减少线程创建和销毁的开销;
- 提高系统响应速度:避免线程创建和销毁的时间消耗;
- 控制并发线程数量:合理管理线程数量,避免系统负载过高;
- 提高程序可管理性:统一管理线程的生命周期和状态。
## 1.3 不同语言中线程池的实现方式
不同编程语言在实现线程池时会有一些差异,主要体现在线程池的构建方式、操作方式和对线程的管理等方面。常见的编程语言如Java、Python、C等在线程池的实现上有各自独特的特点,后续章节将会针对不同语言进行详细介绍。
# 2. Java中的线程池
在Java中,线程池是非常常用的并发编程工具,它可以有效地管理线程的生命周期、减少线程创建和销毁的开销、提高系统的性能。
### 2.1 Java中线程池的使用
在Java中使用线程池,通常需要通过`ExecutorService`接口来创建线程池。以下是一个简单的线程池的创建和使用示例:
```java
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExample {
public static void main(String[] args) {
// 创建一个固定大小的线程池,同时最多存在3个线程
ExecutorService executor = Executors.newFixedThreadPool(3);
// 提交任务给线程池
for (int i = 0; i < 10; i++) {
executor.submit(() -> {
System.out.println("Task running in thread: " + Thread.currentThread().getName());
});
}
// 关闭线程池
executor.shutdown();
}
}
```
### 2.2 Java中线程池的参数设置
在Java中,线程池的参数设置可以通过`ThreadPoolExecutor`类的构造方法进行灵活配置,如核心线程数、最大线程数、线程空闲时间等参数。以下是一个示例:
```java
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class CustomThreadPoolExample {
public static void main(String[] args) {
ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 4, 10, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(2));
// 提交任务给线程池
for (int i = 0; i < 5; i++) {
executor.submit(() -> {
System.out.println("Task running in thread: " + Thread.currentThread().getName());
});
}
// 关闭线程池
executor.shutd
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深度剖析Renren Security:功能模块背后的架构秘密

# 摘要
Renren Security是一个全面的安全框架,旨在为Web应用提供强大的安全保护。本文全面介绍了Renren Security的核心架构、设计理念、关键模块、集成方式、实战应用以及高级特性。重点分析了认证授权机制、过滤器链设计、安全拦截器的运作原理和集成方法。通过对真实案例的深入剖析,本文展示了Renren Security在实际应用中的效能,并探讨了性能优化和安全监
电力系统稳定性分析:PSCAD仿真中的IEEE 30节点案例解析
# 摘要
本文详细探讨了电力系统稳定性及其在仿真环境中的应用,特别是利用PSCAD仿真工具对IEEE 30节点系统进行建模和分析。文章首先界定了电力系统稳定性的重要性并概述了仿真技术,然后深入分析了IEEE 30节点系统的结构、参数及稳定性要求。在介绍了PSCAD的功能和操作后,本文通过案例展示了如何在PSCAD中设置和运行IEEE 30节点模型,进行稳定性分析,并基于理论对仿真结果进行了详细分析
Infovision iPark高可用性部署:专家传授服务不间断策略
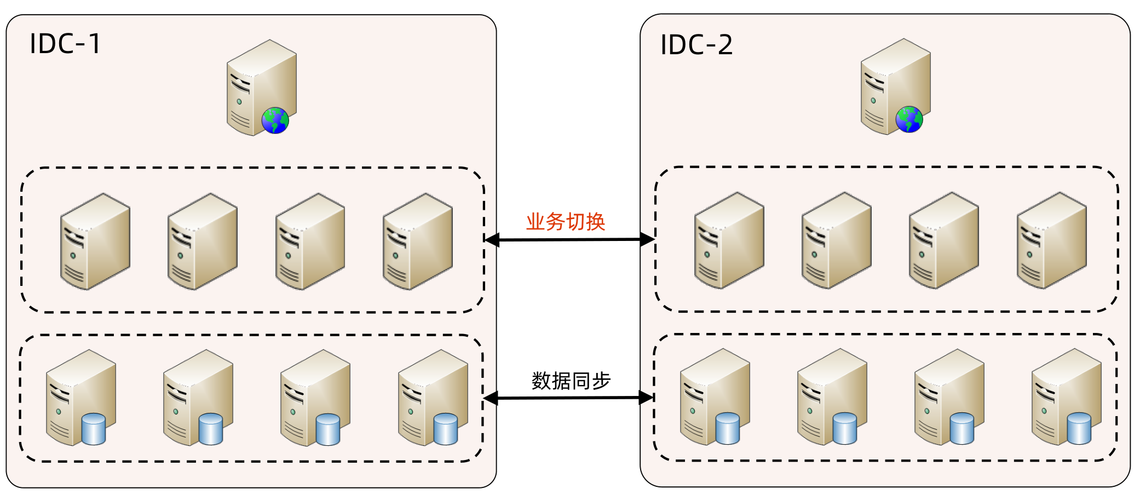
# 摘要
Infovision iPark作为一款智能停车系统解决方案,以其高可用性的设计,能够有效应对不同行业特别是金融、医疗及政府公共服务行业的业务连续性需求。本文首先介绍了Infovision iPark的基础架构和高可用性理论基础,包括高可用性的定义、核心价值及设计原则。其次,详细阐述了Infovision iPark在实际部署中的高可用性实践,包括环境配
USCAR38供应链管理:平衡质量与交付的7个技巧

# 摘要
供应链管理作为确保产品从原材料到终端用户高效流动的复杂过程,其核心在于平衡质量与交付速度。USCAR38的供应链管理概述了供应链管理的理论基础和实践技巧,同时着重于质量与交付之间的平衡挑战。本文深入探讨了供应链流程的优化、风险应对策略以及信息技术和自动化技术的应用。通过案例研究,文章分析了在实践中平衡质量与交付的成功与失败经验,并对供应链管理的未来发展趋
组合数学与算法设计:卢开澄第四版60页的精髓解析
# 摘要
本文系统地探讨了组合数学与算法设计的基本原理和方法。首先概述了算法设计的核心概念,随后对算法分析的基础进行了详细讨论,包括时间复杂度和空间复杂度的度量,以及渐进符号的使用。第三章深入介绍了组合数学中的基本计数原理和高级技术,如生成函数和容斥原理。第四章转向图论基础,探讨了图的基本性质、遍历算法和最短路径问题的解决方法。第五章重点讲解了动态规划和贪心算法,以及它们在
【Tomcat性能优化实战】:打造高效稳定的Java应用服务器

# 摘要
本文旨在深入分析并实践Tomcat性能优化方法。首先,文章概述了Tomcat的性能优化概览,随后详细解析了Tomcat的工作原理及性能
【BIOS画面定制101】:AMI BIOS初学者的完全指南
# 摘要
本文介绍了AMI BIOS的基础知识、设置、高级优化、界面定制以及故障排除与问题解决等关键方面。首先,概述了BIOS的功能和设置基础,接着深入探讨了性能调整、安全性配置、系统恢复和故障排除等高级设置。文章还讲述了BIOS画面定制的基本原理和实践技巧,包括界面布局调整和BIOS皮肤的更换、设计及优化。最后,详细介绍了BIOS更新、回滚、错误解决和长期维护
易康eCognition自动化流程设计:面向对象分类的优化路径

# 摘要
本文综述了易康eCognition在自动化流程设计方面的应用,并详细探讨了面向对象分类的理论基础、实践方法、案例研究、挑战与机遇以及未来发展趋势。文中从地物分类的概念出发,分析了面向对象分类的原理和精度评估方法。随后,通过实践章节展示如何在不同领域中应用易康eCognition进行流程设计和高级分类技术的实现。案例研究部分提供了城市用地、森林资
【变频器通讯高级诊断策略】:MD800系列故障快速定位与解决之道

# 摘要
本文系统阐述了变频器通讯的原理与功能,深入分析了MD800系列变频器的技术架构,包括其硬件组成、软件架构以及通讯高级功能。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )