Spring Boot快速开发与常用功能实现
发布时间: 2024-01-12 17:27:08 阅读量: 31 订阅数: 36 
# 1. Spring Boot 简介
## 1.1 什么是Spring Boot
Spring Boot 是一个基于Spring框架的快速开发框架,它通过约定优于配置的原则,大大简化了Spring应用的开发和部署。相比传统的Spring应用,Spring Boot不需要繁琐的配置文件,只需少量的代码就可以快速搭建一个功能完善的应用。
## 1.2 Spring Boot的优势和特点
- 简化配置:Spring Boot通过自动化配置和约定优于配置的原则,大幅度减少了繁琐的配置文件,使开发者可以更专注于业务逻辑的实现。
- 内嵌服务器:Spring Boot内置了多个常用的服务器,如Tomcat、Jetty等,可以直接打包成可执行的JAR文件运行,方便部署和调试。
- 自动化依赖管理:Spring Boot引入了依赖管理工具,可以自动解决各个组件之间的依赖关系,简化了项目的构建和升级。
- 监控和管理:Spring Boot提供了健康检查、指标监控、配置中心等功能,方便对应用进行监控和管理。
## 1.3 Spring Boot的快速开发理念
Spring Boot的快速开发理念主要体现在以下几个方面:
- Starter依赖:Spring Boot提供了一系列的Starter依赖,通过引入不同的Starter依赖,可以快速集成各种功能,减少了手动引入依赖的工作量。
- 自动化配置:Spring Boot通过自定义的条件注解,根据项目中引入的依赖自动配置应用环境,大大减少了手动配置的工作。
- 开发环境监控:Spring Boot提供了监控工具和健康检查机制,可以实时监控应用的运行状态,快速定位和解决问题。
希望本章能为大家介绍清楚Spring Boot的基本概念和优势特点,并对其快速开发理念有一个基本的了解。在下一章节,我们将详细介绍如何快速入门Spring Boot,并搭建一个简单的应用。
# 2. Spring Boot 快速入门
### 2.1 Spring Boot项目的创建与配置
在开始编写Spring Boot应用程序之前,我们需要先创建一个Spring Boot项目并进行配置。以下是创建和配置Spring Boot项目的步骤:
1. 打开IDE,选择创建一个新的Maven项目。
2. 输入项目的基本信息,包括GroupId、ArtifactId和版本号。
3. 添加Spring Boot的起步依赖,可以选择适合自己项目需要的依赖,例如:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
```
4. 在IDE中添加一个主类,该类是Spring Boot应用程序的入口点,示例代码如下:
```java
@SpringBootApplication
public class MyApplication {
public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
}
}
```
5. 编写业务逻辑代码,例如编写一个简单的Hello World接口:
```java
@RestController
public class HelloWorldController {
@GetMapping("/hello")
public String hello() {
return "Hello, Spring Boot!";
}
}
```
6. 启动应用程序,访问http://localhost:8080/hello可以看到返回的"Hello, Spring Boot!"信息。
### 2.2 快速搭建一个简单的Spring Boot应用
使用Spring Boot可以快速搭建一个简单的Web应用程序。以下是搭建一个简单Spring Boot应用的步骤:
1. 创建一个Spring Boot项目,参考2.1节中的步骤。
2. 编写一个控制器类,处理HTTP请求,示例代码如下:
```java
@RestController
public class HelloController {
@GetMapping("/hello")
public String hello() {
return "Hello, Spring Boot!";
}
}
```
3. 运行应用程序,访问http://localhost:8080/hello可以看到返回的"Hello, Spring Boot!"信息。
### 2.3 Spring Boot的自动化配置和约定优于配置原则
Spring Boot通过自动化配置的方式简化了应用程序的配置。在默认情况下,Spring Boot根据项目的依赖和配置文件的内容自动配置应用程序。以下是Spring Boot自动化配置的几个特点:
- 默认配置:Spring Boot提供了一套默认的配置,减少了开发人员在配置文件中进行大量的设置。
- 条件化配置:Spring Boot根据特定的条件自动配置相关的组件,例如根据是否存在某个类或bean来决定是否加载相关配置。
- 自动配置的顺序:Spring Boot的自动配置的顺序是根据依赖的顺序来确定的,先加载必备的配置,然后再根据其他依赖的配置情况进行自动化配置。
通过使用Spring Boot的自动化配置,开发人员可以快速构建应用程序,而无需关心繁琐的配置细节。
在本章中,我们简要介绍了Spring Boot的快速入门过程,并说明了Spring Boot的自动化配置和约定优于配置原则。在下一章节中,我们将深入探讨Spring Boot的常用功能实现。
# 3. Spring Boot常用功能实现
#### 3.1 数据库操作与JPA实现
在Spring Boot中,我们可以方便地使用JPA(Java Persistence API)来实现与数据库的交互。下面是一个简单的示例,演示了如何在Spring Boot应用中进行数据库操作。
首先,我们需要定义一个实体类,用于映射数据库中的表。假设我们有一个名为User的实体类,对应数据库中的用户表:
```java
@Entity
@Table(name = "user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String email;
// 省略其他属性和方法
}
```
然后,我们可以创建一个Repository接口,用于对User实体进行数据库操作:
```java
public interface UserRepository extends JpaRepository<User, Long> {
// 可以在这里添加自定义的查询方法
}
```
接下来,我们可以在业务逻辑中使用UserRepository进行数据库操作,例如增加一个新用户:
```java
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public void addUser(User user) {
userRepository.save(user);
}
}
```
通过以上代码,我们就可以方便地使用JPA来完成数据库操作,Spring Boot会自动帮我们生成数据表,并且进行数据的增删改查操作。
#### 3.2 RESTful API的实现
在Spring Boot中,我们可以轻松地实现RESTful风格的API,以下是一个简单的示例,演示了如何创建一个RESTful API:
首先,我们创建一个Controller类,定义API接口:
```java
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserService userService;
@PostMapping
public ResponseEntity<String> addUser(@RequestBody User user) {
userService.addUser(user);
return ResponseEntity.ok("User added successfully");
}
@GetMapping("/{id}")
public ResponseEntity<User> getUserById(@PathVariable Long id) {
User user = userService.getUserById(id);
return ResponseEntity.ok(user);
}
// 省略其他API接口
}
```
通过以上代码,我们就创建了两个RESTful风格的API接口,一个用于添加用户,另一个用于根据ID获取用户信息。
#### 3.3 日志记录与异常处理
日志记录和异常处理是每个应用都需要考虑的重要功能。在Spring Boot中,我们可以通过注解和配置来实现日志记录和异常处理。
我们可以通过以下方式配置日志记录:
```yaml
logging:
level:
root: INFO
com.example: DEBUG
```
上述配置将日志输出级别设置为INFO,同时为com.example包下的类设置DEBUG级别的日志输出。
在代码中,我们可以使用注解@ExceptionHandler来处理异常:
```java
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(Exception.class)
public ResponseEntity<String> handleException(Exception e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Internal Server Error");
}
}
```
通过以上代码,我们实现了全局的异常处理,当发生异常时,返回统一的错误响应。
通过这些内容,我们介绍了Spring Boot中常用功能的实现方式,包括数据库操作与JPA实现、RESTful API的实现以及日志记录与异常处理。这些功能的实现可以帮助我们快速开发应用,并确保应用的健壮性和稳定性。
# 4. Spring Boot与Security实现身份认证
### 4.1 Spring Security的基本概念
Spring Security是一个功能强大且灵活的框架,用于在Spring应用程序中实现身份验证和授权。它提供了一套细粒度的安全性控制机制,可以应对常见的安全问题,如用户认证、角色权限、会话管理等。
在Spring Boot项目中使用Spring Security,需要在项目的pom.xml文件中添加相应的依赖:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
```
### 4.2 使用Spring Security实现用户认证与授权
#### 4.2.1 配置用户认证
首先,需要创建一个用于配置安全性的类,并继承`WebSecurityConfigurerAdapter`。
```java
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth
.inMemoryAuthentication()
.withUser("admin")
.password("{noop}password")
.roles("ADMIN");
}
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN") // 配置权限
.anyRequest().authenticated() // 其他请求需要认证
.and()
.formLogin()
.and()
.logout()
.logoutSuccessUrl("/login?logout")
.permitAll();
}
}
```
上面的代码配置了一个用户,用户名为admin,密码为password,角色为ADMIN。还配置了路径为/admin/**的请求需要ADMIN角色权限,其他请求需要认证。
#### 4.2.2 配置用户密码加密
上述示例中,密码采用了明文存储,为了提高安全性,通常需要对用户密码进行加密存储。
可以通过实现`PasswordEncoder`接口来自定义密码加密方式,并在配置类中使用。
```java
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
// ...
}
```
然后在configure方法中使用`passwordEncoder()`方法进行密码加密配置。
#### 4.2.3 使用自定义用户存储
除了使用内存中的用户数据,我们常常还需要与数据库进行交互实现用户认证。
首先,需要创建一个用户实体类,例如User。
```java
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(unique = true)
private String username;
private String password;
private String roles;
// getters and setters
}
```
然后,实现UserDetailsService接口来获取用户详情。
```java
@Service
public class UserDetailsServiceImpl implements UserDetailsService {
@Autowired
private UserRepository userRepository;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
User user = userRepository.findByUsername(username);
if (user == null) {
throw new UsernameNotFoundException("User not found");
}
return new org.springframework.security.core.userdetails.User(
user.getUsername(),
user.getPassword(),
AuthorityUtils.commaSeparatedStringToAuthorityList(user.getRoles())
);
}
}
```
最后,在配置类中,使用自定义的UserDetailsService。
```java
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private UserDetailsService userDetailsService;
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.userDetailsService(userDetailsService).passwordEncoder(passwordEncoder());
}
// ...
}
```
### 4.3 使用JWT实现无状态的身份认证
JWT(JSON Web Token)是一种用于描述声明的方式,常用于身份验证和授权。
在Spring Security中,可以使用JWT实现无状态的身份认证。
首先,需要添加JWT的依赖。
```xml
<dependency>
<groupId>io.jsonwebtoken</groupId>
<artifactId>jjwt</artifactId>
<version>0.9.0</version>
</dependency>
```
然后,编写一个JWT工具类。
```java
@Component
public class JwtTokenUtil {
private static final String SECRET_KEY = "secret";
public String generateToken(UserDetails userDetails) {
Date now = new Date();
Date expiration = new Date(now.getTime() + 604800000);
return Jwts.builder()
.setSubject(userDetails.getUsername())
.setIssuedAt(now)
.setExpiration(expiration)
.signWith(SignatureAlgorithm.HS512, SECRET_KEY)
.compact();
}
public String getUsernameFromToken(String token) {
return Jwts.parser()
.setSigningKey(SECRET_KEY)
.parseClaimsJws(token)
.getBody()
.getSubject();
}
public boolean validateToken(String token, UserDetails userDetails) {
String username = getUsernameFromToken(token);
return username.equals(userDetails.getUsername());
}
}
```
最后,在配置类中配置JWT相关的过滤器。
```java
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private JwtTokenUtil jwtTokenUtil;
@Autowired
private UserDetailsService userDetailsService;
// ...
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.addFilterBefore(new JwtAuthenticationFilter(jwtTokenUtil, userDetailsService), UsernamePasswordAuthenticationFilter.class)
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN")
.anyRequest().authenticated()
.and()
.formLogin()
.and()
.logout()
.logoutSuccessUrl("/login?logout")
.permitAll();
}
}
```
上面的代码中,配置了一个JwtAuthenticationFilter,用于解析请求中的JWT并进行身份认证。
这就是Spring Boot与Security实现身份认证的基本步骤和示例代码。通过对用户认证和授权的配置,以及使用JWT实现无状态的身份认证,可以为Spring Boot应用程序提供安全性的保护。
# 5. Spring Boot与消息队列
消息队列在现代应用开发中扮演着至关重要的角色,它可以实现应用内部各模块间的异步通信,实现解耦和提升系统性能的效果。Spring Boot提供了丰富的支持,使得集成消息队列变得异常便捷。在本章中,我们将深入探讨消息队列的作用和原理,并演示如何在Spring Boot应用中集成消息队列。
#### 5.1 消息队列的作用和原理
消息队列是一种应用内部或应用间的通信机制,它通过将消息存储在中间件中,实现了消息的异步传输和解耦。常见的消息队列中间件包括RabbitMQ、Apache Kafka、ActiveMQ等。消息队列的基本原理是生产者向队列中发送消息,而消费者则从队列中接收消息进行处理,实现了消息的异步传输。
#### 5.2 使用Spring Boot集成消息队列
Spring Boot对消息队列的集成非常友好,通过提供的`@EnableJms`或`@EnableRabbit`等注解,可以快速将消息队列功能整合到Spring Boot应用中。同时,Spring Boot还提供了丰富的Starter和自动配置,使得开发者可以轻松地与各种消息队列中间件集成。在具体实现时,可以使用JMS、RabbitMQ或Kafka等消息队列协议来实现消息的生产和消费。
下面以RabbitMQ为例,演示Spring Boot中如何集成消息队列:
```java
// 生产者发送消息
@Component
public class RabbitMQProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendMessage(String queue, String message) {
rabbitTemplate.convertAndSend(queue, message);
}
}
// 消费者接收消息
@Component
@RabbitListener(queues = "myQueue")
public class RabbitMQConsumer {
@RabbitHandler
public void handleMessage(String message) {
System.out.println("Received message: " + message);
}
}
```
#### 5.3 异步消息的处理与消费者实现
在实际应用中,消息的生产和消费往往是异步进行的。通过消息队列,生产者可以将消息发送到队列中,而消费者则可以异步地从队列中获取消息进行处理。Spring Boot通过`@RabbitListener`或`@JmsListener`注解可以方便地实现消息的消费者逻辑。
```java
// 消费者接收消息
@Component
@RabbitListener(queues = "myQueue")
public class RabbitMQConsumer {
@RabbitHandler
public void handleMessage(String message) {
System.out.println("Received message: " + message);
// 处理消息的业务逻辑
}
}
```
以上是Spring Boot集成消息队列的简单示例,通过以上代码,我们可以轻松实现消息的生产和消费逻辑,而不必过多关注底层消息队列中间件的具体实现细节。
通过本章的学习,读者将对消息队列的概念和在Spring Boot中的集成有更深入的了解,也将掌握基本的消息生产和消费的实现方式。
# 6. Spring Boot性能优化与部署实践
在本章中,我们将重点讨论如何对Spring Boot应用进行性能优化和部署实践。我们将介绍一些常用的性能调优技巧,并讨论如何使用Docker容器化部署Spring Boot应用。最后,我们还将分享一些关于Spring Boot应用的线上监控和故障排查的实践经验。让我们开始进入本章内容。
### 6.1 Spring Boot应用的性能调优技巧
在本节中,我们将介绍一些常用的Spring Boot应用性能调优技巧。以下是几个重要的方面:
#### 6.1.1 确定性能瓶颈
在进行性能调优之前,我们需要先确定应用中的性能瓶颈在哪里。可以使用一些性能分析工具,如JProfiler、VisualVM等来监视应用的运行情况,找出潜在的性能问题。
#### 6.1.2 优化数据库访问
数据库访问通常是应用性能的一个瓶颈。一些优化数据库访问的策略包括:
- 使用缓存:可以使用缓存来减轻数据库的压力,例如使用Redis来缓存常用数据。
- 批量操作:尽量使用批量操作来减少与数据库的交互次数,例如批量插入、批量更新等。
- 数据库索引:正确使用数据库索引可以提高查询性能。
- 数据库连接池配置:合理配置数据库连接池的参数,以充分利用数据库连接资源。
#### 6.1.3 使用缓存
使用缓存来减轻服务器的压力是另一个有效的性能优化策略。Spring Boot提供了对缓存的支持,可以很方便地集成常用的缓存框架,如Ehcache、Redis等。
#### 6.1.4 压缩资源文件
压缩静态资源文件(如CSS、JavaScript等)可以减小文件的大小,从而提高加载速度。可以使用一些工具,如Gzip压缩、图片无损压缩等来优化资源文件。
### 6.2 使用Docker容器化部署Spring Boot应用
在本节中,我们将介绍如何使用Docker容器化部署Spring Boot应用。Docker是一个开源的容器化平台,可以将应用及其依赖打包成一个独立的容器,使得应用在不同环境中具备相同的运行行为。
#### 6.2.1 创建Docker镜像
首先,我们需要创建一个Docker镜像,将Spring Boot应用打包进去。可以使用Dockerfile来描述镜像的构建过程,例如:
```dockerfile
FROM openjdk:8-jdk-alpine
COPY target/my-spring-boot-app.jar /app.jar
EXPOSE 8080
ENTRYPOINT ["java", "-jar", "/app.jar"]
```
上述Dockerfile使用OpenJDK作为基础镜像,将编译好的Spring Boot应用复制到镜像中,并指定应用的启动命令。
#### 6.2.2 构建Docker镜像
使用Docker命令行工具可以很方便地构建Docker镜像,例如:
```shell
docker build -t my-spring-boot-app .
```
上述命令将根据当前目录下的Dockerfile构建一个名为my-spring-boot-app的镜像。
#### 6.2.3 运行Docker容器
构建好镜像之后,可以使用Docker命令行工具来运行容器,例如:
```shell
docker run -p 8080:8080 my-spring-boot-app
```
上述命令将在本地的8080端口上运行my-spring-boot-app容器,并将8080端口映射到容器内的8080端口。
### 6.3 Spring Boot应用的线上监控与故障排查
在本节中,我们将分享一些关于Spring Boot应用的线上监控和故障排查的实践经验。以下是几个关键的方面:
#### 6.3.1 健康检查
Spring Boot提供了一个健康检查的端点,可以用来检查应用的运行状态。可以通过访问`/actuator/health`端点来获取应用的健康状态。
#### 6.3.2 日志记录与报警
通过合理配置日志记录,可以及时发现应用中的问题,并进行故障排查。可以使用一些日志监控工具,如ELK Stack、Splunk等来实时监控日志,并设置报警机制。
#### 6.3.3 性能监控与调优
使用一些性能监控工具,如Prometheus、Grafana等可以实时监控应用的性能指标,并进行性能调优。
以上就是关于Spring Boot性能优化与部署实践的一些内容,在实际应用开发中,可以根据具体的场景选择合适的优化策略和部署方式,以提升应用的性能和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这篇专栏涵盖了面试官8年的 Java 经验,详细解析了 Java 面试的秘诀。从 Java 基础知识、面向对象编程、集合框架、异常处理、多线程编程、IO 与 NIO、反射机制、网络编程、并发包、JVM 原理、设计模式、Spring 框架、Spring Boot、Spring MVC、MyBatis、MySQL 优化、NoSQL 数据库、Linux 基础知识到 JSON 与 XML 数据格式处理等多个方面进行了深入总结与解析。无论是技术初学者还是有一定经验的开发者都能从中获益,旨在帮助读者掌握 Java 技术的核心知识,并在面试中脱颖而出。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
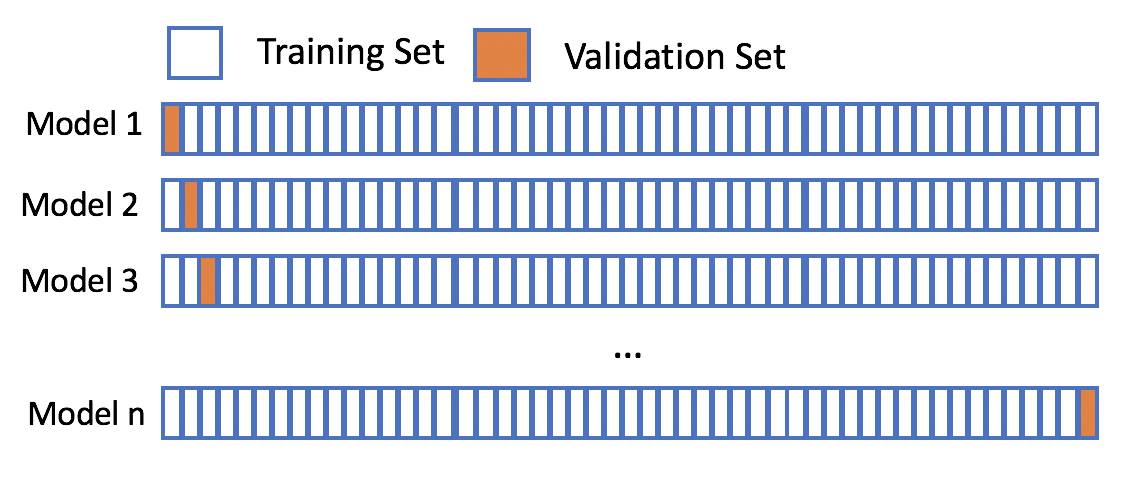
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
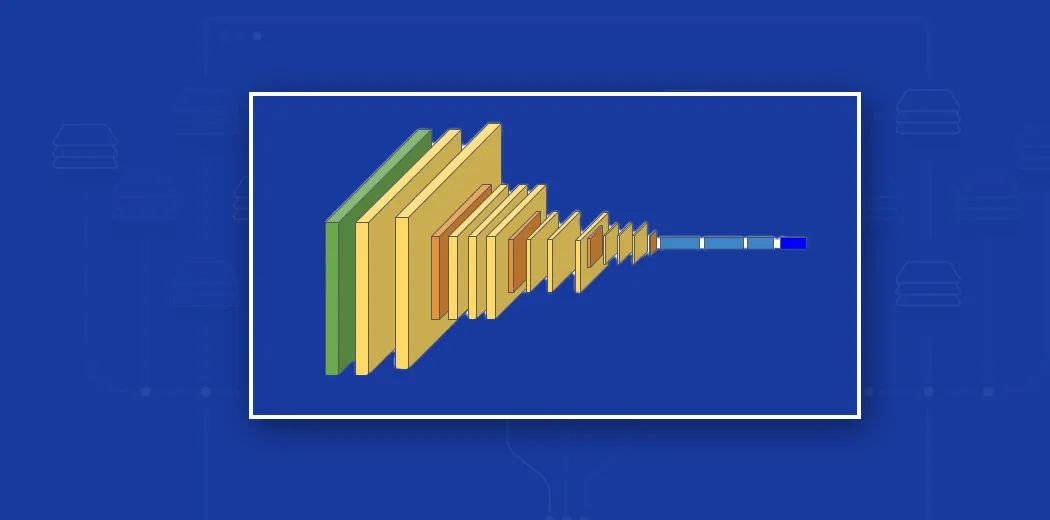
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
机器学习调试实战:分析并优化模型性能的偏差与方差
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
贝叶斯优化的挑战与误区:专家带你避开这些坑

# 1. 贝叶斯优化概述
贝叶斯优化是一种用于黑盒参数优化的算法,它在众多领域如机器学习模型调优、工程设计、商业决策等方面都有着广泛应用。该算法的核心是通过构建一个概率模型来模拟目标函数的行为,然后基于此模型来指导搜索过程,进而寻找能够最大化目标函数值的参数配置。
贝叶斯优化的优势在于其在目标函数评估代价高昂时仍能有效地找到全局最优解。它通过选择在目前所掌握信息下“最有希望”的参数点来迭
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
激活函数在深度学习中的应用:欠拟合克星
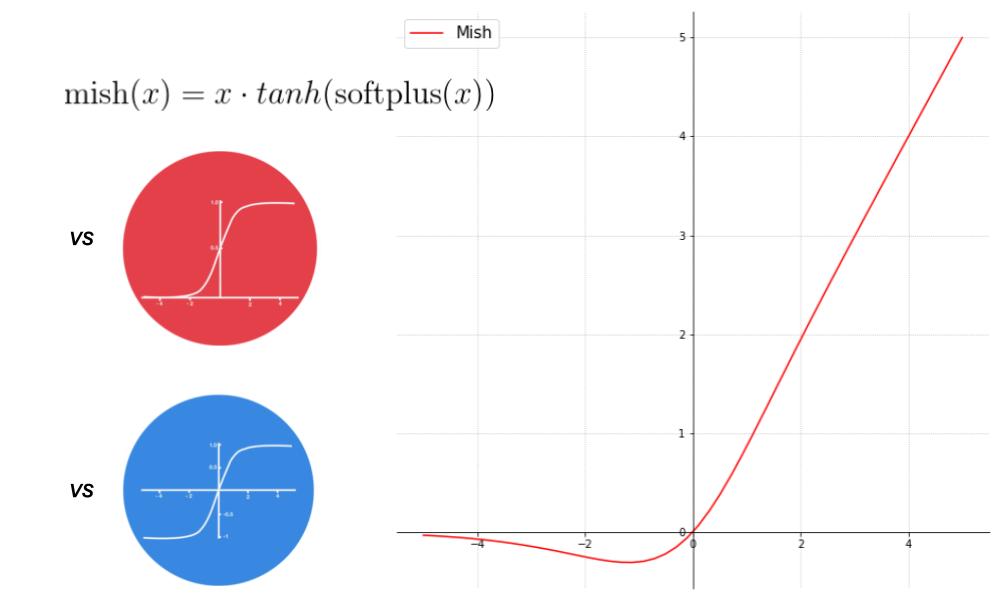
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )