Shell脚本初步:编写简单的UNIX命令脚本
发布时间: 2023-12-29 08:03:52 阅读量: 58 订阅数: 39 
# 章节一:引言
## 1.1 什么是Shell脚本?
Shell脚本是一种用来自动化执行一系列Unix命令的脚本语言。它是由一系列命令和控制结构组成的文本文件,通过Shell解释器执行。
## 1.2 Shell脚本的作用和优势
Shell脚本可以用于批量处理文件、系统管理、自动化任务等多种场景。其优势在于方便快捷、易于调试和修改,能够提高工作效率。
## 1.3 学习Shell脚本的必要性
学习Shell脚本可以使我们更好地管理和控制Unix系统,提高工作效率,同时也是作为一个IT从业者必备的基本技能之一。
### 2. 章节二:入门指南
Shell脚本的入门指南将以基本语法、编写第一个Unix命令脚本以及运行和测试Shell脚本为主要内容。
#### 2.1 Shell脚本的基本语法
Shell脚本是一种用来自动化执行一系列Unix命令的脚本程序。它可以包含变量、控制结构、函数等基本元素。Shell脚本的基本语法主要包括:
- 注释:以“#”开头的内容为注释,用于解释脚本的功能和作用。
- 变量:使用等号“=”来给变量赋值,变量名不需要事先声明。
- 控制结构:包括条件判断和循环控制,如if-else、for、while等。
- 函数:使用“function”关键字定义函数,函数体内可以包含一系列命令。
```shell
# 这是一个Shell脚本的基本语法示例
#!/bin/bash # 指定解释器,一般使用/bin/bash
# 这是一个Shell脚本示例
# 定义变量
name="Shell脚本"
echo "Hello, $name"
# 控制结构示例
if [ 1 -eq 1 ]; then
echo "条件成立"
fi
# 函数示例
function sayHello() {
echo "Hello, $1"
}
# 调用函数
sayHello "World"
```
#### 2.2 编写第一个Unix命令脚本
让我们来编写一个简单的Unix命令脚本,该脚本将输出当前系统中的文件和文件夹列表,并统计它们的数量。
```shell
#!/bin/bash
# 输出文件和文件夹列表
echo "当前目录下的文件和文件夹有:"
ls
# 统计文件和文件夹的数量
file_count=$(ls | wc -l)
echo "文件和文件夹的数量为:$file_count"
```
#### 2.3 运行和测试Shell脚本
编写好Shell脚本后,我们需要运行并测试它的功能是否正确。在终端中,通过以下命令运行我们编写的Unix命令脚本:
```shell
bash script_name.sh
```
其中,`script_name.sh`是我们编写的脚本文件名。执行后,将会输出当前目录下的文件和文件夹列表,并统计它们的数量。
以上是Shell脚本的入门指南,包括基本语法、编写第一个Unix命令脚本以及运行和测试Shell脚本。希望对你有所帮助!
### 3. 章节三:Unix命令基础
Unix命令是Shell脚本中常用的操作工具,掌握Unix命令基础对于编写Shell脚本至关重要。在本章中,我们将介绍常用的Unix命令、如何在Shell脚本中使用Unix命令以及参数和选项的使用方法。
#### 3.1 了解常用的Unix命令
常用的Unix命令包括但不限于:
- `ls`:列出目录内容
- `cd`:切换目录
- `pwd`:显示当前工作目录
- `mkdir`:创建新目录
- `rm`:删除文件或目录
- `cp`:复制文件
- `mv`:移动文件
- `cat`:连接文件并打印到标准输出设备
- `grep`:文本搜索
- `echo`:在标准输出设备上显示字符串
#### 3.2 如何在Shell脚本中使用Unix命令
在Shell脚本中,可以直接通过命令行的方式调用Unix命令,也可以将多个命令组合成一个脚本文件进行执行。例如,以下是一个简单的Shell脚本示例,用于列出当前目录下的所有文件:
```bash
#!/bin/bash
# 这是一个简单的Shell脚本示例
echo "当前目录下的文件列表:"
ls
```
#### 3.3 参数和选项的使用方法
Unix命令通常可以接受参数和选项,以实现不同的功能。在Shell脚本中,可以通过特定的语法传递参数和选项给Unix命令。例如,以下是一个带参数的Shell脚本示例,用于在指定目录下创建新的子目录:
```bash
#!/bin/bash
# 这是一个带参数的Shell脚本示例
if [ $# -eq 1 ]; then
mkdir $1
echo "目录 $1 创建成功!"
else
echo "Usage: $0 [目录名]"
fi
```
以上内容涵盖了Unix命令基础的介绍、在Shell脚本中使用Unix命令的方法以及参数和选项的使用技巧。通过学习本章内容,读者将掌握基本的Unix命令操作和在Shell脚本中的应用方法。
### 章节四:变量和控制结构
在本章中,我们将介绍Shell脚本中的变量和控制结构的基本知识,这对于编写复杂的脚本非常重要。
#### 4.1 基本变量类型和赋值
Shell脚本中的变量可以用于存储数据或值,并且不需要事先声明变量的类型。常见的变量类型包括:
- 字符串:使用单引号或双引号括起来的文本
- 整数:不需要特别声明,直接赋值即可
- 数组:使用以空格分隔的多个值
下面是一个简单的变量赋值示例:
```shell
#!/bin/bash
# 字符串变量
name='John Doe'
# 整数变量
age=25
# 数组变量
fruits=(apple banana orange)
```
#### 4.2 如何在Shell脚本中使用变量
在Shell脚本中,可以通过`$`符号来引用变量的值。另外,也可以使用`${}`来明确变量的边界。例如:
```shell
#!/bin/bash
# 使用变量
echo "My name is $name and I am ${age} years old."
# 数组变量的使用
echo "I like eating ${fruits[0]}"
```
#### 4.3 条件判断和循环控制
除了变量之外,控制结构也是Shell脚本中必不可少的一部分。条件判断和循环控制使得脚本更加灵活和功能强大。下面是一个简单的条件判断和循环控制的示例:
```shell
#!/bin/bash
# 条件判断
if [ $age -gt 18 ]; then
echo "成年人"
else
echo "未成年人"
fi
# 循环控制
for fruit in ${fruits[@]}; do
echo "I like eating $fruit"
done
```
本章内容介绍了Shell脚本中的变量和控制结构的基本知识,包括变量的赋值和引用以及条件判断和循环控制的使用方法。这对于进一步学习和编写复杂的Shell脚本非常重要。
### 章节五:函数和文件操作
在这一章节中,我们将学习如何在Shell脚本中编写和调用函数,以及如何进行文件的操作和处理。这些内容将为你提供更多的工具和技巧,帮助你编写更加复杂和实用的Shell脚本。
#### 5.1 自定义函数的编写和调用
在Shell脚本中,可以通过关键字 `function` 或者直接定义函数名来创建函数。下面是一个简单的示例,展示了如何编写和调用一个函数:
```bash
#!/bin/bash
# 定义一个简单的函数
my_function() {
echo "这是一个自定义的函数"
}
# 调用函数
my_function
```
在上面的示例中,我们定义了一个名为 `my_function` 的函数,然后在脚本中调用了这个函数。运行脚本后,函数内部的代码将被执行,并输出 "这是一个自定义的函数"。
#### 5.2 文件处理命令与操作
Shell脚本可以通过一系列的文件处理命令来对文件进行操作,比如创建、复制、删除、重命名等。下面是一个简单的示例,展示了如何在Shell脚本中使用`touch`和`rm`命令来创建和删除文件:
```bash
#!/bin/bash
# 使用touch命令创建一个新文件
touch example.txt
# 使用rm命令删除文件
rm example.txt
```
在上面的示例中,我们使用`touch`命令创建了一个名为 `example.txt` 的新文件,然后使用`rm`命令删除了这个文件。
#### 5.3 文件输入输出重定向
在Shell脚本中,可以使用输入输出重定向符号 `<` 和 `>` 来控制命令的输入和输出。下面是一个简单的示例,展示了如何将命令的输出重定向到文件中:
```bash
#!/bin/bash
# 将命令的输出重定向到文件
ls > files_list.txt
```
在上面的示例中,我们使用`ls`命令列出当前目录下的文件,并将输出重定向到名为 `files_list.txt` 的文件中。
通过学习自定义函数的编写和调用,文件处理命令与操作,以及文件输入输出重定向,你将能够更灵活地处理Shell脚本中的函数和文件操作,为实际的Shell脚本编写提供更多的可能性。
### 章节六:实战案例分析
在本章中,我们将通过实际案例来应用Shell脚本,从而更好地理解和掌握Shell脚本的编写和运行。
#### 6.1 编写一个简单的系统备份脚本
在这一部分,我们将编写一个简单的系统备份脚本,通过该脚本可以实现对指定目录的备份操作。在这个案例中,我们将讲解如何使用Shell脚本结合Unix命令来实现系统备份功能,并且探讨一些备份过程中可能遇到的问题以及解决方案。
```bash
#!/bin/bash
# 定义备份目标目录
backup_dir="/path/to/backup"
# 创建备份目录
mkdir -p $backup_dir
# 备份指定目录
source_dir="/path/to/source"
backup_file="backup_$(date +%Y%m%d).tar.gz"
tar -zcvf $backup_dir/$backup_file $source_dir
# 备份完成提示
echo "备份完成: $backup_file 已保存到 $backup_dir 目录"
```
**注释:**
- `#!/bin/bash` 表示使用bash解释器来执行脚本。
- `backup_dir` 为备份目标目录的路径。
- 使用`mkdir -p`命令创建备份目录,`-p`选项表示递归创建目录。
- `source_dir` 为需要备份的源目录路径。
- `backup_file` 为备份文件的名称,使用当前日期作为文件名的一部分。
- `tar -zcvf`命令用于将指定目录打包并进行压缩。
- 最后打印提示信息,说明备份的完成情况。
**代码总结:**
该脚本首先创建了一个备份目录,然后使用`tar`命令对指定目录进行打包压缩,并将压缩文件保存到备份目录中,最后输出备份完成的提示信息。
**结果说明:**
当执行该脚本后,源目录的文件将被打包压缩,并保存到指定的备份目录中,同时在终端中会输出备份完成的提示信息。
#### 6.2 分析一个实际的Shell脚本示例
在这一部分,我们将分析一个实际的Shell脚本示例,通过对脚本的逐行解析来理解Shell脚本的编写和运行过程,加深对Shell脚本的理解和应用。
#### 6.3 实战演练:应用Shell脚本提高工作效率
在这一部分,我们将结合实际工作场景,介绍如何应用Shell脚本来提高工作效率。通过实战演练,我们将展示Shell脚本在自动化执行任务、批量处理文件、简化操作流程等方面的应用,帮助读者更好地掌握Shell脚本的实际应用技巧。
以上是关于实战案例分析的内容,希望能够帮助你更好地理解和应用Shell脚本。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏致力于探索UNIX操作系统的方方面面,从基础入门到高阶应用,涵盖文件系统管理、Shell编程、软件安装与包管理、网络编程、性能优化、数据备份与还原、网络安全等诸多主题。首先从UNIX基础入门开始,介绍文件系统与命令行操作,以及Shell脚本的编写与应用。随后深入探讨UNIX环境下的软件安装与包管理、文件权限管理、性能优化与调整,以及网络编程基础与高阶应用。同时,专栏还涵盖了文件操作进阶、并发编程、数据备份与还原、性能监控与故障排查策略、日志管理与分析等领域。此外,还将介绍Shell编程进阶技巧、正则表达式的威力、网络安全与防护策略、高级文件系统管理以及UNIX操作系统内核等内容。通过本专栏,读者将全面了解UNIX环境下的各项技术,并掌握其在实际工作中的应用与操作技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EmuELEC全面入门与精通】:打造个人模拟器环境(7大步骤)

# 摘要
EmuELEC是一款专为游戏模拟器打造的嵌入式Linux娱乐系统,旨在提供一种简便、快速的途径来设置和运行经典游戏机模拟器。本文首先介绍了EmuELEC的基本概念、硬件准备、固件获取和初步设置。接着,深入探讨了如何定制EmuELEC系统界面,安装和配置模拟器核心,以及扩展其功能。文章还详细阐述了游戏和媒体内容的管理方法,包括游戏的导入、媒体内容的集成和网络功能的
【TCAD仿真流程全攻略】:掌握Silvaco,构建首个高效模型
# 摘要
本文首先介绍了TCAD仿真和Silvaco软件的基础知识,然后详细讲述了如何搭建和配置Silvaco仿真环境,包括软件安装、环境变量设置、工作界面和仿真
【数据分析必备技巧】:0基础学会因子分析,掌握数据背后的秘密
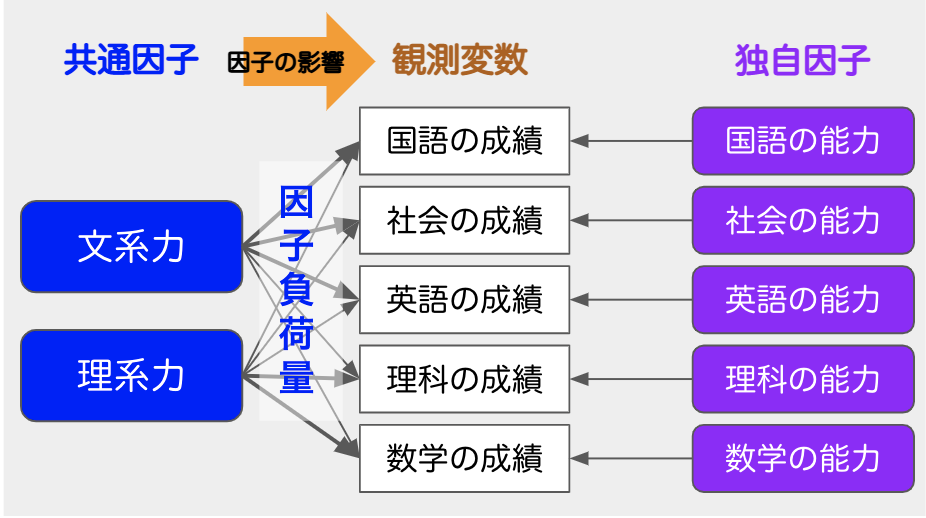
# 摘要
因子分析是一种强有力的统计方法,被广泛用于理解和简化数据结构。本文首先概述了因子分析的基本概念和统计学基础,包括描述性统计、因子分析理论模型及适用场景。随后,文章详细介绍了因子分析的实际操作步骤,如数据的准备、预处理和应用软件操作流程,以及结果的解读与报告撰写。通过市场调研、社会科学统计和金融数据分析的案例实战,本文展现了因子分析在不同领域的应用价值。最后,文章探讨了因子分析
【树莓派声音分析宝典】:从零开始用MEMS麦克风进行音频信号处理

# 摘要
本文详细介绍了基于树莓派的MEMS麦克风音频信号获取、分析及处理技术。首先概述了MEMS麦克风的基础知识和树莓派的音频接口配置,进而深入探讨了模拟信号数字化处理的原理和方法。随后,文章通过理论与实践相结合的方式,分析了声音信号的属性、常用处理算法以及实际应用案例。第四章着重于音频信号处理项目的构建和声音事件的检测响应,最后探讨了树莓派音频项目的拓展方向、
西门子G120C变频器维护速成

# 摘要
西门子G120C变频器作为工业自动化领域的一款重要设备,其基础理论、操作原理、硬件结构和软件功能对于维护人员和使用者来说至关重要。本文首先介绍了西门子G120C变频器的基本情况和理论知识,随后阐述了其硬件组成和软件功能,紧接着深入探讨了日常维护实践和常见故障的诊断处理方法。此外
【NASA电池数据集深度解析】:航天电池数据分析的终极指南
# 摘要
本论文提供了航天电池技术的全面分析,从基础理论到实际应用案例,以及未来发展趋势。首先,本文概述了航天电池技术的发展背景,并介绍了NASA电池数据集的理论基础,包括电池的关键性能指标和数据集结构。随后,文章着重分析了基于数据集的航天电池性能评估方法,包括统计学方法和机器学习技术的应用,以及深度学习在预测电池性能中的作用。此外,本文还探讨了数据可视化在分析航天电池数据集中的重要性和应用,包括工具的选择和高级可视化技巧。案例研究部分深入分析了NASA数据集中的故障模式识别及其在预防性维护中的应用。最后,本文预测了航天电池数据分析的未来趋势,强调了新兴技术的应用、数据科学与电池技术的交叉融合
HMC7044编程接口全解析:上位机软件开发与实例分析
# 摘要
本文全面介绍并分析了HMC7044编程接口的技术规格、初始化过程以及控制命令集。基于此,深入探讨了在工业控制系统、测试仪器以及智能传感器网络中的HMC7044接口的实际应用案例,包括系统架构、通信流程以及性能评估。此外,文章还讨论了HMC7044接口高级主题,如错误诊断、性能优化和安全机制,并对其在新技术中的应用前景进行了展望。
# 关键字
HMC7044;编程接口;数据传输速率;控制命令集;工业控制;性能优化
参考资源链接:[通过上位机配置HMC7044寄存器及生产文件使用](https://wenku.csdn.net/doc/49zqopuiyb?spm=1055.2635
【COMSOL Multiphysics软件基础入门】:XY曲线拟合中文操作指南
# 摘要
本文全面介绍了COMSOL Multiphysics软件在XY曲线拟合中的应用,旨在帮助用户通过高级拟合功能进行高效准确的数据分析。文章首先概述了COMSOL软件,随后探讨了XY曲线拟合的基本概念,包括数学基础和在COMSOL中的应用。接着,详细阐述了在COMSOL中进行XY曲线拟合的具体步骤,包括数据准备、拟合过程,
【GAMS编程高手之路】:手册未揭露的编程技巧大公开!
# 摘要
本文全面介绍了一种高级建模和编程语言GAMS(通用代数建模系统)的使用方法,包括基础语法、模型构建、进阶技巧以及实践应用案例。GAMS作为一种强大的工具,在经济学、工程优化和风险管理领域中应用广泛。文章详细阐述了如何利用GAMS进行模型创建、求解以及高级集合和参数处理,并探讨了如何通过高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )