Python中的XML数据提取:ElementTree.ElementTree高效解析策略
发布时间: 2024-10-16 10:51:09 阅读量: 20 订阅数: 15 

# 1. XML数据基础与Python解析概述
## 1.1 XML数据基础
XML(eXtensible Markup Language)是一种可扩展的标记语言,用于存储和传输数据。它的设计旨在弥补HTML在描述数据方面的不足,更侧重于数据内容而非显示格式。XML使用标签来描述数据,这些标签可以自我描述,因此具有良好的可读性和可扩展性。
## 1.2 XML的结构
XML文档具有严格的树状结构,由元素(Elements)、属性(Attributes)、文本(Text)、注释(Comments)和处理指令(Processing Instructions)等组成。每个元素由开始标签和结束标签定义,嵌套在父元素中,可以包含文本内容和其他子元素。
## 1.3 Python中的XML解析
在Python中,解析XML数据通常使用`xml.etree.ElementTree`模块,它提供了完整的XML处理功能,包括读取XML文件、创建XML结构、遍历XML树以及搜索和修改XML数据。该模块易于使用,性能良好,是处理XML数据的首选工具之一。
## 1.4 示例:解析XML数据
以下是一个简单的示例,展示如何使用`xml.etree.ElementTree`模块来解析XML数据。
```python
import xml.etree.ElementTree as ET
# 加载XML数据
xml_data = '''<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
</country>
</data>'''
# 解析XML
root = ET.fromstring(xml_data)
# 遍历XML结构
for country in root.findall('country'):
rank = country.find('rank').text
year = country.find('year').text
name = country.get('name')
print(name, rank, year)
```
在上述代码中,我们首先导入了`xml.etree.ElementTree`模块,并定义了一个包含国家排名信息的XML字符串。然后,我们使用`ET.fromstring`方法将字符串解析为一个ElementTree对象。最后,我们遍历了每个国家的元素,提取并打印了它们的排名、年份和名称。
# 2. ElementTree.ElementTree的理论基础
在本章节中,我们将深入探讨`ElementTree.ElementTree`库,这是Python中处理XML数据的强大工具。我们将从理解XML数据结构开始,逐步过渡到`ElementTree`库的安装、核心组件以及如何建立和遍历树结构。通过本章节的介绍,你将对`ElementTree`有一个全面的认识,并为其在实际应用中的强大功能打下坚实的基础。
## 2.1 XML数据结构理解
### 2.1.1 XML基本概念与结构
XML(Extensible Markup Language)是一种可扩展标记语言,它用于存储和传输数据。与HTML不同,XML不提供预定义的标签,而是允许用户根据需要定义自己的标签和属性。在XML中,每个元素由一个开始标签、内容和一个结束标签组成。标签通常成对出现,例如`<element>content</element>`。
XML文档的结构可以被看作是一个树形结构,其中的每个节点都是一个元素。XML文档必须有一个根元素,所有其他元素都是这个根元素的子元素,或者更深层次的后代元素。
### 2.1.2 XML元素和属性解析
在XML中,元素可以包含其他元素、文本内容、属性,或者混合内容。属性是元素的命名参数,它们提供了关于元素的额外信息。属性总是位于开始标签内,并且必须被引号包围。
下面是一个简单的XML文档示例,用于说明XML元素和属性的结构:
```xml
<library>
<book id="b1">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
</book>
<book id="b2">
<title lang="en">XML in a Nutshell</title>
<author>Elliotte Rusty Harold</author>
<year>2012</year>
</book>
</library>
```
在这个例子中,`library`是根元素,它包含两个`book`子元素。每个`book`元素都有一个`id`属性,一个`title`元素,一个`author`元素,以及一个`year`元素。
## 2.2 ElementTree.ElementTree库概述
### 2.2.1 ElementTree库的安装与导入
`ElementTree`是一个用于解析和创建XML数据的Python库。它是Python标准库的一部分,因此不需要单独安装。要使用`ElementTree`,你需要在Python代码中导入它:
```python
import xml.etree.ElementTree as ET
```
这里,我们导入了`ElementTree`库,并给它一个别名`ET`,这样可以使代码更加简洁。
### 2.2.2 ElementTree与XML的兼容性分析
`ElementTree`能够读取和写入XML数据,并且提供了对XML结构的强大操作能力。它支持XPath表达式,这使得查找特定节点变得非常方便。此外,`ElementTree`还支持事件驱动的解析,这意味着它可以在处理大型XML文件时不需要将整个文档加载到内存中。
在接下来的章节中,我们将探讨`ElementTree`的核心组件,包括如何建立树结构、遍历节点以及操作元素节点。我们将通过代码示例和逻辑分析,帮助你更好地理解和应用这些概念。
# 3. ElementTree.ElementTree的实践应用
## 3.1 基于ElementTree的数据提取技术
### 3.1.1 查找特定节点的方法
在处理XML数据时,我们经常需要提取特定的节点信息。ElementTree库提供了一系列方法来查找特定的XML元素。最常见的方法是使用`find`和`findall`函数。`find`函数用于查找第一个匹配的元素,而`findall`函数用于查找所有匹配的元素。
#### 代码示例
```python
import xml.etree.ElementTree as ET
# 加载XML数据
tree = ET.parse('example.xml')
root = tree.getroot()
# 查找第一个匹配的元素
first_element = root.find('target_element')
# 查找所有匹配的元素
all_elements = root.fi
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python ElementTree.ElementTree 终极指南》专栏是 XML 解析和数据处理的权威指南。它涵盖了 ElementTree.ElementTree 库的各个方面,从基本概念到高级技术。专栏包括以下主题:
* XML 解析和数据提取的最佳实践
* XPath 的高效数据定位
* 可重用 XML 解析模块的构建
* XML 注入攻击的预防
* 多线程 XML 数据处理
* 大型 XML 文件处理的内存管理优化
* 自定义 XML 解析器的创建
* ElementTree.ElementTree 与其他 Python 库的集成
* 错误处理机制和性能测试
* 扩展应用和异步 IO 的未来趋势
本专栏旨在帮助读者深入掌握 ElementTree.ElementTree,并构建专业级的 XML 解析工具。无论您是 XML 新手还是经验丰富的开发者,本专栏都能为您提供宝贵的见解和实践指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
拷贝构造函数的陷阱:防止错误的浅拷贝
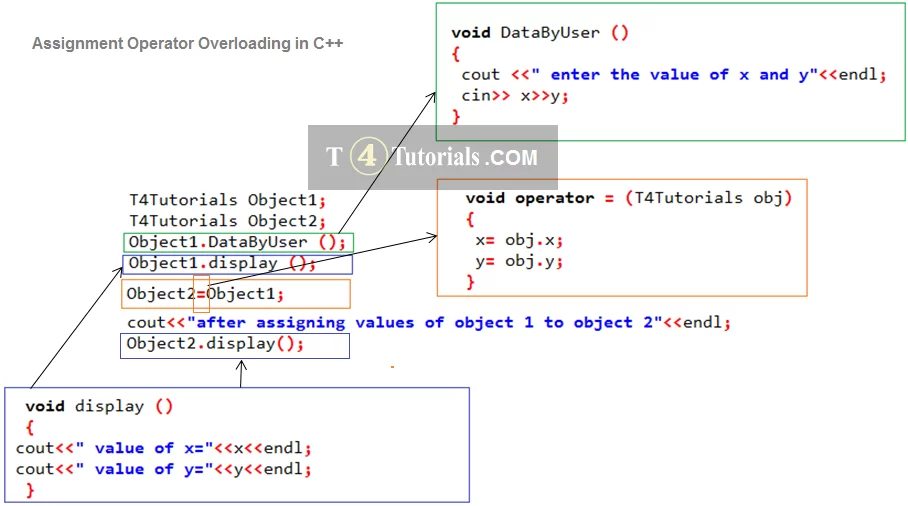
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
全球高可用部署:MySQL PXC集群的多数据中心策略

# 1. 高可用部署与MySQL PXC集群基础
在IT行业,特别是在数据库管理系统领域,高可用部署是确保业务连续性和数据一致性的关键。通过本章,我们将了解高可用部署的基础以及如何利用MySQL Percona XtraDB Cluster (PXC) 集群来实现这一目标。
## MySQL PXC集群的简介
MySQL PXC集群是一个可扩展的同步多主节点集群解决方案,它能够提供连续可用性和数据一致
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
Android二维码框架选择:如何集成与优化用户界面与交互

# 1. Android二维码框架概述
在移动应用开发领域,二维码技术已经成为不可或缺的一部分。Android作为应用广泛的移动操作系统,其平台上的二维码框架种类繁多,开发者在选择适合的框架时需要综合考虑多种因素。本章将为读者概述二维码框架的基本知识、功
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )