InfluxDB与持续集成_持续部署(CI_CD)的集成
发布时间: 2023-12-24 17:47:52 阅读量: 12 订阅数: 26 
# 第一章:InfluxDB简介
## 1.1 InfluxDB概述
InfluxDB是一个开源的时序数据库,专为处理时间相关的数据而设计。它拥有高性能的写入和查询能力,适用于存储大量时间序列数据,例如应用指标、系统监控、传感器数据等。
## 1.2 InfluxDB的特点和优势
- 高性能写入:InfluxDB采用一种被称为TSM(Time-structured Merge Tree)的存储引擎,可实现大规模数据的高效写入和压缩存储。
- SQL-like查询语言:InfluxQL提供类似SQL的查询语法,可对时间序列数据进行灵活的查询和聚合操作。
- 高可用性和水平扩展:InfluxDB支持数据的自动分片和复制,可实现高可用性和水平扩展。
- 数据保留策略:可根据数据的时间跨度定义不同的数据保存策略,灵活管理数据的保存周期和存储成本。
## 1.3 InfluxDB在持续集成_持续部署中的应用价值
InfluxDB作为时序数据库,在持续集成和持续部署(CI_CD)中具有重要的应用价值。它可以用于存储和分析持续集成过程中产生的大量时间序列数据,如构建日志、测试结果、性能指标等。借助InfluxDB强大的数据存储和查询能力,可以实现对持续集成过程的监控、分析和优化,提升软件开发过程中的效率和质量。
## 第二章:持续集成和持续部署概述
2.1 持续集成(CI)原理和流程
2.2 持续部署(CD)概念及实施方式
2.3 CI_CD在软件开发中的重要性
### 第三章:InfluxDB与持续集成的集成
持续集成(Continuous Integration,CI)是一种软件开发实践,通过频繁地将代码集成到共享存储库中,然后自动执行构建和测试,以快速发现集成错误。持续集成的关键目标是使软件开发团队更加频繁地集成代码,从而减少集成问题,并快速发现和定位错误。在持续集成的流程中,监控和分析数据是至关重要的,而InfluxDB作为一个专注于时序数据的开源数据库,具有很好的适用性。
#### 3.1 InfluxDB在监控持续集成过程中的作用
InfluxDB可以用于存储持续集成过程中产生的大量时序数据,例如构建日志、测试结果、应用程序性能数据等。通过存储这些数据,可以实现对持续集成过程的全面监控,并能够快速定位问题,及时做出调整和优化。同时,InfluxDB的数据可视化和告警功能,能够帮助团队及时了解持续集成的状态,确保整个流程的顺利进行。
#### 3.2 InfluxDB如何与持续集成工具(例如Jenkins、Travis CI等)集成
##### 使用Python与InfluxDB集成Jenkins监控数据示例:
```python
import requests
import json
from influxdb import InfluxDBClient
# 从Jenkins API获取监控数据
jenkins_url = 'http://your-jenkins-url/api/json'
response = requests.get(jenkins_url)
data = json.loads(response.text)
# 解析数据并存储到InfluxDB
client = InfluxDBClient('your-influxdb-host', 8086, 'username', 'password', 'database')
json_body = [
{
"measurement": "jenkins_monitoring",
"tags": {
"job": "your-job-name"
},
"fields": {
"build_status": data['color'],
"build_number": data['lastBuild']['number']
}
}
]
client.write_points(json_body)
```
**代码说明:**
- 通过Jenkins API获取监控数据
- 使用InfluxDBClient连接InfluxDB数据库
- 将解析的数据存储到InfluxDB中
**结果说明:**
以上代码可以定期执行,将Jenkins的监控数据存储到InfluxDB中,并可以通过InfluxDB的查询和可视化功能实现对Jenkins监控数据的展示和分析。
#### 3.3 InfluxDB数据在持续集成中的实际应用案例
例如,团队可以利用InfluxDB存储的持续集成数据,实现构建时间趋势分析、测试覆盖率统计、构建成功率监控等功能。通过这些实际的应用案例,可以更好地了解InfluxDB在持续集成过程中的作用,以及如何通过InfluxDB提升持续集成的效率和质量。
以上是InfluxDB与持续集成的集成的章节内容,介绍了InfluxDB在监控持续集成过程中的作用,并以Python与Jenkins的集成为例进行了示范。
### 第四章:InfluxDB与持续部署的集成
持续部署是指软件开发团队通过自动化流程,将软件的新版本部署到生产环境中。在持续部署过程中,对于性能监控和数据分析的需求日益增加。本章将介绍如何通过InfluxDB实现持续部署流程中的性能监控和数据分析,以及InfluxDB如何与持续部署工具集成。
#### 4.1 InfluxDB对持续部署流程的支持和优化
在持续部署过程中,通常需要对应用程序在各个阶段的性能进行监控,以及对部署结果进行数据分析。InfluxDB作为一个专门用于时间序列数据存储和分析的数据库,能够对持续部署过程中产生的大量指标、日志和事件数据进行高效存储和快速查询,从而为持续部署流程提供支持。
另外,InfluxDB在数据写入和查询上的高性能特性,也能够优化持续部署过程中的数据收集和分析,保证数据的及时性和准确性。
#### 4.2 InfluxDB如何与持续部署工具(例如Docker、Kubernetes等)集成
##### 使用InfluxDB监控Docker容器性能
```python
# Python代码示例
import docker
from influxdb import InfluxDBClient
import datetime
# 连接Docker
client = docker.DockerClient(base_url='tcp://127.0.0.1:2376')
# 连接InfluxDB
influx_client = InfluxDBClient('localhost', 8086, 'root', 'root', 'mydb')
# 获取容器列表
containers = client.containers.list()
# 获取指定容器的CPU使用率和内存使用率
for container in containers:
stats = container.stats(stream=False)
cpu_usage = stats['cpu_stats']['cpu_usage']['total_usage']
cpu_limit = stats['cpu_stats']['cpu_quota']
mem_usage = stats['memory_stats']['usage']
mem_limit = stats['memory_stats']['limit']
# 写入InfluxDB
json_body = [
{
"measurement": "container_metrics",
"tags": {
"container_id": container.id,
"container_name": container.name
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 100%中奖
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏通过一系列详细的文章,全面介绍了InfluxDB的各个方面。InfluxDB简介与安装指南为读者提供了系统的入门指导,InfluxDB数据写入与查询入门指南和InfluxDB数据持久化与备份策略为读者解释了数据的输入和保存方法。专栏还重点介绍了InfluxDB的数据模型设计最佳实践和数据聚合与连续查询的方法。此外,通过与Telegraf和Kapacitor的集成,读者可以了解如何构建强大的监控系统、实时数据处理和警报功能。专栏还介绍了InfluxDB与Grafana和持续集成_持续部署(CI_CD)的集成,以及在物联网、日志与事件管理、区块链技术、数据湖架构、性能优化、金融领域和机器学习等不同领域中的应用。通过这个专栏,读者将全面掌握InfluxDB的知识和应用。
专栏目录
最低0.47元/天 解锁专栏
100%中奖
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘MATLAB矩阵索引机制:深入剖析线性索引和多维索引,解锁矩阵操作新境界

# 1. MATLAB矩阵基础与索引概念
MATLAB中的矩阵是一种基本数据结构,由有序排列的元素组成。每个元素都有一个唯一的位置,称为索引。理解索引概念对于有效地处理和操作矩阵至关重要。
MATLAB中矩阵的索引从1开始,而不是0。每个元素的索引由其在行和列中的位置确定。例如,在矩阵A中,元素A(2,3)表示位于第2行第3列的元素。
索引可以是标量(单个数字)、向量(数字列
MATLAB频谱分析:信号处理的秘密武器,18个实战案例从入门到精通
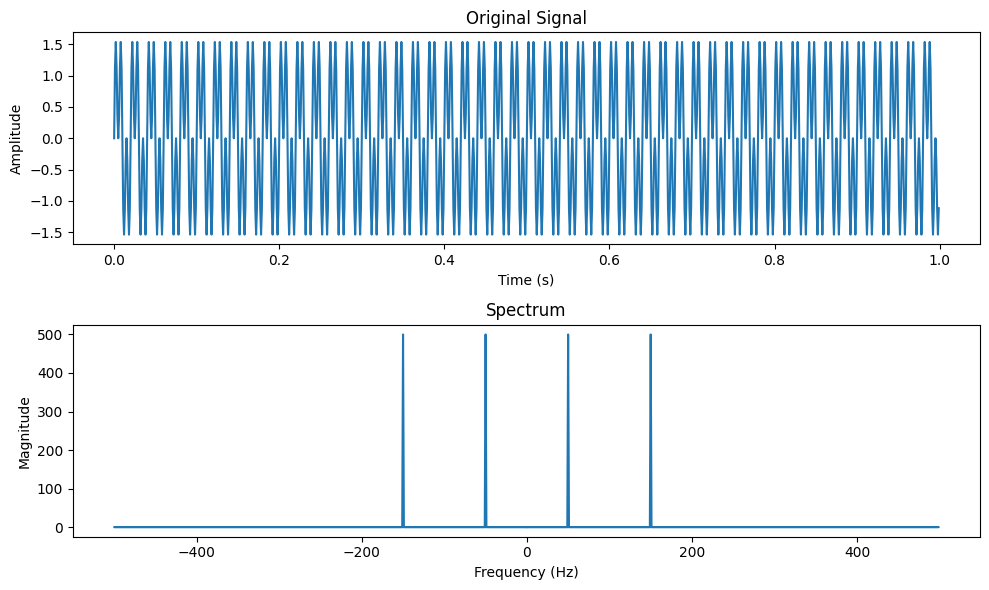
# 1. 频谱分析基础**
**1.1 频谱分析的概念和重要性**
频谱分析是一种将信号分解为其组成频率分量的技术。它可以揭示信号中隐藏的信息,例如信号的频率组成、能量分布和相位关系。频谱分析在信号处理、通信和医学等领域有着广泛的应用。
**1.2 傅里叶变换在频谱分析中的作用**
傅里叶变换是频谱分析的关键工具。它将时域信号转换为频域信号,其中信号的频率分
MATLAB性能优化:提升代码执行效率,释放计算潜力

# 1. MATLAB性能优化概述**
MATLAB性能优化旨在通过改进算法、数据结构和代码结构,提升MATLAB代码的执行效率。它涉及一系列技术,包括:
- **算法优化:**选择高效算法,优化算法参数。
- **数据结构优化:**选择合适的容器,优化数据访问。
MATLAB三维数组与增强现实:将数字世界与现实世界融合,开启交互新时代

# 1. MATLAB三维数组基础**
MATLAB三维数组是表示三维空间数据的强大工具。它允许用户存储和操作三维数据,例如点云、网格和体积数据。三维数组由三个索引组成,分别对应于x、y和z维度。
三维数组提供了多种操作,包括:
* **创建:**使用`zeros`、`ones`或`rand`函数创建新数组。
* **索引:**使用下标运算符
连接万物的力量:MATLAB 7.0在物联网中的应用

# 1. MATLAB 7.0概述
MATLAB 7.0是一款由MathWorks公司开发的高性能技术计算语言和交互式环境,广泛应用于科学研究、工程设计、数据分析和可视化等领域。它集成了强大的数学函数库、图形工具和编程语言,为用户提供了高效便捷的计算和可视化平台。
MATLAB 7.0在物联网领域具有独特的优势。它提供了丰富的工具和函数,可以轻松处理和分析物联网设备生成的海量数据。此外,MATLAB
MATLAB均值与时间序列分析:时间序列分析中均值的作用,把握数据趋势变化

# 1. 时间序列分析概述
时间序列分析是一种统计技术,用于分析和预测随着时间推移而变化的数据。它广泛应用于金融、经济、气象和医疗等领域。时间序列分析的关键目标是识别和理解数据中的模式和趋势,从而
MATLAB直线高级绘图技巧:探索直线绘制的更多可能性

# 1. 直线绘制的基础**
MATLAB 中的直线绘制是一个基本且强大的工具,可用于创建各种可视化。要绘制直线,可以使用 `line` 函数,它需要两个参数:直线的起点和终点。起点和终点可以是标量或向量,分别表示直线的 x 和 y 坐标。
```
% 绘制一条从 (1, 2) 到 (3, 4) 的直线
x = [1, 3];
y = [2, 4];
lin
MATLAB积分函数在科学研究中的应用:推进科学发现,探索未知领域

# 1. MATLAB积分函数概述**
MATLAB积分函数是一组强大的工具,用于计算积分。它们提供了各种方法来解决从简单到复杂的积分问题,包括数值积分和符号积分。通过使用这些函数,用户可以轻松地获得积分值,而无需手动执行繁琐的计算。
积分函数在科学研究和工程应用中有着广泛的应用。它们用于计算物理系统中的力、能量和热量,以及工程设计中的应力和应变。此外,积分函数在金融建模、数据
MATLAB求导与生物信息学:探索求导在生物信息学中的应用
# 1. MATLAB求导基础
MATLAB求导是利用MATLAB软件计算函数导数的过程。导数表示函数在特定点变化率,在生物信息学中具有广泛应用。
MATLAB求导函数包括:
- `diff()`: 计算离散函数的差分,即相邻元素之间的差值。
- `gradient()`: 计算多变量函数的梯度,即每个变量方向上的偏导数。
- `symbolic()`: 创建符号变量并进行符号求导。
求导在
MATLAB符号积分变换:积分变换的强大力量

# 1. 积分变换的基本概念**
积分变换是一种数学工具,用于将一个函数从一个域变换到另一个域。它在解决微分方程、积分方程和许多其
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
100%中奖
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )