Python库文件学习之main:性能优化与性能测试的私密性
发布时间: 2024-10-12 22:09:21 阅读量: 2 订阅数: 5 

# 1. Python库文件基础
## 1.1 Python库文件的概念
Python库文件是Python编程中不可或缺的一部分,它包含了一系列预先定义好的函数和变量,这些函数和变量可以被Python程序重复使用,以提高开发效率和代码的可维护性。库文件通常以`.py`或`.pyc`为后缀,前者为源代码文件,后者为编译后的字节码文件。
## 1.2 导入库文件的方法
在Python中,我们可以通过多种方式导入库文件。最基本的方式是使用`import`语句,例如:
```python
import math
print(math.sqrt(16))
```
此外,我们还可以使用`from ... import ...`语句来导入特定的函数或类:
```python
from math import sqrt
print(sqrt(16))
```
## 1.3 创建自定义库文件
除了使用标准库和第三方库,我们还可以创建自己的库文件。创建自定义库文件非常简单,只需要将需要复用的函数定义在一个Python文件中,并将该文件保存在Python的搜索路径中即可。
例如,创建一个名为`mymodule.py`的文件,内容如下:
```python
def say_hello(name):
print(f"Hello, {name}!")
```
然后在另一个文件中导入并使用它:
```python
from mymodule import say_hello
say_hello("Alice")
```
通过这种方式,我们可以构建自己的模块,以提高代码的复用性和模块化。
# 2. 性能优化的基本原理与策略
在本章节中,我们将深入探讨性能优化的两个主要层面:代码层面和系统层面。我们会从算法优化开始,探讨数据结构选择、循环优化、并行与并发编程、资源管理与调度,以及缓存机制的实现。此外,我们还将介绍性能优化工具和实际案例分析,帮助读者更好地理解如何将这些原理应用到实际工作中。
## 2.1 代码层面的性能优化
### 2.1.1 算法优化
算法是性能优化的核心。选择合适的算法可以在很大程度上提高程序的执行效率。例如,在排序问题中,快速排序(Quick Sort)通常比冒泡排序(Bubble Sort)更高效,因为它的时间复杂度较低(O(n log n) vs O(n^2))。
```python
# 示例:快速排序算法
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 逻辑分析
# 快速排序通过递归的方式将数组分为更小的部分,然后分别排序。
# 参数说明:
# arr - 待排序的数组
# pivot - 分区的基准点
# left, middle, right - 分别存储小于、等于和大于基准点的元素
```
### 2.1.2 数据结构选择
选择合适的数据结构对于性能优化至关重要。例如,使用哈希表(Hash Table)可以提供平均情况下O(1)的查找时间复杂度,而链表则需要O(n)的时间复杂度。
```python
# 示例:使用哈希表存储键值对
data_structure = {'key1': 'value1', 'key2': 'value2'}
# 逻辑分析
# 哈希表通过键直接访问值,避免了线性搜索的开销。
# 参数说明:
# data_structure - 哈希表对象
# key - 键值
# value - 对应的数据
```
### 2.1.3 循环优化
循环优化是代码层面性能优化的另一个重要方面。减少循环的次数、使用循环展开(Loop Unrolling)和循环分割(Loop Splitting)等技术可以显著提高性能。
```python
# 示例:循环展开技术
for i in range(0, 1000, 2):
print(i)
# 逻辑分析
# 循环展开通过减少循环迭代次数来提高效率。
# 参数说明:
# i - 循环变量
# range(0, 1000, 2) - 从0开始到1000结束,步长为2
```
## 2.2 系统层面的性能优化
### 2.2.1 并行与并发编程
并行与并发编程是提高系统性能的有效手段。多线程(Multithreading)和多进程(Multiprocessing)是实现并行与并发的两种主要技术。
```python
# 示例:多线程编程
import threading
def print_numbers():
for i in range(1, 6):
print(i)
thread1 = threading.Thread(target=print_numbers)
thread2 = threading.Thread(target=print_numbers)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
# 逻辑分析
# 多线程允许程序同时执行多个任务,提高CPU利用率。
# 参数说明:
# print_numbers - 被线程执行的函数
# thread1, thread2 - 创建的线程对象
# start() - 启动线程
# join() - 等待线程结束
```
### 2.2.2 资源管理与调度
合理管理内存、CPU和其他系统资源可以提高程序的性能。资源调度算法,如轮转调度(Round Robin)和优先级调度(Priority Scheduling),对于多任务系统尤为重要。
### 2.2.3 缓存机制的实现
缓存机制可以显著提高数据访问的速度。使用局部性原理,将频繁访问的数据存储在缓存中,可以减少对慢速存储设备的访问。
## 2.3 性能优化工具与实践
### 2.3.1 性能分析工具介绍
性能分析工具如cProfile、line_profiler等可以帮助开发者识别性能瓶颈。
```python
# 示例:使用cProfile进行性能分析
import cProfile
def main():
# 执行性能分析的代码
pass
cProfile.run('main()')
# 逻辑分析
# cProfile可以提供详细的性能分析报告,帮助识别热点代码。
# 参数说明:
# main - 被分析的函数
# run - 性能分析函数
```
### 2.3.2 实际案例分析
通过实际案例分析,我们可以更好地理解性能优化工具的应用和效果。
### 2.3.3 实际案例分析
通过实际案例分析,我们可以更好地理解性能优化工具的应用和效果。
以上内容展示了性能优化的基本原理与策略,包括代码层面和系统层面的优化方法,以及性能优化工具的使用和实际案例分析。这些内容旨在帮助读者深入理解性能优化的基本概念和实践技巧,为后续章节的深入探讨奠定基础。
# 3. 性能测试的理论与实践
## 3.1 性能测试的基本概念
### 3.1.1 性能测试的目的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"Python库文件学习之main"专栏是一个深入探索Python库文件开发的全面指南。它涵盖了从入门到高级主题的各个方面,包括基本结构、参数解析、性能优化、环境配置、调试技巧、单元测试、版本控制、错误处理、打包和分发、文档编写、持续集成和代码复用。该专栏旨在为开发人员提供全面的知识和实践指导,帮助他们创建和维护高质量的Python库文件,同时了解社区最佳实践和行业趋势。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Django Admin Filterspecs进阶技巧:处理复杂数据类型的策略(专业性、权威性)

# 1. Django Admin FilterSpecs概述
## Django Admin FilterSpecs概述
在Django的管理后台中,FilterSpecs扮演着至关重要的角色,它负责生成过滤器的规范,使得
【django.core.files与数据库交互】:优化文件存储的数据库使用策略

# 1. django.core.files模块概述
在本章中,我们将深入探讨Django框架中的`django.core.files`模块,这是Django处理文件上传和管理的核心模块。我们将首先概述该模块的基本用途和结构,然后逐步深入到具体的文件存储机制和实践案例中。
## 模块概述
`django.core.files`模块为Django开发者提供了一系列工具
rlcompleter与其他工具对比:选择最适合你的Python自动补全解决方案

# 1. Python自动补全工具概述
## 1.1 自动补全工具的必要性
在Python开发中,自动补全工具已经成为提高编码效率和减少错误的重要工具。它们通过实时分析代码上下文和用户输入,提供智能的代码提示和补全建议,帮助开发者更快速、更准确地编写代码。
## 1.2 Python自动补全工具的发展
Python自动补
性能提升秘诀:如何用Numeric库处理大规模数据集

# 1. Numeric库概述
## 1.1 引言
在数据科学和工程领域,对数值计算的需求日益增长。Numeric库作为一个强大的数值计算工具,为处理大规
硬件加速多媒体处理:Python中的Gst应用与线程安全策略
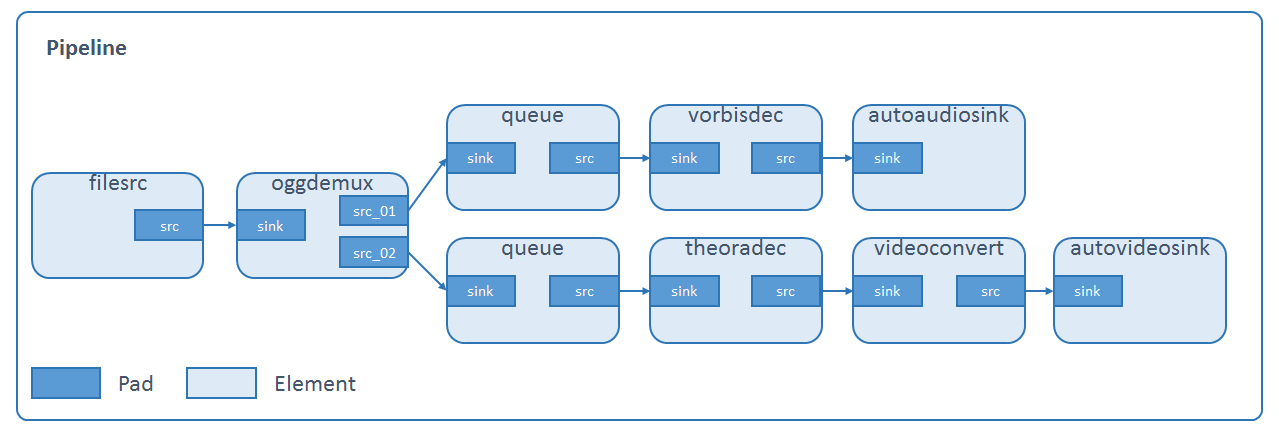
# 1. 硬件加速多媒体处理概述
在现代计算领域,多媒体处理已成为一项至关重要的技术,尤其随着高清视频内容和虚拟现实应用的增长,对处理性能的要求也随之提高。硬件加速是一种利用专门硬件(如GPU、专用解码器)来加速多媒体数据处理的技术,它可以显著提升处理效率,降低CPU负载,从而实现更加流畅的多媒体体验。
随着多核处理器的普及和并行计算能力的增强,软件开发者开始探索如何更
FormEncode与用户输入安全处理:构建安全表单验证的最佳实践

# 1. FormEncode概述
## FormEncod
Python Win32file库的版本控制:管理代码变更与依赖的最佳实践

# 1. Python Win32file库概述
## 1.1 Python Win32file库简介
Python Win32file库是Windows平台上使用Python进行文件操作的一个重要工具库。它提供了一系列接口,使得开发者能够方便地进行文件操作,包括文件的读写、创建、删除等。这个库是Python for Windows Extensio
Mako模板中的宏:简化代码的高级技巧与应用案例
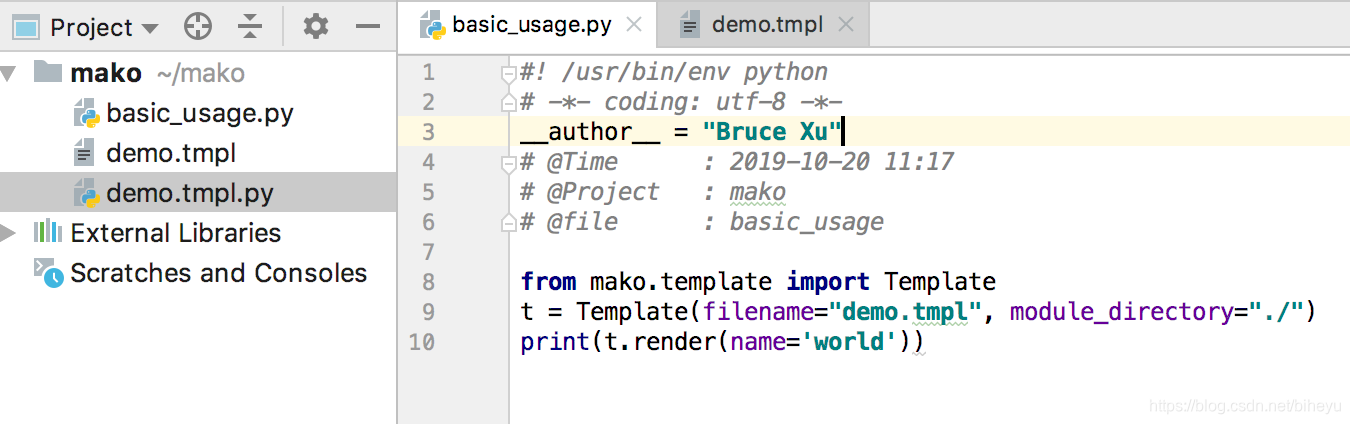
# 1. Mako模板引擎概述
## Mako模板引擎简介
Mako是一个高性能的模板引擎,由Python语言编写,被广泛用于生成动态网页内容。它的设计理念是简单、高
【Pygments自动化测试】:确保代码高亮功能的稳定性和准确性
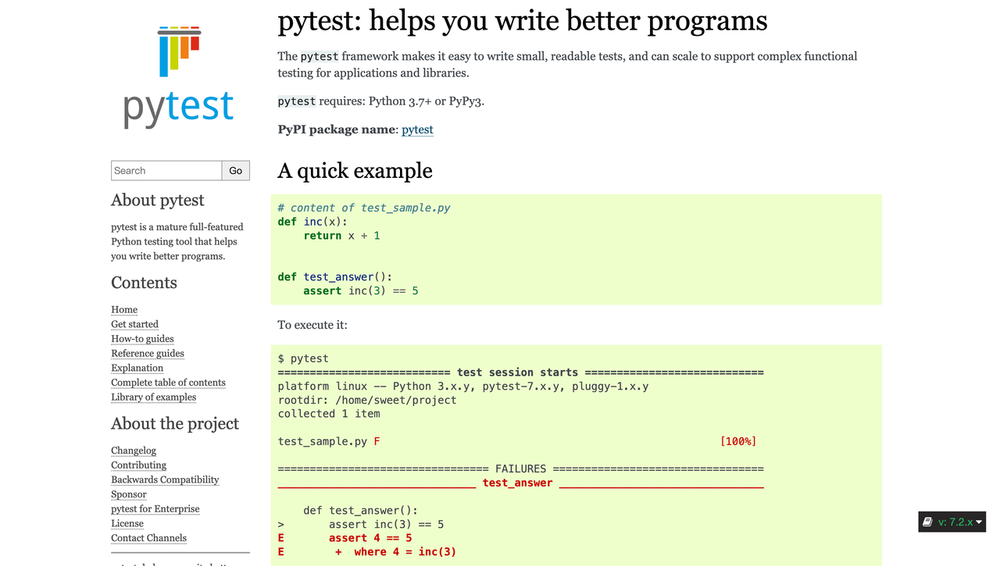
# 1. Pygments简介与安装
## 简介
Pygments 是一个用 Python 写成的语法高亮库,广泛应用于代码展示和编辑。它支持多种编程语言和格式,并提供了丰富的样式自定义选项。由于其强大的功能和简洁的接口,Pygments 成为了 IT 行业中代码高亮处理的事实标准。
## 安装 Pygments
安装 Pygments 相当简单,您可以使用 pi
【自动化测试新手段】:在自动化测试中利用tkFileDialog提高效率

# 1. 自动化测试基础概念
自动化测试是确保软件产品质量的关键环节,它通过编写和执行脚本自动完成测试任务,提高测试效率和覆盖率。自动化测试不仅能够节省时间,还能保证测试的一致性和可重复性,减少人为错误。
在本章中,我们将探讨自动化测试的基础知识,包括其定义、重要性以及与手动测试的对比。我们将了解自动化测试如何
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )