SQL性能革命:Field II 查询优化技巧与执行计划分析
发布时间: 2024-12-14 11:59:04 阅读量: 1 订阅数: 3 

Microsoft SQL Server:性能优化与故障排查的技术指南
参考资源链接:[MATLAB FieldII超声声场仿真教程:从入门到实例](https://wenku.csdn.net/doc/4rraiuxnag?spm=1055.2635.3001.10343)
# 1. SQL性能优化概述
## 1.1 性能优化的重要性
SQL性能优化是数据库管理中至关重要的一环。随着数据量的日益增长,优化查询速度和提升系统性能成为了数据库管理员和开发人员必须面对的挑战。本章将概述性能优化的基本概念,以及它在现代数据库应用中的重要性。
## 1.2 优化的目标与挑战
优化的目标是提高查询效率和减少响应时间。然而,数据库环境的多样性和复杂性使得优化工作充满挑战。不同的数据库管理系统(DBMS),甚至不同版本的同一系统,都可能需要不同的优化策略。
## 1.3 常用的优化方法
性能优化可以通过多种方法实现,例如合理的索引设计、查询语句的改写、数据库参数的调整等。这些方法可以单独使用,也可以组合应用,以达到最佳的优化效果。
在接下来的章节中,我们将深入了解执行计划、分析策略、调整优化等关键步骤,并探讨各种具体的优化技巧和高级技术。通过这些内容,读者将能够掌握SQL性能优化的全面知识,提升数据库性能。
# 2. 深入理解SQL查询执行计划
### 2.1 查询执行计划的组成元素
#### 2.1.1 操作符和操作节点
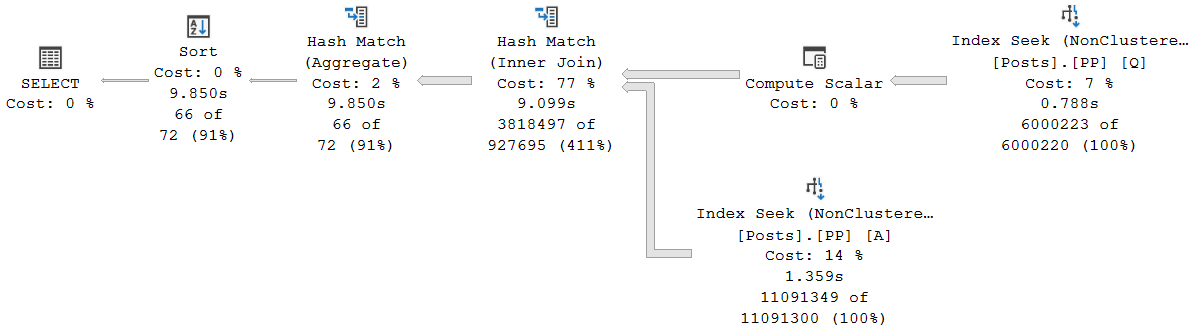
执行计划中每个步骤被表示为操作符,它们描述了数据库如何执行SQL查询的各个部分。每个操作符通常对应于数据库中的一个或多个物理操作,如表扫描、排序、聚合等。例如,"Hash Join"操作符表明数据库使用哈希算法将两个表连接起来。
##### 代码块示例
```sql
-- 示例查询:SELECT * FROM table1 JOIN table2 ON table1.id = table2.id;
```
在上述SQL查询中,执行计划可能包含如下操作符:
- Seq Scan:顺序扫描操作符,用于扫描整个表。
- Hash Join:哈希连接操作符,用于合并两个表。
- Hash:哈希操作符,用于构建连接过程中的哈希表。
每个操作符可以有一个或多个子节点,这表示数据的来源。这些节点可以是表、临时表、索引或其他操作的结果。查询优化器会基于统计信息和成本估算选择最合适的操作符和路径来最小化总执行成本。
#### 2.1.2 成本估算与统计信息
数据库查询优化器使用成本估算模型来预测不同执行计划的成本,并选择成本最低的计划。这个估算通常基于统计信息,例如表中行数、列的唯一值数量、数据分布等。
##### 成本估算参数说明
- `cost`: 估算查询执行的总成本,通常以磁盘I/O、CPU周期和网络传输为单位。
- `rows`: 预计返回的行数。
- `width`: 预计返回的行的平均宽度。
##### 代码块示例
```sql
-- 分析表的统计信息
ANALYZE TABLE table_name;
```
执行`ANALYZE TABLE`命令能够更新表的统计信息,有助于优化器生成更精确的执行计划。
### 2.2 分析执行计划的策略
#### 2.2.1 识别执行计划中的瓶颈
分析执行计划的第一步是识别潜在的瓶颈。瓶颈可能是由于数据分布不均、数据量大、索引选择不当等原因导致的。通常,一些操作符如"Seq Scan"在行数较多的表上执行时会有较高的成本。
##### 表格:常见执行计划瓶颈及解决方法
| 瓶颈类型 | 解决方法 |
| --- | --- |
| 序列扫描 | 建立合适的索引 |
| 排序 | 使用索引排序或增加内存 |
| 高成本连接 | 优化连接条件或使用更有效的连接算法 |
##### 代码块示例
```sql
-- 创建索引以优化查询
CREATE INDEX idx_col_name ON table_name (column_name);
```
通过增加合适的索引,可以将"Seq Scan"转换为更高效的"Index Scan",从而显著减少查询成本。
#### 2.2.2 利用索引优化查询性能
索引是提高查询性能的关键。正确的索引可以减少数据的扫描量,并提高连接操作的效率。但同时,索引也需要维护成本,因此需要权衡索引带来的性能提升与维护成本。
##### mermaid流程图:索引优化查询性能流程
```mermaid
graph LR
A[开始分析查询性能] --> B[检查是否有索引]
B --> |有索引| C[分析索引使用情况]
B --> |无索引| D[评估添加索引的可能]
C --> E[确定索引是否有效]
E --> |是| F[优化查询语句]
E --> |否| G[考虑重建或替换索引]
D --> H[计算添加索引的成本与收益]
H --> |收益大于成本| I[添加索引]
H --> |收益小于成本| J[寻找其他优化方案]
F --> K[结束优化]
G --> K
I --> K
J --> K
```
#### 2.2.3 重写查询以改善执行计划
有时候,通过重写查询语句可以改变执行计划。例如,可以将子查询转换为连接操作,或者调整`WHERE`子句中条件的顺序以利用索引。
##### 代码块示例
```sql
-- 原始查询:SELECT * FROM table WHERE col1 = (SELECT col2 FROM another_table WHERE condition);
-- 重写为连接查询
SELECT t.*, a.*
FROM table t
JOIN another_table a ON t.col1 = a.col2
WHERE a.condition;
```
通过重写,可以将嵌套循环连接转换为更高效的连接算法,从而减少查询成本。
### 2.3 执行计划的调整与优化
#### 2.3.1 调整数据结构和索引
调整数据结构通常涉及到规范化和反规范化策略的选择,以及合适的数据类型和索引的创建。
##### 代码块示例
```sql
-- 创建复合索引
CREATE INDEX idx_col1_col2 ON table_name (column1, column2);
```
通过创建复合索引,可以加快多列查询条件下的查询速度。
#### 2.3.2 使用提示和优化器选项
数据库优化器提供了一些提示和选项,允许数据库管理员和开发者影响优化器的决策过程,以此来获得更优的执行计划。
##### 代码块示例
```sql
-- PostgreSQL 使用特定的索引
SELECT * FROM table_name USING INDEX (index_name) WHERE condition;
```
这些提示告诉优化器使用特定的索引,忽略其内部成本估算模型。
#### 2.3.3 优化器的内部工作机制
优化器使用算法和启发式方法来生成和选择最佳的执行计划。理解优化器的工作机制有助于我们预测其行为,并据此调整查询以获得更好的性能。
##### 表格:优化器的工作原理及示例
| 优化器行为 | 优化

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Field II 教程》专栏是一份全面的指南,旨在帮助您掌握 Field II 数据管理系统的各个方面。它提供了从基础到高级应用的实用技巧,涵盖了数据模型、数据结构、数据质量、视图和索引、数据完整性以及 SQL 性能优化等关键主题。通过遵循本专栏中的分步指南,您可以有效地优化您的数据结构,提高数据质量,并显著提升您的 SQL 查询性能。本专栏是数据专业人士和开发人员的宝贵资源,他们希望充分利用 Field II 的强大功能,并构建高效、可靠且可维护的数据管理系统。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
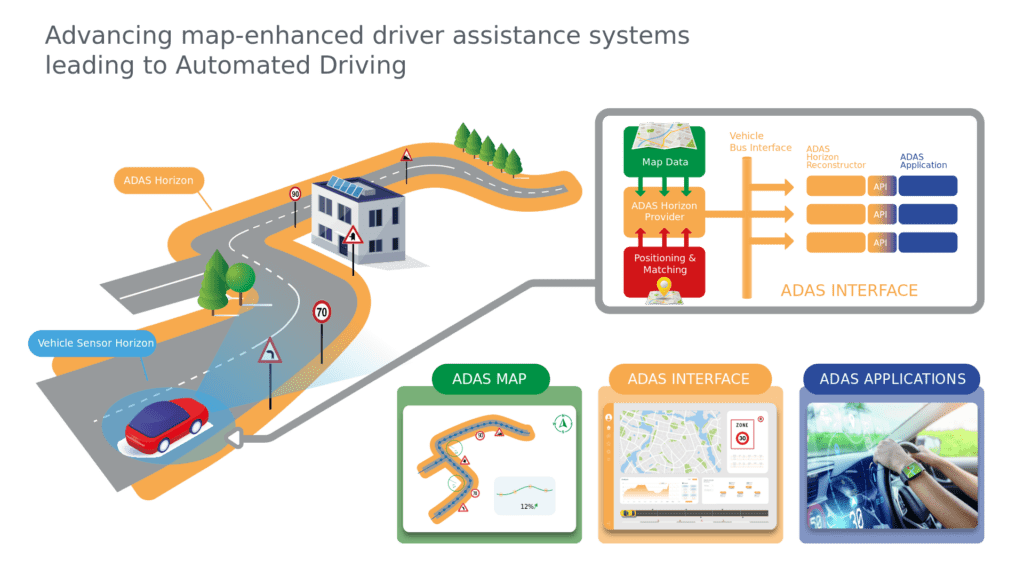
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )