快速定位问题:Tornado HTTPServer调试技巧与实战经验分享
发布时间: 2024-10-13 07:59:08 阅读量: 24 订阅数: 29 

# 1. Tornado HTTPServer简介
## 1.1 Tornado框架概述
Tornado是一个Python编写的应用框架,以其非阻塞IO和协程处理机制而闻名。它适用于需要长时间运行的web服务,并能有效处理大量的并发连接。
## 1.2 HTTPServer在Tornado中的作用
Tornado的HTTPServer是一个非阻塞的web服务器,它能够处理高并发的HTTP请求,适合构建长连接的应用场景。HTTPServer是Tornado框架的核心组件之一。
## 1.3 Tornado HTTPServer的特点
Tornado HTTPServer的特点包括非阻塞IO处理、协程支持、内置的WebSocket支持以及灵活的路由机制。这些特点使得Tornado非常适合用于实时web应用,如聊天应用和在线游戏。
# 2. 调试技巧
### 2.1 Tornado日志系统
#### 2.1.1 日志级别和配置
在Tornado框架中,日志系统是一个不可或缺的部分,它帮助开发者监控应用程序的运行状态,以及在出现问题时迅速定位问题源头。Tornado提供了灵活的日志系统配置,允许开发者根据需要设置不同的日志级别和输出格式。
Tornado的日志级别包括DEBUG, INFO, WARNING, ERROR和CRITICAL,它们分别对应不同的日志严重性。默认情况下,Tornado会将日志输出到控制台。我们可以通过修改Tornado的日志配置来改变日志的行为。
下面是一个示例代码,展示如何在Tornado应用中配置日志:
```python
import logging
from tornado.options import define, options
from tornado.web import Application
define("log_level", default="info", help="set log level (debug, info, warning, error, critical)")
class MainHandler(tornado.web.RequestHandler):
def get(self):
***("Accessing the main page.")
self.write("Hello, world")
def make_app():
return Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
options.parse_command_line()
logging.getLogger().setLevel(options.log_level.upper())
***("Starting the server.")
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
```
#### 2.1.2 日志分析技巧
日志分析是调试过程中的重要环节,通过分析日志记录,开发者可以了解应用程序的行为模式,以及在运行时遇到的任何错误或异常情况。以下是一些常用的日志分析技巧:
1. **过滤日志**:根据日志级别和时间范围过滤日志,快速定位感兴趣的记录。
2. **追踪问题**:对于复杂的系统问题,可以通过日志的时间戳和上下文信息来追踪问题的发展过程。
3. **统计分析**:对日志中的特定事件进行计数,比如错误发生次数,以了解问题的频率。
4. **关联分析**:将日志与其他监控数据相结合,比如系统负载、网络流量等,以发现潜在的相关性。
### 2.2 Tornado HTTPServer的异常处理
#### 2.2.1 常见异常类型及处理方法
在使用Tornado的HTTPServer时,我们可能会遇到各种异常。这些异常可以分为两大类:同步异常和异步异常。同步异常通常是在处理HTTP请求时直接抛出的,而异步异常则是在异步回调函数中抛出的。
**同步异常**的处理通常使用Python的`try-except`块来捕获和处理。例如:
```python
class MainHandler(tornado.web.RequestHandler):
def get(self):
try:
# 假设这里有可能抛出异常的代码
result = some_calculation()
self.write(result)
except Exception as e:
logging.error(f"Error occurred: {e}")
self.set_status(500)
self.finish("Internal Server Error")
```
**异步异常**的处理则需要使用`add_done_callback`方法来捕获。例如:
```python
import tornado.ioloop
import tornado.web
import tornado.gen
class AsyncHandler(tornado.web.RequestHandler):
@tornado.gen.coroutine
def get(self):
future = some_async_function()
try:
result = yield future
self.write(result)
except Exception as e:
logging.error(f"Async error occurred: {e}")
self.set_status(500)
self.finish("Internal Server Error")
```
#### 2.2.2 自定义异常处理机制
除了上述基本的异常处理方法,Tornado还允许开发者自定义异常处理机制。这可以通过注册一个全局的异常处理器来实现,该处理器可以拦截所有未被捕获的异常,并返回自定义的错误响应。
```python
class CustomHTTPErrorHandler(tornado.web.HTTPError):
def __init__(self, status_code, *args, **kwargs):
super().__init__(status_code, *args, **kwargs)
self.log_message = "%d: %s" % (status_code, str(args))
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
(r"/async", AsyncHandler),
], http_error_handlers={
404: CustomHTTPErrorHandler,
500: CustomHTTPErrorHandler,
})
app = make_app()
```
### 2.3 性能监控与分析
#### 2.3.1 内置性能分析工具
Tornado提供了一些内置的工具来帮助开发者监控和分析应用的性能。例如,`tornado.options`模块中的`set统计信息`功能可以用来收集HTTP请求的相关统计数据。
```python
import tornado.web
import tornado.ioloop
import tornado.options
from tornado.options import define, options
define("port", default=8888, help="run on the given port", type=int)
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
tornado.options.parse_command_line()
app = make_app()
app.listen(options.port)
tornado.ioloop.PeriodicCallback(
lambda: ***("Connections: %d Requests: %d", app.num_connections,
app.requests_per_second()), 1)
tornado.ioloop.IOLoop.current().start()
```
#### 2.3.2 第三方监控工具集成
除了内置的工具,Tornado也支持集成第三方监控工具,如Prometheus、Grafana等,以便进行更深入的性能监控和分析。
例如,要集成Prometheus,你可以使用Python的`prometheus_client`库来创建和暴露指标:
```python
from prometheus_client import start_http_server, Gauge
from tornado.ioloop import IOLoop
from tornado.web import Application
import tornado.options
gauges = {}
class MetricsHandler(tornado.web.RequestHandler):
def get(self):
for metric_name, metric in gauges.items():
self.write(f"{metric_name}: {metric}")
self.finish()
def start_metrics_server(port):
start_http_server(port)
***(f"Metrics server started on port {port}")
def make_app():
return tornado.web.Application([
(r"/metrics", MetricsHandler),
])
if __name__ == "__main__":
tornado.options.define('metrics_port', default=9090, type=int)
tornado.options.parse_command_line()
app = make_app()
app.listen(8888)
start_metrics_server(options.metrics_port)
gauge = Gauge('http_requests_total', 'HTTP requests total')
@tornado.ioloop.IOLoop.current().add_callback
def update():
gauge.inc(1) # Increment the counter for each request
tornado.ioloop.IOLoop.current().add_callback(update)
tornado.ioloop.IOLoop.current().start()
```
通过上述代码,我们创建了一个Prometheus指标,它会在每个HTTP请求时递增。然后我们启动了一个Prometheus监控服务器来收集这些指标。
以上内容为第二章:调试技巧的详细介绍。在本章节中,我们深入探讨了Tornado HTTPServer的调试技巧,包括日志系统、异常处理机制以及性能监控与分析的方法。这些技巧对于维护和优化Tornado应用至关重要,有助于开发者提升应用的稳定性和性能。
# 3. 问题诊断方法
## 3.1 请求处理流程分析
### 3.1.1 Tornado请求生命周期
在本章节中,我们将深入探讨Tornado框架中HTTPServer处理请求的生命周期,这是理解和诊断问题的基础。Tornado的请求生命周期从客户端发起请求开始,到服务器响应结束,中间经过多个处理阶段。
首先,客户端向Tornado HTTPServer发起一个HTTP请求,这触发了Tornado的`RequestHandler`类的`prepare`方法。这个方法是处理请求的第一步,通常用于一些预处理工作,比如验证用户认证令牌。
```python
class MainHandler(tornado.web.RequestHandler):
def prepare(self):
# 这里可以进行请求前的预处理,例如验证用户
pass
def get(self):
# 处理GET请求
self.write("Hello, world")
```
接下来是`options`、`head`、`get`、`post`等方法,这些方法根据HTTP请求的类型被调用。在这个阶段,开发者通常会根据业务逻辑处理请求,并生成相应的响应。最后,`on_finish`方法会被调用,这是请求

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 "Tornado HTTPServer 从入门到精通" 为题,深入探讨了 Tornado HTTPServer 框架的方方面面。从基础概念到高级技巧,从性能优化到源码解析,专栏涵盖了构建高性能 Web 服务所需的一切知识。读者将学习异步编程、RESTful API 开发、调试技巧、扩展性、框架选型、测试用例编写、性能监控、服务状态追踪、负载均衡和数据库交互等内容。通过循序渐进的讲解和实战案例,本专栏旨在帮助开发者掌握 Tornado HTTPServer 的核心技术,打造高效、可扩展且稳定的 Web 应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
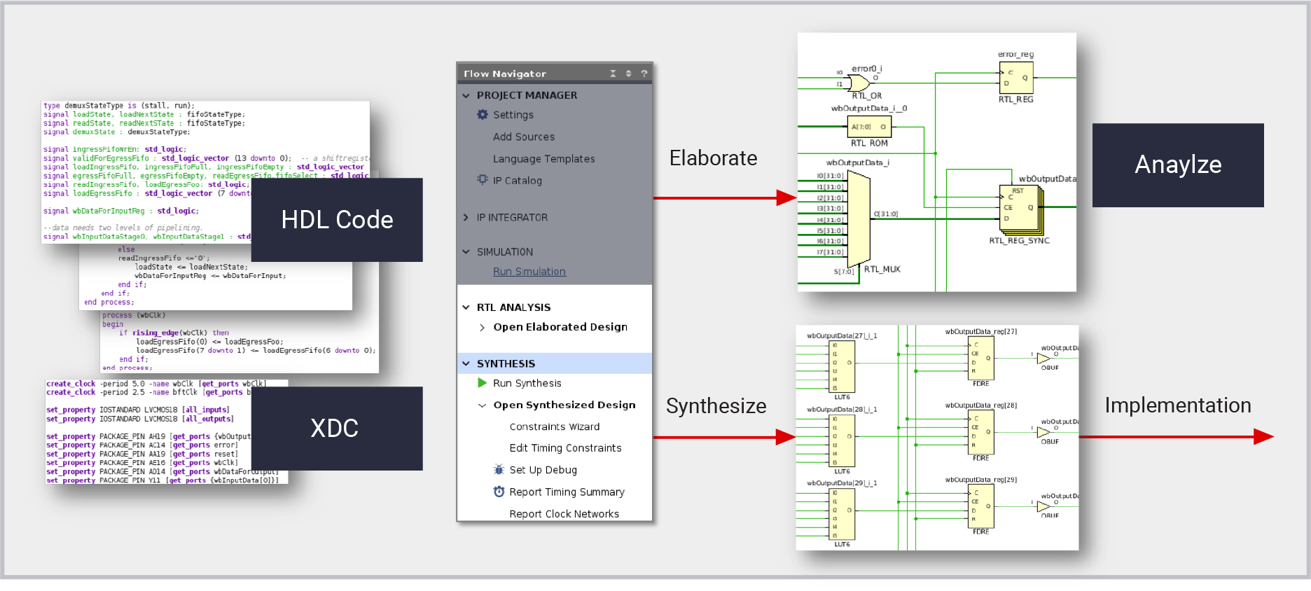
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
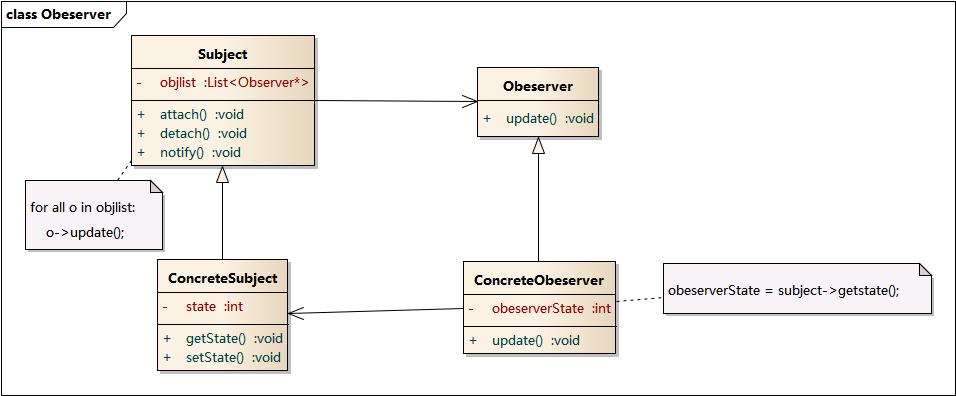
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
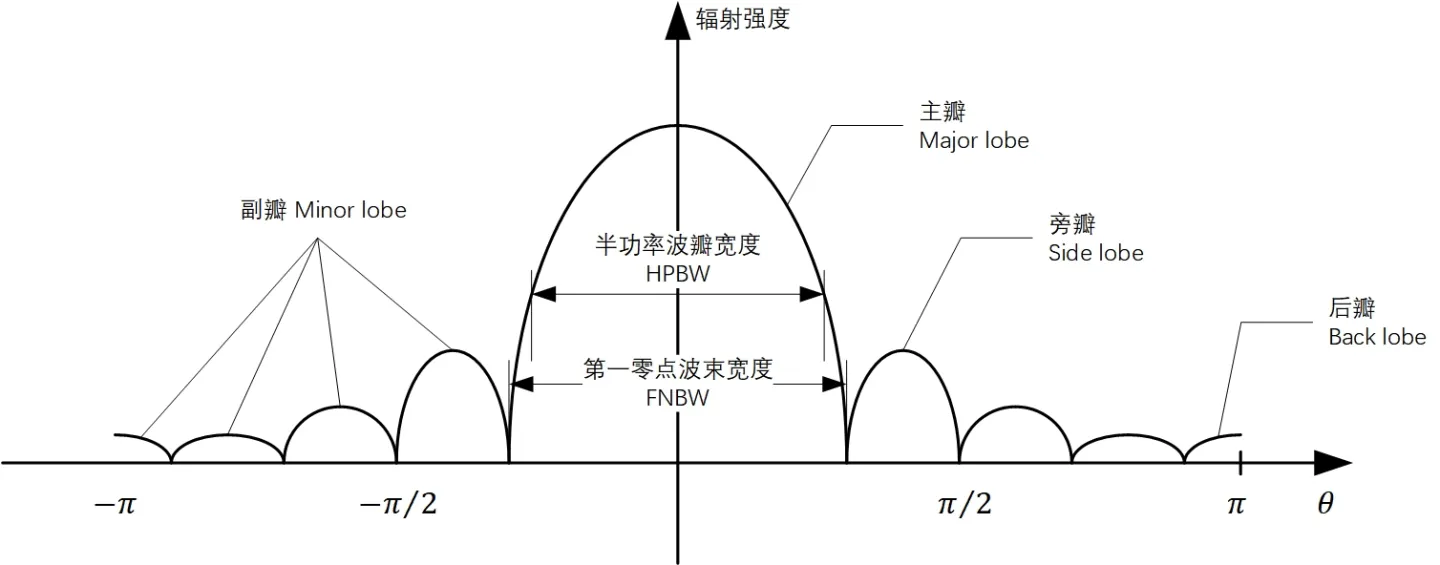
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )