揭秘高斯混合模型:从理论到实践,掌握机器学习中的关键技术
发布时间: 2024-07-11 19:20:59 阅读量: 78 订阅数: 37 

机器学习编程作业:高斯混合模型 .zip
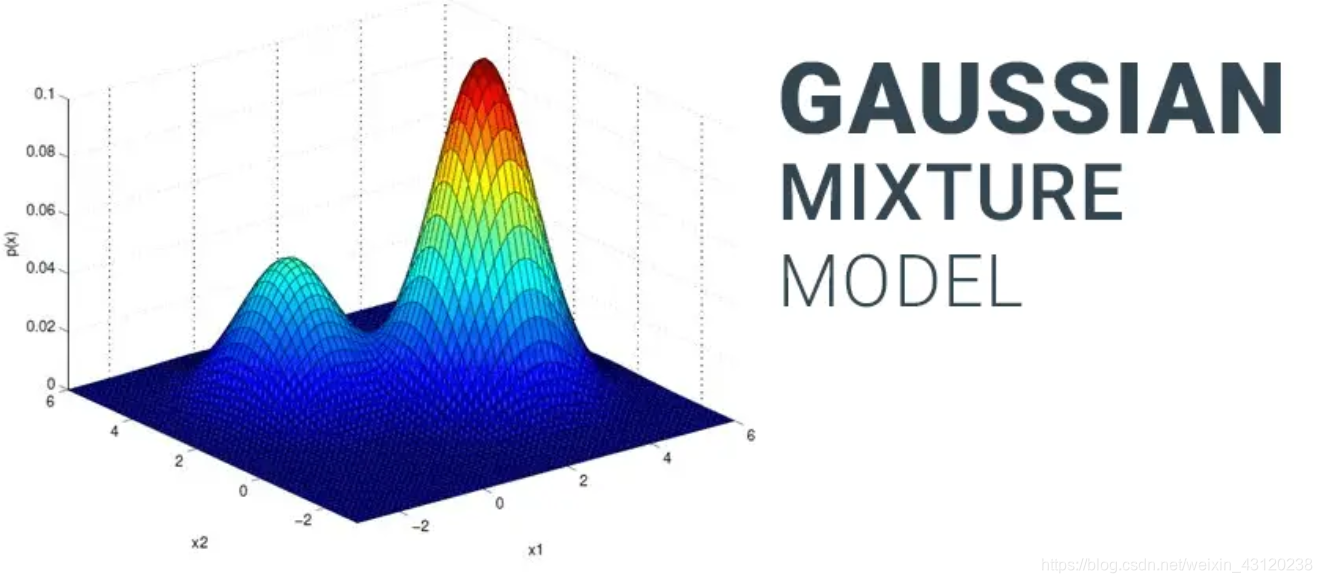
# 1. 高斯混合模型的理论基础
高斯混合模型(GMM)是一种概率模型,它假设数据是由多个高斯分布的混合而成的。每个高斯分布代表一个潜在的簇,数据点属于某个簇的概率由其到该簇中心的距离决定。
GMM 的数学表达式如下:
```
p(x) = ∑_k^K π_k N(x | μ_k, Σ_k)
```
其中:
* x 是数据点
* K 是簇的数量
* π_k 是第 k 个簇的先验概率
* μ_k 是第 k 个簇的均值向量
* Σ_k 是第 k 个簇的协方差矩阵
# 2. 高斯混合模型的编程实践
### 2.1 Python中高斯混合模型的实现
#### 2.1.1 模型的创建和训练
在Python中,我们可以使用scikit-learn库来创建和训练高斯混合模型。下面是一个示例代码:
```python
import numpy as np
from sklearn.mixture import GaussianMixture
# 生成模拟数据
data = np.random.randn(1000, 2)
# 创建高斯混合模型
model = GaussianMixture(n_components=3)
# 训练模型
model.fit(data)
```
**代码逻辑解读:**
* `GaussianMixture(n_components=3)`:创建了一个具有3个高斯分量的混合模型。
* `fit(data)`:使用数据训练模型。
#### 2.1.2 模型的参数估计
训练完成后,我们可以访问模型的参数,包括高斯分量的均值、协方差和混合系数。
```python
# 获取高斯分量的均值
means = model.means_
# 获取高斯分量的协方差
covariances = model.covariances_
# 获取混合系数
weights = model.weights_
```
**参数说明:**
* `means`:一个形状为`(n_components, n_features)`的数组,其中`n_components`是高斯分量的数量,`n_features`是数据的特征数量。
* `covariances`:一个形状为`(n_components, n_features, n_features)`的数组,其中`n_components`是高斯分量的数量,`n_features`是数据的特征数量。
* `weights`:一个形状为`(n_components,)`的数组,其中`n_components`是高斯分量的数量。
### 2.2 R中高斯混合模型的实现
#### 2.2.1 模型的创建和训练
在R中,我们可以使用`mclust`包来创建和训练高斯混合模型。下面是一个示例代码:
```r
library(mclust)
# 生成模拟数据
data <- rnorm(1000, 2)
# 创建高斯混合模型
model <- Mclust(data)
```
**代码逻辑解读:**
* `Mclust(data)`:创建了一个高斯混合模型,并使用数据对其进行训练。
#### 2.2.2 模型的评估和可视化
训练完成后,我们可以使用`mclust`包来评估模型并可视化结果。
```r
# 模型评估
summary(model)
# 可视化结果
plot(model, data)
```
**代码逻辑解读:**
* `summary(model)`:打印模型的摘要,包括BIC、AIC和轮廓系数等评估指标。
* `plot(model, data)`:绘制模型的轮廓图和数据点。
# 3.1 K-Means聚类与高斯混合模型聚类的比较
K-Means聚类和高斯混合模型聚类都是常用的聚类算法,但它们在原理、目标和适用场景上存在差异。
**原理**
* **K-Means聚类:**将数据点分配到K个簇中,使得每个数据点到其所属簇中心的距离最小。
* **高斯混合模型聚类:**假设数据点是由K个高斯分布产生的,并根据每个数据点属于每个分布的概率进行聚类。
**目标**
* **K-Means聚类:**找到K个簇,使得簇内数据点之间的相似度最大,簇间数据点之间的相似度最小。
* **高斯混合模型聚类:**找到K个高斯分布,使得这些分布的混合能够最好地拟合数据。
**适用场景**
* **K-Means聚类:**适用于数据点分布相对均匀,簇形状规则的场景。
* **高斯混合模型聚类:**适用于数据点分布不均匀,簇形状不规则的场景。
**优缺点**
| 特征 | K-Means聚类 | 高斯混合模型聚类 |
|---|---|---|
| 原理 | 硬聚类 | 软聚类 |
| 目标 | 最大化簇内相似度 | 最小化数据与分布之间的差异 |
| 适用场景 | 数据分布均匀,簇形状规则 | 数据分布不均匀,簇形状不规则 |
| 优势 | 计算简单,速度快 | 能够处理多维数据,鲁棒性强 |
| 劣势 | 对初始化敏感,容易陷入局部最优 | 模型复杂,计算量大 |
### 3.2 高斯混合模型聚类的算法流程
高斯混合模型聚类的算法流程主要包括以下两个步骤:
#### 3.2.1 EM算法
EM算法是一种用于求解最大似然估计的迭代算法。在高斯混合模型聚类中,EM算法用于估计模型的参数,即每个高斯分布的均值、协方差和混合系数。
EM算法的步骤如下:
1. **E步(期望步骤):**计算每个数据点属于每个高斯分布的概率。
2. **M步(最大化步骤):**使用E步计算的概率更新模型参数,使得模型的似然函数最大化。
3. **重复E步和M步:**直到模型参数收敛。
#### 3.2.2 变分推断
变分推断是一种近似推断方法,可以用于求解高斯混合模型的参数。变分推断的步骤如下:
1. **定义变分分布:**定义一个近似分布,该分布的参数与高斯混合模型的参数相关。
2. **最小化KL散度:**最小化变分分布与高斯混合模型分布之间的KL散度。
3. **更新模型参数:**使用变分分布的参数更新高斯混合模型的参数。
4. **重复步骤1-3:**直到模型参数收敛。
变分推断的优点是计算量比EM算法小,但其精度可能较低。
# 4. 高斯混合模型在异常检测中的应用
### 4.1 异常检测的概念和方法
异常检测是一种机器学习技术,用于识别与正常数据模式明显不同的数据点或事件。异常数据点可能表示错误、欺诈或其他需要进一步调查的事件。
异常检测方法可以分为两类:
* **无监督方法:**这些方法不依赖于标记的数据,而是使用统计技术来识别异常。
* **有监督方法:**这些方法使用标记的数据来训练模型,该模型可以识别异常。
### 4.2 高斯混合模型在异常检测中的优势
高斯混合模型在异常检测中具有以下优势:
#### 4.2.1 鲁棒性强
高斯混合模型对异常数据点具有鲁棒性,这意味着它们不太可能将异常点误认为正常点。这是因为高斯混合模型假设数据是从多个高斯分布中生成的,其中一个分布表示异常数据。
#### 4.2.2 能够处理多维数据
高斯混合模型可以处理多维数据,这使其适用于现实世界中的许多异常检测问题。例如,在金融欺诈检测中,可能需要考虑多个特征,例如交易金额、交易时间和交易地点。
### 4.3 高斯混合模型在异常检测中的应用流程
高斯混合模型用于异常检测的流程如下:
1. **数据预处理:**将数据标准化并处理缺失值。
2. **模型训练:**使用高斯混合模型训练数据,其中一个分布表示异常数据。
3. **异常分数计算:**对于每个数据点,计算其属于异常分布的概率。
4. **阈值设置:**设置一个阈值,将高于该阈值的概率视为异常。
5. **异常检测:**识别概率高于阈值的异常数据点。
### 4.4 代码示例
以下 Python 代码演示了如何使用高斯混合模型进行异常检测:
```python
import numpy as np
from sklearn.mixture import GaussianMixture
# 加载数据
data = np.loadtxt('data.csv', delimiter=',')
# 创建高斯混合模型
model = GaussianMixture(n_components=2)
# 训练模型
model.fit(data)
# 计算异常分数
scores = model.score_samples(data)
# 设置阈值
threshold = 0.5
# 识别异常
anomalies = data[scores < threshold]
# 打印异常
print(anomalies)
```
### 4.5 讨论
高斯混合模型在异常检测中是一个强大的工具,因为它能够处理多维数据并对异常数据点具有鲁棒性。然而,它也有一些局限性,例如:
* **对噪声敏感:**高斯混合模型对噪声敏感,这可能会导致误报。
* **需要手动设置阈值:**异常检测的阈值需要手动设置,这可能会影响检测结果。
尽管有这些局限性,高斯混合模型仍然是异常检测中一种流行且有效的技术。
# 5.2 高斯混合模型在自然语言处理中的应用
高斯混合模型在自然语言处理领域有着广泛的应用,特别是在文本分类和文本生成方面。
### 5.2.1 文本分类
文本分类是将文本文档分配到预定义类别中的任务。高斯混合模型可以用来构建文本分类器,通过将每个类别建模为一个高斯分布,并根据文档的特征向量计算其属于每个类别的概率。文档被分配到具有最高概率的类别。
```python
import numpy as np
from sklearn.mixture import GaussianMixture
# 加载文本数据
data = np.loadtxt('text_data.txt', delimiter=',')
# 创建高斯混合模型
model = GaussianMixture(n_components=3)
# 训练模型
model.fit(data)
# 预测文本类别
predictions = model.predict(data)
```
### 5.2.2 文本生成
文本生成是生成类似于人类语言的文本的任务。高斯混合模型可以用来构建文本生成器,通过将单词序列建模为一个高斯分布序列。生成器通过从分布中采样单词来生成文本。
```python
import numpy as np
from sklearn.mixture import GaussianMixture
# 加载文本数据
data = np.loadtxt('text_data.txt', delimiter=',')
# 创建高斯混合模型
model = GaussianMixture(n_components=3)
# 训练模型
model.fit(data)
# 生成文本
generated_text = ''
for i in range(100):
word = model.sample()[0]
generated_text += word + ' '
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
高斯模型专栏深入探讨了高斯分布及其在机器学习、计算机视觉、自然语言处理、医学影像、语音识别、推荐系统、社交网络分析、异常检测、时间序列分析、优化、控制理论、机器人学、航空航天、材料科学和能源工程等广泛领域的应用。专栏涵盖了高斯模型的理论基础、实际应用和最新突破,旨在揭开高斯分布的神秘面纱,解锁机器学习的强大潜力,并为各个领域的从业者提供深入的数学见解和实践指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件管理系统设计全攻略】:从入门到架构的终极指南
# 摘要
随着信息技术的飞速发展,软件管理系统成为支持企业运营和业务创新的关键工具。本文从概念解析开始,系统性地阐述了软件管理系统的需求分析、设计、数据设计、开发与测试、部署与维护,以及未来的发展趋势。重点介绍了系统需求分析的方法论、系统设计的原则与架构选择、数据设计的基础与高级技术、以及质量保证与性能优化。文章最后
【硬盘修复的艺术】:西数硬盘检测修复工具的权威指南(全面解析WD-L_WD-ROYL板支持特性)

# 摘要
本文深入探讨了硬盘修复的基础知识,并专注于西部数据(西数)硬盘的检测修复工具。首先介绍了西数硬盘的内部结构与工作原理,随后阐述了硬盘故障的类型及其原因,包括硬件与软件方面的故障。接着,本文详细说明了西数硬盘检测修复工具的检测和修复理论基础,以及如何实践安装、配置和
【sCMOS相机驱动电路信号完整性秘籍】:数据准确性与稳定性并重的分析技巧

# 摘要
本文针对sCMOS相机驱动电路信号完整性进行了系统的研究。首先介绍了信号完整性理论基础和关键参数,紧接着探讨了信号传输理论,包括传输线理论基础和高频信号传输问题,以及信号反射、串扰和衰减的理论分析。本文还着重分析了电路板布局对信号完整性的影响,提出布局优化策略以及高速数字电路的布局技巧。在实践应用部分,本文提供了信号完整性测试工具的选择,仿真软件的应用,
能源转换效率提升指南:DEH调节系统优化关键步骤
# 摘要
能源转换效率对于现代电力系统至关重要,而数字电液(DEH)调节系统作为提高能源转换效率的关键技术,得到了广泛关注和研究。本文首先概述了DEH系统的重要性及其基本构成,然后深入探讨了其理论基础,包括能量转换原理和主要组件功能。在实践方法章节,本文着重分析了DEH系统的性能评估、参数优化调整,以及维护与故障排除策略。此外,本文还介绍了DEH调节系统的高级优化技术,如先进控制策略应用、系统集成与自适应技术,并讨论了节能减排的实现方法。最后,本文展望了DEH系统优化的未来趋势,包括技术创新、与可再生能源的融合以及行业标准化与规范化发展。通过对DEH系统的全面分析和优化技术的研究,本文旨在为提
【AT32F435_AT32F437时钟系统管理】:精确控制与省电模式

# 摘要
本文系统性地探讨了AT32F435/AT32F437微控制器中的时钟系统,包括其基本架构、配置选项、启动与同步机制,以及省电模式与能效管理。通过对时钟系统的深入分析,本文强调了在不同应用场景中实现精确时钟控制与测量的重要性,并探讨了高级时钟管理功能。同时,针对时钟系统的故障预防、安全机制和与外围设备的协同工作进行了讨论。最后,文章展望了时
【MATLAB自动化脚本提升】:如何利用数组方向性优化任务效率
# 摘要
本文深入探讨MATLAB自动化脚本的构建与优化技术,阐述了MATLAB数组操作的基本概念、方向性应用以及提高脚本效率的实践案例。文章首先介绍了MATLAB自动化脚本的基础知识及其优势,然后详细讨论了数组操作的核心概念,包括数组的创建、维度理解、索引和方向性,以及方向性在数据处理中的重要性。在实际应用部分,文章通过案例分析展示了数组方向性如何提升脚本效率,并分享了自动化
现代加密算法安全挑战应对指南:侧信道攻击防御策略
# 摘要
侧信道攻击利用信息泄露的非预期通道获取敏感数据,对信息安全构成了重大威胁。本文全面介绍了侧信道攻击的理论基础、分类、原理以及实际案例,同时探讨了防御措施、检测技术以及安全策略的部署。文章进一步分析了侧信道攻击的检测与响应,并通过案例研究深入分析了硬件和软件攻击手段。最后,本文展望了未来防御技术的发展趋势,包括新兴技术的应用、政策法规的作用以及行业最佳实践和持续教育的重要性。
# 关键字
侧信道攻击;信息安全;防御措施;安全策略;检测技术;防御发展趋势
参考资源链接:[密码编码学与网络安全基础:对称密码、分组与流密码解析](https://wenku.csdn.net/doc/64
【科大讯飞语音识别技术完全指南】:5大策略提升准确性与性能

# 摘要
本论文综述了语音识别技术的基础知识和面临的挑战,并着重分析了科大讯飞在该领域的技术实践。首先介绍了语音识别技术的原理,包括语音信号处理基础、自然语言处理和机器学习的应用。随
【现场演练】:西门子SINUMERIK测量循环在多样化加工场景中的实战技巧
# 摘要
本文旨在全面介绍西门子SINUMERIK测量循环的理论基础、实际应用以及优化策略。首先概述测量循环在现代加工中心的重要作用,继而深入探讨其理论原理,包括工件测量的重要性、测量循环参数设定及其对工件尺寸的影响。文章还详细分析了测量循环在多样化加工场景中的应用,特别是在金属加工和复杂形状零件制造中的挑战,并提出相应的定制方案和数据处理方法。针对多轴机床的测量循环适配,探讨了测量策略和同步性问题。此外,本文还探讨了测量循环的优化方法、提升精确度的技巧,以及西门子SINUMERIK如何融合新兴测量技术。最后,本文通过综合案例分析与现场演练,强调了理论与实践的结合,并对未来智能化测量技术的发展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )