CarbonData实时查询引擎的数据加载与分区
发布时间: 2023-12-19 07:55:13 阅读量: 9 订阅数: 19 
# 第一章:CarbonData实时查询引擎简介
## 1.1 CarbonData实时查询引擎概述
CarbonData实时查询引擎是一种开源的大数据存储与查询引擎,旨在提供高效的实时查询和分析功能。它基于列式存储和索引加速技术,可以快速执行复杂的OLAP查询,适用于大规模的数据仓库和分析系统。
## 1.2 CarbonData实时查询引擎的特点与优势
CarbonData实时查询引擎具有以下特点与优势:
- 高性能查询:通过列式存储和多维索引技术,实现快速的查询响应。
- 数据压缩与编码:采用多种数据压缩与编码技术,减少存储空间占用。
- 多维数据模型:支持复杂的多维数据模型,满足多样化的分析需求。
- 实时数据加载:支持实时数据加载,提供实时查询能力。
- 与生态系统集成:能与常见的大数据生态系统(如Spark、Flink等)进行无缝集成,实现多样化的数据处理需求。
## 1.3 CarbonData实时查询引擎在大数据领域的应用与前景
CarbonData实时查询引擎在大数据领域有着广泛的应用前景,特别适用于数据仓库、实时分析以及BI系统等场景。随着大数据技术的不断演进,CarbonData实时查询引擎将在实时数据处理与分析领域发挥越来越重要的作用。
### 二、CarbonData实时查询引擎的数据加载流程
在CarbonData实时查询引擎中,数据加载是非常关键的一环,包括数据准备阶段、数据加载阶段和数据更新与删除操作的实时处理。接下来我们将详细介绍CarbonData实时查询引擎的数据加载流程。
#### 2.1 数据准备阶段:数据源接入与数据预处理
在数据加载之前,首先需要将数据源接入到CarbonData实时查询引擎中。数据源可以是关系型数据库、Hive数据仓库、HDFS等。CarbonData支持通过Spark SQL提供的数据源接口读取数据,并且还可以进行数据预处理,如数据清洗、数据转换等操作。
```java
// 示例Java代码:使用Spark SQL将关系型数据库中的数据读取并预处理
Dataset<Row> data = spark.read()
.format("jdbc")
.option("url", "jdbc:postgresql://localhost:5432/database")
.option("dbtable", "table")
.option("user", "user")
.option("password", "password")
.load();
data = data.filter("column1 > 0");
data = data.withColumn("new_column", functions.concat(data.col("column2"), lit("_suffix")));
data.write()
.format("carbondata")
.option("tableName", "carbon_ta
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
CarbonData实时查询引擎是一个强大而高效的数据处理引擎,可在大数据分析环境中实现实时查询和分析。本专栏详细介绍了CarbonData实时查询引擎的架构设计、数据模型与存储格式、数据加载与分区等关键方面。此外,还涵盖了查询优化与执行、数据压缩与编码、索引设计与优化、高可用与容灾设计等多个重要主题。专栏还介绍了CarbonData实时查询引擎与Apache Spark和Apache Flink的集成,以及与流处理技术的融合。此外,还深入讨论了数据仓库中CarbonData实时查询引擎的角色和在实时大数据分析中的应用。专栏还涵盖了数据压缩原理与方法、查询执行计划解析、存储与计算分离架构、数据分布与复制机制以及事务处理与一致性保证等方面。通过阅读本专栏,读者将了解到CarbonData实时查询引擎的核心概念、功能特点以及在实践中的应用技巧,从而提升大数据分析的效率和性能。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB散点图:使用散点图进行信号处理的5个步骤
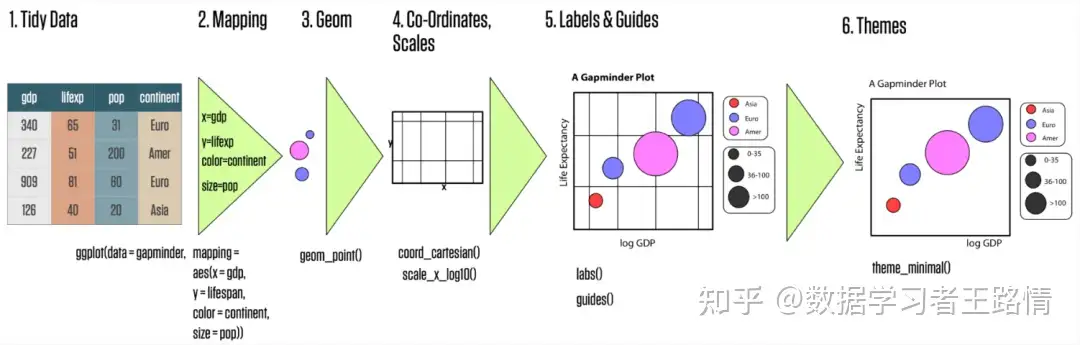
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
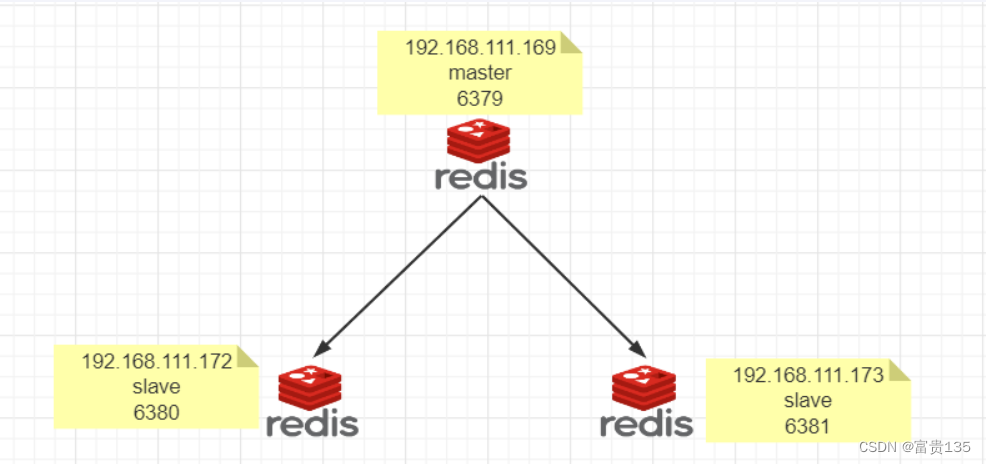
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
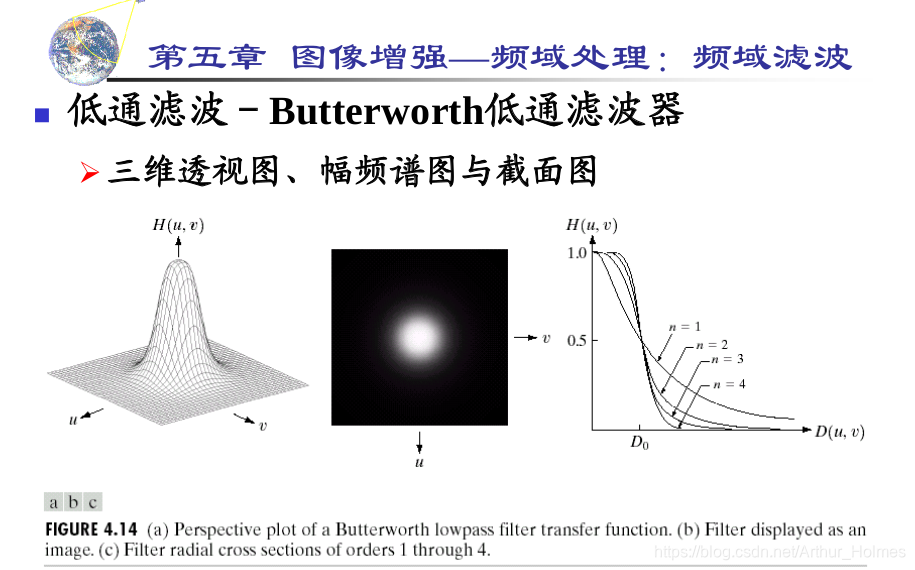
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )