【VS Code编码问题】:中文乱码现象解决与策略探讨
发布时间: 2024-12-14 10:37:22 订阅数: 3 

永久解决VSCode终端中文乱码问题
参考资源链接:[解决VSCode运行程序中文乱码问题的步骤](https://wenku.csdn.net/doc/645e30dc95996c03ac47b95e?spm=1055.2635.3001.10343)
# 1. VS Code中文乱码现象概述
VS Code(Visual Studio Code)作为一款流行的源代码编辑器,广受IT开发者的喜爱。然而,在处理中文字符时,VS Code中文乱码现象时有发生,这不仅影响了代码的可读性,也给调试和协作带来了不便。中文乱码问题通常涉及到字符编码的不一致,包括但不限于操作系统、IDE环境配置、以及源代码文件本身编码格式的差异。为了解决这一问题,我们需要对VS Code中的编码环境进行配置,理解字符编码的基本知识,并掌握文件编码的自动检测与转换技巧。本章将对VS Code中文乱码现象做一概览,为读者揭示乱码问题的表象和根源。
# 2. VS Code编码环境配置
在本章中,我们将深入探讨如何在Visual Studio Code(VS Code)中正确配置编码环境,确保无论是开发者自己还是项目团队,都能拥有一个无乱码的工作环境。我们将从字符编码的基础知识开始,逐步介绍如何设置VS Code工作区,以及如何自动检测和转换文件编码,从而为编码问题的诊断和解决打下坚实的基础。
## 2.1 字符编码基础
### 2.1.1 字符编码的种类与特点
字符编码是计算机中用于表示字符的编码方式,它将字符映射到计算机能够理解的数字代码。以下是一些常见的字符编码种类及其特点:
- **ASCII(美国信息交换标准代码)**:是最早的字符编码标准,使用7位二进制数来表示128个字符,包括大小写英文字母、数字、标点符号以及控制字符。由于其只能表示128个字符,因此无法表示其他语言中的字母和符号。
- **Unicode**:为了解决全球不同语言字符的表示问题,Unicode应运而生。Unicode旨在为每个字符提供唯一的编码,使用16位或32位的编码空间。Unicode的变体包括UTF-8、UTF-16和UTF-32,它们优化了编码长度,使其在存储和传输时更为高效。
- **GBK/GB2312**:主要是针对简体中文字符的编码标准。GBK是GB2312的扩展,提供了更多的汉字编码,但它们都是基于双字节编码。
### 2.1.2 编码与解码的原理
编码是将字符转换为特定编码格式的数字序列的过程,解码则是将这些数字序列还原为字符的过程。由于计算机只能处理数字,所以无论是哪种编码,最终都需要转换为数字形式。编码与解码通常遵循以下几个原则:
- **编码表**:编码表规定了每个字符对应的二进制代码。例如,在ASCII中,字符'A'对应的编码是01000001。
- **字节序**:字节序分为大端序和小端序,用于指定多字节编码中字节的存储顺序。大端序表示最高有效字节在前,小端序则相反。
- **编码一致性**:发送方和接收方需要使用相同的编码表和字节序进行编码和解码,否则会导致乱码。
## 2.2 VS Code工作区设置
### 2.2.1 设置工作区编码格式
为了防止中文乱码的出现,需要在VS Code中设置正确的工作区编码格式。具体操作步骤如下:
1. 打开VS Code。
2. 通过菜单栏选择“文件(File)” -> “首选项(Preferences)” -> “设置(Settings)”。
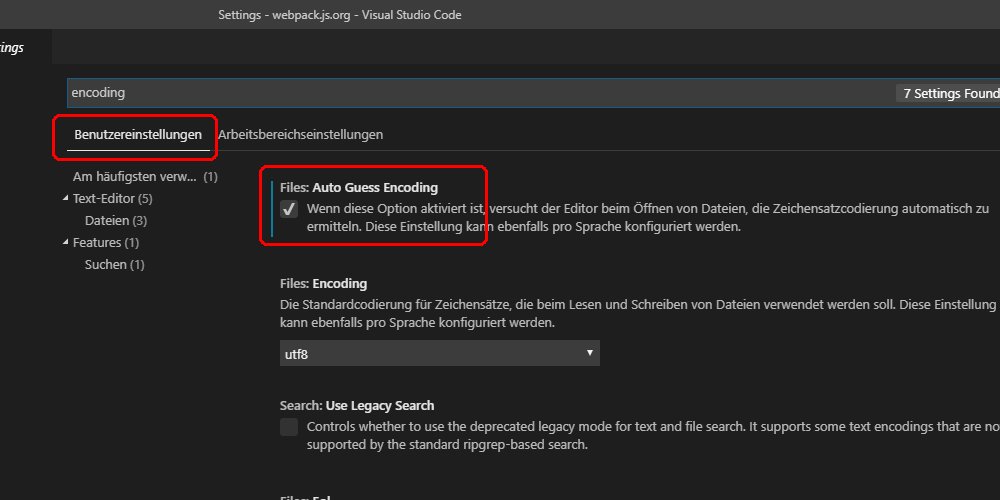
3. 在设置搜索框中输入“encoding”,找到“Files: Encoding”设置项。
4. 选择合适的编码格式,通常情况下推荐选择“UTF-8”作为工作区的编码格式。
### 2.2.2 配置文件中的编码指定
有时,仅仅设置全局编码是不够的,项目中的某些文件可能需要特定的编码。这时,可以在项目根目录下创建或修改`.vscode/settings.json`文件,为特定文件或文件夹指定编码。例如:
```json
{
"files.encoding": "utf8",
"[javascript]": {
"files.encoding": "utf8"
},
"files.autoGuessEncoding": true
}
```
这段配置表明工作区默认使用UTF-8编码,同时也为JavaScript文件设置了相同的编码,并启用自动编码猜测功能。
## 2.3 文件编码自动检测与转换
### 2.3.1 VS Code自动检测机制
VS Code具有文件编码自动检测功能。当打开一个文件时,VS Code会尝试自动识别文件的编码格式,并根据该编码来正确显示内容。用户也可以手动更改文件编码检测的优先级,在`settings.json`文件中进行如下设置:
```json
"files.autoGuessEncoding": true
```
启用此选项后,VS Code会在打开文件时尝试自动检测并使用最合适的编码格式。
### 2.3.2 文件编码转换的方法和技巧
如果检测到文件编码不是预期的编码格式,用户需要手动转换编码。以下是在VS Code中转换文件编码的步骤:
1. 打开需要转换编码的文件。
2. 通过右键菜单或者命令面板(`Ctrl+Shift+P`)找到“编码(Encode)”命令。
3. 在弹出的编码选项中,选择目标编码格式,如“UTF-8”。
4. VS Code将提示用户是否保存文件。选择“是”,文件将以新的编码格式保存。
对于批量转换文件编码,用户可以使用VS Code的“查找与替换”功能,或者使用外部工具进行批量处理。
```json
"files.autoGuessEncoding": true
```
通过上述配置,VS Code将尝试自动猜测并应用最合适的编码格式,从而减少编码问题的发生。在编码转换过程中,确保文件的备份是一个良好的习惯,以防转换失败导致数据丢失。
在本章节中,我们深入探讨了字符编码的基础知识,详细说明了如何在VS Code中设置工作区编码格式以及配置文件中的编码指定。此外,我们还介绍文件编码自动检测的机制和手动转换编码的方法。这些知识构成了预防和解决VS Code中中文乱码问题的坚实基础。接下来,我们将继续深入分析中文乱码问题的具体诊断和解决方案。
# 3. VS Code中文乱码问题诊断
## 3.1 常见的中文乱码场景
在使用VS Code进行开发时,中文乱码问题经常出现,尤其是在处理包含中文字符的文件时。乱码问题影响代码的阅读和理解,可能会导致程序运行异常。在深入探讨具体的解决方案之前,我们首先需要了解常见的中文乱码场景,以及它们对开发工作的影响。
### 3.1.1 代码文件乱码
代码文件乱码是最常见的一种中文乱码问题。当我们在VS Code中打开一个包含中文字符的代码文件时,如果编码设置不正确,文件

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Outlook 2016数据路径调整】:从新手到专家的全面解析,提升效率的实战指南

参考资源链接:[Outlook2016:更改.ost文件保存位置指南](https://wenku.csdn.net/doc/252naskqv6?spm=1055.2635.3001.10343)
# 1. Outlook 2016基础概述
在本章中,我们将对Microsoft Outlook 2016进行基础性介绍,这是IT专业人员经常使用的一款强大的邮件管理软件
IEC61131-2 PLC编程全解:权威指南揭秘最佳实践与技巧

参考资源链接:[IEC 61131-2 PLC编程标准更新:软件架构与测试要求](https://wenku.csdn.net/doc/6412b705be7fbd1778d48cf2?spm=1055.2635.3001.10343)
# 1. IEC 61131-2标准与PLC基础
## 1.1 IEC 61131-2标准概述
IEC 61131-2是国际电工委员会(IEC)制定的可编程逻辑控制器(PLC)编程
温度传感器选择秘籍:为你的报警器项目找到最佳伴侣

参考资源链接:[Multisim温度控制报警电路设计与仿真](https://wenku.csdn.net/doc/6412b79dbe7fbd1778d4aeed?spm=1055.2635.3001.10343)
# 1. 温度传感器概述与选择标准
温度传感器作为监控环境或物体温度的关键设备,被广泛应用于工业、科研以及日常生活中。选择合适的温度传感器对于保障系统精准性、可靠性和成本效益至关重要。本章将概述温度传感器的基础知识,并
数据流与处理流程:设计说明书中数据流转的细节揭秘

参考资源链接:[软件设计说明:CSCI架构与详细设计](https://wenku.csdn.net/doc/xnqgh2cm78?spm=1055.2635.3001.10343)
# 1. 数据流与处理流程概述
在信息技术领域,数据流与处理流程是构建高效系统的基础。本章节将简要介绍数据流和处理流程的概念,为读者建立初步认识。
数据流是系统中数据的流动路径,它描述了数据从输入到输出的整个传输过程。数据流的优化对于提升系统的响应速度和效率至关重要。而处理流
Cassandra 10.1 高级查询技巧:优化你的数据检索
参考资源链接:[CASS10.1使用指南:命令菜单与工具设置](https://wenku.csdn.net/doc/22i2ao60dp?spm=1055.2635.3001.10343)
# 1. Cassandra简介与查询基础
Apache Cassandra 是一个开源的、分布式的、高可用性、无单点故障的宽列存储NoSQL数据库。它是为了解决大数据量的
【正交性与最小二乘法:数据世界的精确之舞】:《线性代数介绍》第五版习题应用的全面分析

参考资源链接:[线性代数第五版习题解答手册——Gilbert Strang](https://wenku.csdn.net
操作系统教程第六版全攻略:精通习题答案深度解析与应用

参考资源链接:[《操作系统教程》第六版习题详解及答案](https://wenku.csdn.net/doc/6cpyvn61k0?spm=1055.2635.3001.10343)
# 1. 操作系统核心概念与原理
操作系统是计算机系统中的基础软件,它管理计算机硬件资源,提供用户与计算机交互
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )