基于Python的情感分析:从理论到实际应用,完整指南助你入门
发布时间: 2024-08-31 12:44:38 阅读量: 96 订阅数: 53 
# 1. Python情感分析概述
## 概念界定
情感分析是利用计算机技术自动识别和提取文本中表达的情感倾向,用正面或负面来表示文本的情感色彩。在Python中,结合各种库和框架,可以对大量文本数据进行快速准确的情感分析,广泛应用于社交媒体、市场调研、舆情监控等领域。
## Python的角色
Python因其简洁的语法和强大的库支持,在情感分析领域有着特殊的地位。通过像NLTK、TextBlob、spaCy等自然语言处理库,Python能高效地处理文本,实现情感分析。而像scikit-learn、TensorFlow、PyTorch等机器学习框架,则进一步提升了情感分析模型的构建与优化能力。
## 应用前景
随着人工智能的发展,情感分析作为人工智能的一个重要分支,其在实际应用中的前景十分广阔。例如,通过分析消费者评论来优化产品特性、监控企业品牌在社交媒体上的公众情感、分析政治倾向等,都是情感分析的典型应用场景。Python情感分析不仅助力决策者更准确地把握情绪动态,也为用户提供了全新的视角和解决方案。
通过本章节的学习,我们为后续章节中情感分析的技术细节、实践环境搭建以及实际应用案例打下了基础。接下来,让我们深入探索情感分析的理论基础。
# 2. 情感分析的理论基础
在进入情感分析的具体实现之前,理解其理论基础是至关重要的。本章将引领读者深入了解自然语言处理(NLP)、情感分析的核心概念、以及为情感分析提供支持的机器学习基础。
## 2.1 自然语言处理简介
### 2.1.1 自然语言处理的发展历程
自然语言处理是计算机科学、人工智能以及语言学领域的一个交叉领域,其目标是使计算机能够理解和处理人类语言。NLP 的发展历程始于20世纪50年代,伴随着计算机技术的起步,从最初的基于规则的系统,发展到统计模型,再到如今的深度学习模型。
- **早期阶段(1950s-1970s)**:这一时期的研究着重于构建复杂的语法规则和启发式算法。典型的方法有乔姆斯基的转换生成语法。
- **统计学习阶段(1990s-2000s)**:统计方法如隐马尔可夫模型(HMM)和条件随机场(CRF)开始流行,这些方法对语言数据进行量化分析。
- **深度学习革命(2010s-至今)**:随着计算能力的提高和大数据的普及,深度神经网络如卷积神经网络(CNN)和循环神经网络(RNN)带来了显著的性能提升。
### 2.1.2 自然语言处理的主要任务
自然语言处理的主要任务可以分为以下几个方面:
- **文本分类**:将文本分配给一个或多个类别,如情感分析、垃圾邮件检测等。
- **信息提取**:从非结构化文本中提取结构化信息,如命名实体识别、关系抽取等。
- **语言模型**:预测下一个词或构建理解句子的概率模型。
- **机器翻译**:将一种语言的文本转换成另一种语言。
- **语音识别和生成**:将语音转化为文本,或将文本转化为自然语音。
## 2.2 情感分析的概念与技术路线
### 2.2.1 情感分析的定义和应用领域
情感分析是自然语言处理的一个子领域,它关注于识别、提取和处理文本中的主观信息,比如情绪倾向、情感态度和观点。它可以应用于多个领域,例如:
- **社交媒体监测**:分析用户在社交平台上的评论和帖子,以了解公众对品牌、产品或服务的看法。
- **市场研究**:通过情感分析来获取消费者对新产品或服务的感受和建议。
- **股票市场预测**:依据财经新闻或市场情绪预测股票价格变动。
- **政治分析**:评估公众对政治议题或候选人的态度。
### 2.2.2 常用的情感分析方法和工具
情感分析的方法可以分为基于词典的方法、机器学习方法和深度学习方法。
- **基于词典的方法**:通常使用预先定义的词汇和短语的情感倾向性,如正、负或中立,来分析文本。
- **机器学习方法**:使用标注好的训练数据集,训练分类器来预测文本的情感极性。
- **深度学习方法**:应用深度学习模型,如循环神经网络(RNN)和变换器模型(Transformer),来自动学习复杂的语言表示和情感分类。
在选择情感分析工具时,常见的选项包括:
- **开源库**:例如 Python 的 Natural Language Toolkit(NLTK)和 TextBlob,它们提供了丰富的文本处理工具和情感分析功能。
- **商业平台**:如 IBM Watson Tone Analyzer 和 Google Cloud Natural Language API,这些平台通常具有更强大的处理能力和企业级支持。
## 2.3 情感分析中的机器学习基础
### 2.3.1 机器学习的基本原理
机器学习是人工智能的一个分支,它赋予计算机学习的能力,通常是从数据中学习,而无需明确编程。在情感分析中,机器学习用于建立模型来识别和预测文本数据中的情感倾向。
关键步骤包括:
- **数据准备**:收集并准备标注好的训练数据。
- **特征提取**:从文本数据中提取有助于模型学习的特征。
- **模型选择和训练**:选择合适的机器学习模型并用训练数据进行训练。
- **模型评估**:使用测试数据评估模型的性能,确保模型的泛化能力。
- **模型部署和应用**:将训练好的模型部署到生产环境中,用于实际的情感分析任务。
### 2.3.2 监督学习与无监督学习在情感分析中的应用
机器学习在情感分析中的两种常见方法是监督学习和无监督学习。
- **监督学习**:需要有大量已标注的数据集,通过训练模型来识别数据中情感极性的模式。例如,使用朴素贝叶斯或支持向量机(SVM)进行情感分类。
- **无监督学习**:用于当缺少标注数据时,通过聚类和主题模型等技术来发现文本数据中潜在的情感模式。例如,使用潜在语义分析(LSA)或潜在狄利克雷分配(LDA)进行情感聚类。
在监督学习中,模型的学习目标是准确地预测标签。而在无监督学习中,目标是发现数据的内在结构,聚类算法可以用于将相似情感倾向的文本分组在一起。
为了更深入理解,下面提供一个简单的机器学习流程示例代码块,以说明情感分析中监督学习方法的实现:
```python
# 代码块:使用 scikit-learn 实现朴素贝叶斯情感分类器
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
# 假设 data 是一个包含文本数据的列表,labels 是对应的情感标签列表
data = [...]
labels = [...]
# 文本向量化
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(data)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.2)
# 初始化朴素贝叶斯分类器
nb_classifier = MultinomialNB()
# 训练分类器
nb_classifier.fit(X_train, y_train)
# 使用测试集进行预测
predictions = nb_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print(f"模型准确率: {accuracy:.2f}")
```
在上述代码中,我们首先导入了必要的库,然后使用`CountVectorizer`对文本数据进行向量化处理。接着,我们将数据集划分为训练集和测试集,使用朴素贝叶斯分类器进行训练,并在测试集上进行了预测。最后,我们计算了模型的准确率来评估其性能。
参数说明和逻辑分析:
- `CountVectorizer`: 将文本数据转换为词频矩阵。
- `train_test_split`: 用于将数据集分为训练集和测试集,确保模型的泛化能力。
- `MultinomialNB`: 是一种基于概率的分类器,特别适用于特征值为离散型变量的分类问题,如文本数据。
- `accuracy_score`: 用于评估模型的准确率。
请注意,以上代码仅作为示例,实际应用中需要更复杂的特征工程、模型选择和调优过程。此外,实际情感分析项目可能涉及更高级的技术和模型,如词嵌入和深度学习模型,以及更细粒度的调优和验证过程。
# 3. Python情感分析实践环境搭建
## 3.1 Python环境安装与配置
### 3.1.1 Python安装指南
为了在计算机上开始进行情感分析的实验,第一步是确保有一个Python环境。Python是一种解释型、交互式、面向对象的编程语言,它提供了广泛的库支持,使其在数据分析、机器学习和人工智能领域得到了广泛应用。
安装Python的步骤相对直接。首先,访问Python官方网站下载适合您操作系统的最新版本的Python。推荐下载Python 3.x版本,因为它相比于Python 2.x版本得到了更好的支持和更广泛的应用。
在Windows系统中,下载安装器后,双击运行并遵循安装向导的步骤。确保在安装过程中勾选“Add Python to PATH”的选项,这样可以在命令行中直接调用Python。
在MacOS和Linux系统中,通常可以使用包管理器来安装Python,这可能已经预装了Python。在Mac上,可以使用Homebrew,而在多数Linux发行版中,可以使用apt、yum或其他包管理工具。
安装完成后,可以在命令行中输入以下指令来验证Python是否安装成功:
```bash
python --version
# 或者对于Python 3.x
python3 --version
```
确保输出的版本号是你所安装的版本。如果系统返回了错误信息,可能需要检查环境变量配置或重新安装Python。
### 3.1.2 虚拟环境的创建与管理
在进行Python开发时,推荐使用虚拟环境来隔离不同项目的依赖包和版本,以避免版本冲突和其他潜在问题。Python的虚拟环境管理工具有很多,如`virtualenv`、`venv`或`conda`等。
使用`venv`(Python 3.3+自带的虚拟环境模块)创建虚拟环境的步骤如下:
1. 打开命令行工具。
2. 创建一个名为`venv`的文件夹,该文件夹将包含虚拟环境(通常该文件夹会与项目代码一同被版本控制系统跟踪):
```bash
mkdir project_name
cd project_name
python3 -m venv venv
```
3. 激活虚拟环境(在Windows上):
```cmd
venv\Scripts\activate
```
(在Unix或MacOS上):
```bash
source venv/bin/activate
```
一旦激活了虚拟环境,所有使用pip安装的包都会被安装在这个隔离的环境中,不会影响到系统的全局Python安装或其它项目。要退出虚拟环境,可以使用以下命令:
```bash
deactivate
```
这将停止虚拟环境,让你回到系统默认的Python环境。
## 3.2 必要的Python库与框架
### 3.2.1 安装和使用NLTK库
自然语言处理(NLP)是情感分析的重要基石。NLTK(Natural Language Toolkit)是一个强大的Python库,用于处理人类语言数据。它提供了许多文本处理的工具和库,非常适合文本挖掘和情感分析任务。
首先,你需要安装NLTK。可以通过pip,Python的包管理工具来安装:
```bash
pip install nltk
```
安装完成后,就可以在Python代码中导入并使用它了:
```python
import nltk
nltk.download('punkt')
```
上面的代码将下载`punkt` tokenizer models,这是一个非常有用的预处理文本工具,用于将文本分割成句子和词汇。
现在,你已经具备了进行基本文本预处理和分析的能力。例如,你可以使用NLTK将一段文本分割成句子:
```python
from
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中自然语言处理算法的应用。它提供了对文本预处理技巧的全面指南,包括 5 种必学方法,旨在帮助读者提升他们的文本处理能力。该专栏涵盖了从文本清理和分词到词干提取和词性标注等关键技术。通过这些实用方法,读者将能够更有效地处理文本数据,为自然语言处理任务奠定坚实的基础。本专栏旨在为初学者和经验丰富的从业者提供宝贵的见解,帮助他们掌握 Python 中文本预处理的艺术,从而提高他们的自然语言处理项目的质量和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
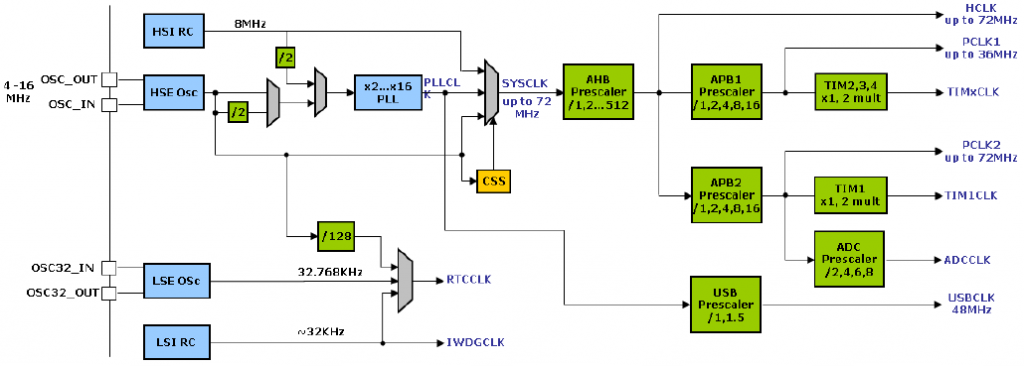
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
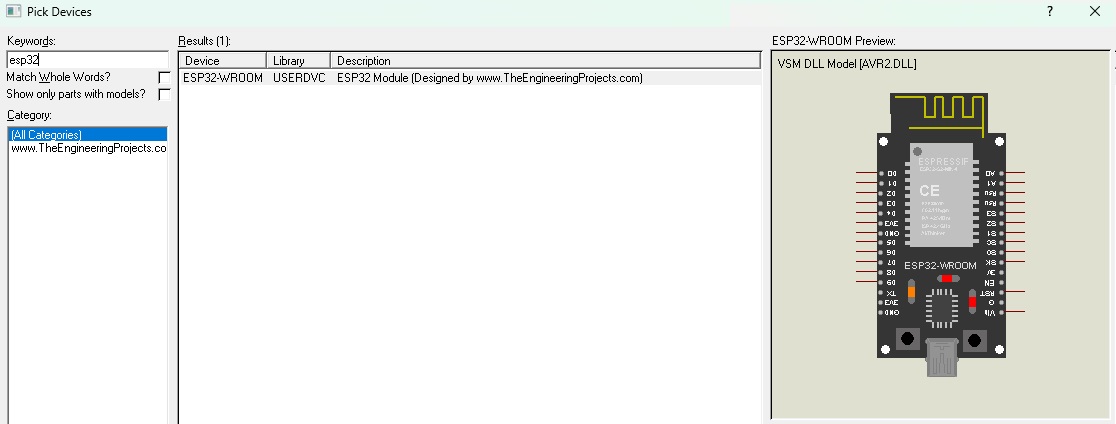
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )