Commons-DbUtils快速入门指南:5分钟内掌握简化JDBC数据库访问的秘诀
发布时间: 2024-09-25 20:04:41 阅读量: 75 订阅数: 36 

# 1. 认识Commons-DbUtils
Commons-DbUtils 是 Apache Jakarta Commons 子项目的一个组成部分,它提供了一系列轻量级的数据访问工具,让 Java 程序员能够更加方便地操作数据库。这个库的目标是简化数据访问的复杂性,并减少与数据库进行交互时的样板代码。通过使用 Commons-DbUtils,开发者可以避免直接处理 JDBC 的大量细节,如关闭连接、资源管理和异常处理等。
本章将介绍 Commons-DbUtils 的基础知识,并从简单的使用场景入手,逐步深入到其核心功能和高级技巧,为 IT 专业人士提供一系列高效处理数据库操作的工具。我们将通过代码示例和实际案例,揭示如何在日常开发中利用这个库简化开发流程和提高代码质量。
# 2. Commons-DbUtils核心概念解析
### 2.1 数据库连接管理
#### 2.1.1 DataSource接口与连接池
在进行Java数据库交互时,通常会使用到`DataSource`接口。`DataSource`在`commons-dbutils`库中扮演着非常重要的角色,尤其是在连接池的管理上。`DataSource`可以封装数据库连接的配置信息,包括JDBC URL、用户名和密码,并提供了获取数据库连接的方法。
连接池是一种管理连接资源的技术,它允许应用程序重复使用现有的数据库连接,而不是每次需要时都打开和关闭连接。这极大地提高了应用程序的性能,因为建立数据库连接是一个相对昂贵的操作。
在`commons-dbutils`中,`DataSource`通常与连接池配合使用,最常见的实现是`BasicDataSource`,它提供了线程安全的连接池实现。通过配置`BasicDataSource`的一些属性,如`url`, `username`, `password`, `initialSize`, `maxActive`等,可以满足不同的应用需求。
```java
// 创建连接池实例
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mydb");
dataSource.setUsername("dbuser");
dataSource.setPassword("dbpass");
dataSource.setInitialSize(5);
dataSource.setMaxActive(10);
// 获取连接
Connection conn = dataSource.getConnection();
```
在上述代码段中,我们创建了一个`BasicDataSource`实例,并通过方法链设置了一系列连接池属性。然后通过`getConnection()`方法获取到连接池中的一个数据库连接。
#### 2.1.2 查询执行器与更新执行器
`commons-dbutils`为执行数据库查询和更新操作提供了两个执行器:`QueryRunner`和`UpdateRunner`。`QueryRunner`用于执行查询操作,而`UpdateRunner`用于执行更新操作。
`QueryRunner`类简化了查询操作的过程。它提供了多种方法来执行不同类型查询,如`query()`, `queryObject()`, `queryList()`, `queryMap()`等。这些方法中,每个都接受一个`Connection`和一个`PreparedStatement`,用于执行SQL语句并返回查询结果。
```java
// 使用QueryRunner进行查询
QueryRunner queryRunner = new QueryRunner(dataSource);
try {
String sql = "SELECT id, name FROM users WHERE name = ?";
User user = queryRunner.query(conn, sql, new ScalarHandler<>());
// 处理查询结果
} catch (SQLException e) {
// 处理异常
}
```
`UpdateRunner`类用于执行更新操作,如`insert()`, `update()`, `delete()`。这些方法同样需要一个`Connection`和一个SQL语句,用于执行数据库的增删改操作。
```java
// 使用UpdateRunner执行更新操作
UpdateRunner updateRunner = new UpdateRunner(dataSource);
try {
String sql = "UPDATE users SET name = ? WHERE id = ?";
int updateCount = updateRunner.update(conn, sql, "newName", 1);
// 处理更新结果
} catch (SQLException e) {
// 处理异常
}
```
### 2.2 查询结果处理
#### 2.2.1 查询结果集的封装
`commons-dbutils`中,查询结果的处理通常涉及到了`ResultSetHandler`接口。这个接口的实现类负责将`ResultSet`封装成对象或数据集合。`ResultSetHandler`的常用实现有`BeanHandler`, `BeanListHandler`, `MapHandler`, `MapListHandler`等。
以`BeanHandler`为例,它将`ResultSet`的单个记录封装到Java Bean对象中。例如,我们有一个`User`类:
```java
public class User {
private int id;
private String name;
// getters and setters
}
```
```java
// 使用BeanHandler封装查询结果
BeanHandler<User> handler = new BeanHandler<>(User.class);
User user = queryRunner.query(conn, sql, handler);
// user对象现在包含查询结果的数据
```
通过`BeanHandler`,查询结果中的列值会自动映射到`User`对象的相应属性中。
#### 2.2.2 列值的提取与转换
`commons-dbutils`允许你从`ResultSet`中提取列值,并且可以进行相应的数据转换。它提供了如`ScalarHandler`, `ArrayHandler`, `ColumnListHandler`, `KeyedHandler`等实现,来处理不同类型的数据提取需求。
`ScalarHandler`用于提取单个值,例如执行一个`COUNT()`函数返回的计数值:
```java
// 提取单个查询结果
ScalarHandler handler = new ScalarHandler();
Object count = queryRunner.query(conn, "SELECT COUNT(*) FROM users", handler);
```
`ColumnListHandler`用于提取一列的所有值:
```java
// 提取一列的所有值
ColumnListHandler handler = new ColumnListHandler("name");
List<String> names = queryRunner.query(conn, "SELECT name FROM users", handler);
```
### 2.3 异常处理机制
#### 2.3.1 数据库访问异常的捕获与处理
`commons-dbutils`通过`SQLException`来处理数据库操作过程中可能出现的错误。与传统的`try-catch`块捕获SQL异常不同,`commons-dbutils`提供了`DbUtils`类,其中的`ResultSetHandler`接口的实现类会自动处理异常。通过实现`handleException()`方法,可以在发生异常时进行自定义的异常处理逻辑。
```java
try {
// 执行查询
User user = queryRunner.query(conn, sql, new BeanHandler<>(User.class));
// 处理结果
} catch (SQLException e) {
// 使用DbUtils处理异常
DbUtils.closeQuietly(conn);
// 处理其他异常逻辑
}
```
#### 2.3.2 自定义异常策略
`commons-dbutils`提供了一种方式来定制异常处理策略,允许开发者自定义数据库异常的处理方法。通过继承`DbUtils`类并重写`handleException()`方法,可以实现对特定异常的处理。
```java
public class CustomDbUtils extends DbUtils {
@Override
public void handleException(Throwable th) {
// 实现自定义的异常处理逻辑
if (th instanceof SQLException) {
// 处理SQLException
System.err.println("发生数据库错误:" + th.getMessage());
} else {
// 处理其他类型的异常
System.err.println("发生未知错误:" + th.getMessage());
}
}
}
// 在使用时,使用自定义的DbUtils实现类
CustomDbUtils HANDLE_EXCEPTION = new CustomDbUtils();
```
通过这种方式,开发者可以更加灵活地控制异常处理逻辑,使得程序在发生异常时能够做出更合适的反应。
# 3. Commons-DbUtils实践应用
Commons-DbUtils是一个简单而强大的Java数据库访问工具,它封装了JDBC操作,简化了数据库的CRUD操作。在本章节中,我们将深入探讨如何将Commons-DbUtils应用到实际开发中,包括基础的CRUD操作、高级查询技巧,以及如何将其集成到Spring框架中,实现更加高效的数据库操作。
## 3.1 基础CRUD操作
在数据库的日常操作中,CRUD(创建、读取、更新、删除)是最基本的操作。Commons-DbUtils通过简单的API调用,使得这些操作变得简单而直观。
### 3.1.1 创建记录的实现方法
为了创建一条新的记录,我们通常需要构造一个INSERT SQL语句,并使用DbUtils提供的QueryRunner类。以下是创建记录的一个基本示例:
```***
***mons.dbutils.QueryRunner;
***mons.dbutils.handlers.BeanHandler;
***mons.dbcp2.BasicDataSource;
import javax.sql.DataSource;
public class DbUtilExample {
// 获取DataSource实例
private DataSource dataSource = getDataSource();
private DataSource getDataSource() {
BasicDataSource dataSource = new BasicDataSource();
// 数据库连接配置
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/your_database");
dataSource.setUsername("username");
dataSource.setPassword("password");
return dataSource;
}
public void insertData() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "INSERT INTO users (name, email) VALUES (?, ?)";
Object[] params = {"John Doe", "john.***"};
// 执行更新操作
queryRunner.update(sql, params);
}
}
```
在上述代码中,我们首先通过getDataSource方法配置了数据库连接信息,并通过QueryRunner类的update方法执行了插入操作。注意,使用`?`作为SQL语句的参数占位符,这是为了避免SQL注入攻击。在params数组中传递相应的参数值。
### 3.1.2 查询记录与结果集处理
在数据库中查询记录并处理结果集是CRUD操作中非常常见的需求。Commons-DbUtils提供了强大的ResultSetHandler接口来处理查询结果集。以下是查询并处理结果集的一个示例:
```java
public void selectData() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "SELECT * FROM users WHERE id = ?";
int userId = 1;
// 使用BeanHandler处理查询结果集
UserBean user = queryRunner.query(sql, new BeanHandler<UserBean>(UserBean.class), userId);
System.out.println("User Name: " + user.getName());
System.out.println("User Email: " + user.getEmail());
}
```
在这个例子中,`BeanHandler`是一个实现了ResultSetHandler接口的实例,它会自动将结果集映射到一个UserBean对象。这样,我们可以非常方便地处理查询到的数据。
### 3.1.3 更新与删除操作的步骤
更新(UPDATE)和删除(DELETE)操作同样可以使用QueryRunner类来实现。操作步骤与插入操作类似,主要的区别在于使用的SQL语句类型。
```java
public void updateData() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "UPDATE users SET name = ? WHERE id = ?";
Object[] params = {"Jane Doe", 2};
// 执行更新操作
queryRunner.update(sql, params);
}
public void deleteData() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "DELETE FROM users WHERE id = ?";
int userId = 3;
// 执行删除操作
queryRunner.update(sql, userId);
}
```
在此示例中,更新和删除操作都是通过执行一个SQL语句来完成。需要注意的是,更新操作通常涉及到修改表中已存在的记录,而删除操作则会从表中移除一条记录。
## 3.2 高级查询技巧
对于更复杂的查询需求,Commons-DbUtils也提供了多种高级查询技巧,如分页查询、排序以及条件查询等,使得数据处理更加灵活。
### 3.2.1 分页查询与排序
当数据量较大时,分页查询成为一种常见的需求。Commons-DbUtils允许我们通过SQL语句来实现分页效果。
```java
public void selectDataWithLimitOffset() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "SELECT * FROM users LIMIT ? OFFSET ?";
int limit = 10; // 查询记录数量
int offset = 20; // 查询的起始位置
// 执行分页查询
List<UserBean> userList = queryRunner.query(sql, new BeanListHandler<UserBean>(UserBean.class), limit, offset);
for (UserBean user : userList) {
System.out.println("User Name: " + user.getName());
System.out.println("User Email: " + user.getEmail());
}
}
```
### 3.2.2 条件查询与过滤器使用
条件查询允许用户根据不同的条件来筛选数据, Commons-DbUtils提供了一个过滤器机制,可以灵活地处理不同的查询条件。
```java
public void selectDataWithFilter() throws SQLException {
QueryRunner queryRunner = new QueryRunner(dataSource);
String sql = "SELECT * FROM users WHERE name LIKE ?";
String namePattern = "%John%";
// 使用过滤器来处理参数
Object[] params = {new LikeValue(namePattern)};
// 执行条件查询
List<UserBean> userList = queryRunner.query(sql, new BeanListHandler<UserBean>(UserBean.class), params);
for (UserBean user : userList) {
System.out.println("User Name: " + user.getName());
System.out.println("User Email: " + user.getEmail());
}
}
```
在这个例子中,我们使用了`LikeValue`过滤器来处理LIKE语句的参数,使得参数处理更加灵活和安全。
## 3.3 集成到Spring框架
Commons-DbUtils与Spring框架的集成可以进一步简化数据库访问代码,通过依赖注入和AOP技术,使代码更加简洁、清晰。
### 3.3.1 与Spring的整合方法
在Spring中集成Commons-DbUtils通常涉及配置数据源和`QueryRunner` bean。
```xml
<beans ...>
<!-- 数据源配置 -->
<bean id="dataSource" class="***mons.dbcp2.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/your_database" />
<property name="username" value="username" />
<property name="password" value="password" />
</bean>
<!-- QueryRunner配置 -->
<bean id="queryRunner" class="***mons.dbutils.QueryRunner" depends-on="dataSource">
<constructor-arg ref="dataSource"/>
</bean>
</beans>
```
### 3.3.2 配置文件与依赖注入
接下来,我们可以在我们的Spring组件中使用`@Autowired`注解来注入`QueryRunner`。
```java
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private QueryRunner queryRunner;
// 方法实现省略...
}
```
通过上述配置,我们可以将`QueryRunner`注入到Spring管理的任何组件中,从而在服务层中方便地使用Commons-DbUtils提供的数据库操作功能。
在本章节的实践中,我们详细介绍了Commons-DbUtils在基础CRUD操作和高级查询技巧中的应用,并且探讨了如何将其整合到Spring框架中,以进一步提升开发效率和代码的可维护性。通过对这些内容的学习和实践,开发者可以更加高效地进行数据库操作,同时保证代码的健壮性和安全性。
# 4. Commons-DbUtils进阶技巧
### 4.1 自定义查询处理器
#### 4.1.1 实现自定义的ResultSetHandler
当我们使用Commons-DbUtils处理查询结果时,框架提供的默认处理器可能无法满足所有需求。此时,我们需要实现自定义的ResultSetHandler。通过实现这个接口,我们可以自定义数据的抽取逻辑,以适应复杂的业务场景。
下面是一个实现自定义ResultSetHandler的例子,用于将查询结果集中的数据封装成Java对象:
```***
***mons.dbutils.ResultSetHandler;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
public class UserHandler implements ResultSetHandler<List<User>> {
@Override
public List<User> handle(ResultSet rs) throws SQLException {
List<User> userList = new ArrayList<>();
while (rs.next()) {
User user = new User();
user.setId(rs.getInt("id"));
user.setName(rs.getString("name"));
user.setEmail(rs.getString("email"));
userList.add(user);
}
return userList;
}
}
```
#### 4.1.2 高级数据类型处理实例
除了基本数据类型的处理,Commons-DbUtils还支持对高级数据类型的处理。比如,对于BLOB和CLOB类型的数据,我们可以自定义ResultSetHandler来实现特定的处理逻辑。
```***
***mons.dbutils.ResultSetHandler;
import java.sql.ResultSet;
import java.sql.SQLException;
public class BlobHandler implements ResultSetHandler<byte[]> {
@Override
public byte[] handle(ResultSet rs) throws SQLException {
if (rs.next()) {
return rs.getBytes("image_data");
}
return null;
}
}
```
### 4.2 避免SQL注入与代码优化
#### 4.2.1 参数化查询与SQL注入防护
SQL注入是一种常见的安全威胁,使用参数化查询可以有效地防止此类攻击。Commons-DbUtils通过QueryRunner的update和query方法支持参数化查询。
```***
***mons.dbutils.QueryRunner;
***mons.dbutils.handlers.BeanHandler;
import java.sql.SQLException;
public class DatabaseUtils {
private QueryRunner queryRunner;
public DatabaseUtils(QueryRunner queryRunner) {
this.queryRunner = queryRunner;
}
public User getUserById(int id) throws SQLException {
String sql = "SELECT * FROM users WHERE id = ?";
return queryRunner.query(sql, new BeanHandler<>(User.class), id);
}
}
```
#### 4.2.2 查询优化与性能调优技巧
在处理大量数据时,我们通常需要考虑性能优化。使用合适的索引、优化SQL语句、使用批处理以及减少不必要的数据访问都是常用的优化手段。
```java
public List<User> getUsersBatch(List<Integer> ids) throws SQLException {
String sql = "SELECT * FROM users WHERE id IN (" + StringUtils.repeat("?", ",", ids.size()) + ")";
return queryRunner.query(sql, new BeanHandler<>(User.class), ids.toArray());
}
```
### 4.3 调试与日志记录
#### 4.3.1 内置的日志功能与配置
Commons-DbUtils通过Log接口与外部日志框架如Log4j集成。我们可以在配置文件中设置日志级别来控制日志的输出。
```***
***mons.dbutils=DEBUG
```
#### 4.3.2 日志级别调整与问题追踪
在开发和调试阶段,将日志级别设置为DEBUG有助于我们了解数据库操作的细节。对于生产环境,我们通常将日志级别设置为INFO或ERROR。
```java
// 配置commons-dbutils使用Log4j作为日志框架
BasicConfigurator.configure();
```
在这一章节中,我们介绍了如何实现自定义的ResultSetHandler,以及如何使用参数化查询避免SQL注入。此外,我们也了解了 Commons-DbUtils 内置的日志功能和如何进行配置来辅助调试和问题追踪。这些进阶技巧在日常开发过程中会大大提高开发效率和应用性能。
# 5. 实战案例分析
## 5.1 常见问题解决方案
### 5.1.1 连接池配置问题
在实际项目中,配置连接池是常见的挑战之一。 Commons-DbUtils 本身不提供连接池功能,但是可以很容易地与第三方连接池技术集成,如 HikariCP、Apache DBCP 等。
在配置连接池时,一些常见的问题包括:连接池参数设置不当导致性能问题、数据库连接泄露、初始化时间长等。
以 HikariCP 为例,配置连接池的参数需要考虑以下因素:
- **maximumPoolSize**: 这个参数定义了连接池中允许的最大连接数。设置值应基于应用的数据库并发连接数,通常为数据库允许的最大连接数的75%-80%。
- **connectionTimeout**: 用于设置获取连接的等待超时时间。单位是毫秒。
- **idleTimeout**: 用于设置连接在池中保持空闲而不被回收的最长时间。单位也是毫秒。
- **minIdle**: 连接池保持的最小空闲连接数。
以下是一个简单的 HikariCP 配置示例:
```java
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydatabase");
config.setUsername("user");
config.setPassword("password");
config.addDataSourceProperty("cachePrepStmts", "true");
config.addDataSourceProperty("prepStmtCacheSize", "250");
config.addDataSourceProperty("prepStmtCacheSqlLimit", "2048");
config.setMaximumPoolSize(10);
config.setConnectionTimeout(30000);
config.setIdleTimeout(600000);
HikariDataSource ds = new HikariDataSource(config);
```
通过调整上述参数,可以有效解决连接池配置问题,提升应用性能。
### 5.1.2 跨数据库平台兼容性问题
跨数据库平台的兼容性问题是 IT 行业普遍存在的挑战。不同数据库厂商的 SQL 语法有所差异,导致在使用 Commons-DbUtils 时需要编写可移植的 SQL 语句。
解决这一问题可以考虑以下策略:
- 使用面向 SQL 标准的数据库操作。
- 利用抽象层工具,如 JPA 或 Hibernate,它们提供了跨数据库的抽象层。
- 编写针对特定数据库的自定义查询处理器,以处理特定的 SQL 功能。
例如,我们可以创建一个抽象层的接口,然后为不同的数据库提供具体的实现:
```java
public interface DatabaseService {
void executeUpdate(String sql);
List<Map<String, Object>> executeQuery(String sql);
}
public class PostgresDatabaseService implements DatabaseService {
@Override
public void executeUpdate(String sql) {
// PostgreSQL 特定的实现
}
@Override
public List<Map<String, Object>> executeQuery(String sql) {
// PostgreSQL 特定的实现
}
}
public class MysqlDatabaseService implements DatabaseService {
@Override
public void executeUpdate(String sql) {
// MySQL 特定的实现
}
@Override
public List<Map<String, Object>> executeQuery(String sql) {
// MySQL 特定的实现
}
}
```
## 5.2 项目中的最佳实践
### 5.2.1 代码复用与模块化
代码复用和模块化是提升软件开发效率和可维护性的重要实践。在使用 Commons-DbUtils 时,可以通过实现可复用的工具类来提高开发效率。
例如,我们可以创建一个通用的数据库操作工具类,将常用的查询、更新操作封装成可复用的方法:
```java
public class DatabaseUtil {
private static QueryRunner queryRunner = new QueryRunner(DataSourceUtils.getDataSource());
public static List<Map<String, Object>> query(String sql) {
try {
return queryRunner.query(sql, new ResultSetHandler<List<Map<String, Object>>>() {
@Override
public List<Map<String, Object>> handle(ResultSet rs) throws SQLException {
List<Map<String, Object>> list = new ArrayList<>();
while (rs.next()) {
// 处理结果集
}
return list;
}
});
} catch (SQLException e) {
e.printStackTrace();
// 异常处理
}
return null;
}
public static int update(String sql) {
try {
return queryRunner.update(sql);
} catch (SQLException e) {
e.printStackTrace();
// 异常处理
}
return 0;
}
}
```
在以上代码中,`DatabaseUtil` 类封装了通用的查询和更新操作,这些方法可以直接在项目中的不同模块进行调用,提高代码复用性。
### 5.2.2 高可用性与故障转移配置
为了保证系统在数据库层面上的高可用性,需要配置故障转移和自动切换机制。常用的手段包括使用主从复制、读写分离以及心跳检测等。
以 Commons-DbUtils 结合 Apache DBCP 进行读写分离和故障转移配置为例,可以采用以下步骤:
1. 配置主数据库连接池和从数据库连接池。
2. 在 Commons-DbUtils 中实现自定义的数据源,将读写操作分别路由到主从数据库。
3. 配置故障检测逻辑,当检测到主数据库不可用时,自动切换到从数据库。
```java
// 主数据库连接池配置
BasicDataSource masterDs = new BasicDataSource();
masterDs.setUrl("jdbc:mysql://master_db_host:3306/mydb");
masterDs.setUsername("master_user");
masterDs.setPassword("master_pass");
// 从数据库连接池配置
BasicDataSource slaveDs = new BasicDataSource();
slaveDs.setUrl("jdbc:mysql://slave_db_host:3306/mydb");
slaveDs.setUsername("slave_user");
slaveDs.setPassword("slave_pass");
// 自定义数据源,封装读写逻辑
public class MasterSlaveDataSource extends AbstractDataSource {
private DataSource masterDs;
private DataSource slaveDs;
private ThreadLocal<Boolean> accessMaster = new ThreadLocal<>();
public MasterSlaveDataSource(DataSource masterDs, DataSource slaveDs) {
this.masterDs = masterDs;
this.slaveDs = slaveDs;
}
public void setAccessMaster(boolean accessMaster) {
this.accessMaster.set(accessMaster);
}
@Override
public Connection getConnection() throws SQLException {
return isAccessMaster() ? masterDs.getConnection() : slaveDs.getConnection();
}
@Override
public Connection getConnection(String username, String password) throws SQLException {
return isAccessMaster() ? masterDs.getConnection(username, password) : slaveDs.getConnection(username, password);
}
private boolean isAccessMaster() {
Boolean master = accessMaster.get();
return master == null || master;
}
}
// 在业务代码中使用自定义数据源
MasterSlaveDataSource masterSlaveDs = new MasterSlaveDataSource(masterDs, slaveDs);
// 读操作
masterSlaveDs.setAccessMaster(false);
// 写操作
masterSlaveDs.setAccessMaster(true);
```
通过上述配置,应用可以在主数据库不可用时自动切换到从数据库,保证服务的高可用性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入介绍了 Commons-DbUtils 库,这是一个 Java 数据库访问库,可简化 JDBC 编程。专栏涵盖了从入门指南到高级使用技巧的广泛主题。读者将学习如何使用 DbUtils 执行数据库查询、处理结果集、管理连接池和处理异常。此外,专栏还探讨了 DbUtils 在复杂查询、事务处理、性能优化和安全性方面的应用。通过本专栏,Java 开发人员可以掌握 DbUtils 的强大功能,并提高其数据库操作的效率和可靠性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【打印不求人】:用这3个技巧轻松优化富士施乐AWApeosWide 6050质量!
# 摘要
富士施乐AWApeosWide 6050打印机是一款先进的办公设备,为用户提供高质量的打印输出。本文首先介绍该打印机的基本情况,随后探讨打印质量优化的理论基础,包括墨水和纸张选择、打印分辨率、驱动程序的作用以及色彩管理与校准的重要性。接着,通过高级打印设置的实践技巧,展示了如何通过页面布局、打印选项以及文档优化等方法提高打印质量。此外,本文还强调了打印机的日常维护和深度清洁对于保持打印设备性能的必要性,并提供了故障诊断与处理的具体方法。最终,通过综合案例分析,总结了在实际操作中提升打印质量的关键步骤和技巧的拓展应用。
# 关键字
富士施乐AWApeosWide 6050;打印质量优
【电磁兼容性分析】:矩量法在设计中的巧妙应用

# 摘要
本文全面介绍了电磁兼容性与矩量法,系统阐述了矩量法的理论基础、数学原理及其在电磁分析中的应用。通过深入探讨麦克斯韦方程组、电磁波传播与反射原理,本文阐述了矩量法在电磁干扰模拟、屏蔽设计和接地系统设计中的实际应用。同时,文章还探讨了矩量法与其他方法结合的可能性,并对其在复杂结构分析和新兴技术中的应用前景进行了展望。最后,通过案例研究与分析,展示了矩量法在电磁兼容性设计中的有效性
RS485通信优化全攻略:偏置与匹配电阻的计算与选择技巧
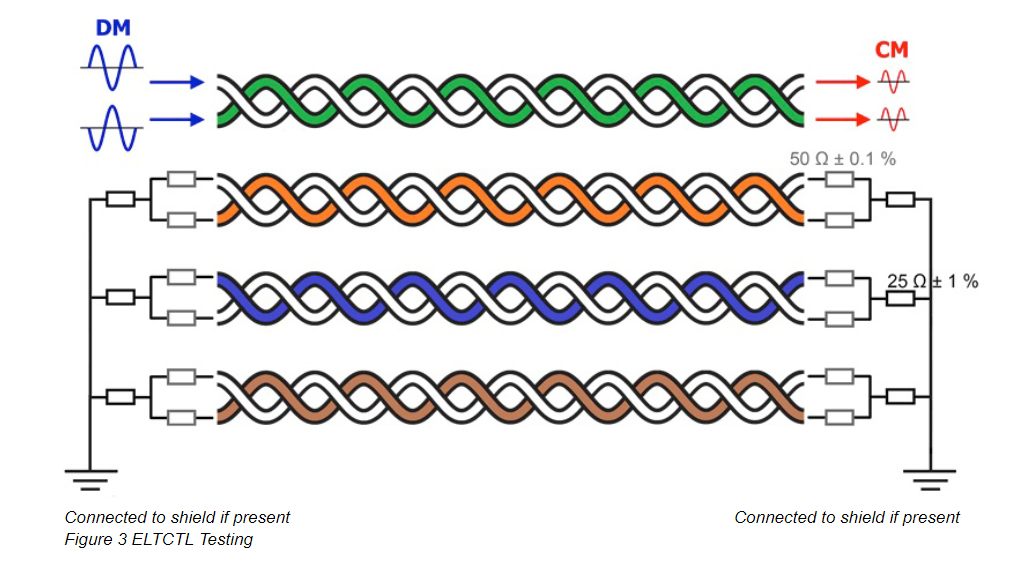
# 摘要
RS485通信作为工业界广泛采用的一种串行通信标准,其在工业自动化、智能建筑和远程监控系统中的应用需求不断增长。本文首先介绍RS485通信的基础知识和关键组件,包括RS485总线技术原理、偏置电阻和匹配电阻的选择与作用。接着,深入探讨了RS485通信的实践优化策略,如通信速率与距离的平衡、抗干扰技术与信号完整性分析,以及通信协议与软件层面的性能
【软件安装难题解决方案】:Win10 x64系统中TensorFlow的CUDA配置攻略

# 摘要
本文旨在详细探讨TensorFlow与CUDA的集成配置及其在深度学习中的应用实践。首先,介绍了TensorFlow和CUDA的基础知识,CUDA的发展历程及其在GPU计算中的优势。接着,本文深入讲解了在Windows
【可视化混沌】:李雅普诺夫指数在杜芬系统中的视觉解析
# 摘要
混沌理论为理解复杂动态系统提供了深刻洞见,其中李雅普诺夫指数是评估系统混沌程度的关键工具。本文首先对李雅普诺夫指数进行数学上的概念界定与计算方法介绍,并分析不同混沌系统中的特征差异。随后,通过对杜芬系统进行动态特性分析,探讨了系统参数变化对混沌行为的影响,以及通过数值模拟和可视化技术,如何更直观地理解混沌现象。本文深入研究了李雅普诺夫指数在系统稳定性评估和混沌预测中的应用,并展望了其在不同领域中的拓展应用。最后,结论章节总结了李雅普诺夫指数的研究成果,并讨论了未来的研究方向和技术趋势,强调了技术创新在推动混沌理论发展中的重要性。
# 关键字
混沌理论;李雅普诺夫指数;杜芬系统;动态
【TwinCAT 2.0架构揭秘】:专家带你深入了解系统心脏
# 摘要
本文全面探讨了TwinCAT 2.0的架构、核心组件、编程实践以及高级应用。首先对TwinCAT 2.0的软件架构进行概览,随后深入分析其核心组件,包括实时内核、任务调度、I/O驱动和现场总线通信。接着,通过编程实践章节,本文阐述了PLC编程、通讯与数据交换以及系统集成与扩展的关键技术。在高级应用部分,着重介绍了实时性能优化、安全与备份机制以及故障诊断与维护策略。最后,通过应用案例分析,展示了TwinCAT 2.0在工业自动化、系统升级改造以及技术创新应用中的实践与效果。本文旨在为工业自动化专业人士提供关于TwinCAT 2.0的深入理解和应用指南。
# 关键字
TwinCAT 2
【MATLAB决策树C4.5调试全攻略】:常见错误及解决之道

# 摘要
本文全面介绍了MATLAB实现的C4.5决策树算法,阐述了其理论基础、常见错误分析、深度实践及进阶应用。首先概述了决策树C4.5的工作原理,包括信息增益和熵的概念,以及其分裂标准和剪枝策略。其次,本文探讨了在MATLAB中决策树的构建过程和理论与实践的结合
揭秘数据库性能:如何通过规范建库和封装提高效率
# 摘要
本文详细探讨了数据库性能优化的核心概念,从理论到实践,系统地分析了规范化理论及其在性能优化中的应用,并强调了数据库封装与抽象的重要性。通过对规范化和封装策略的深入讨论,本文展示了如何通过优化数据库设计和操作封装来提升数据库的性能和维护性。文章还介绍了性能评估与监控的重要性,并通过案例研究深入剖析了如何基于监控数据进行有效的性能调优。综合应用部分将规范化与封装集成到实际业务
【宇电温控仪516P维护校准秘籍】:保持最佳性能的黄金法则

# 摘要
宇电温控仪516P是一款广泛应用于工业和实验室环境控制的精密设备。本文综述了其维护基础、校准技术和方法论以及高级维护技巧,并探讨了在不同行业中的应用和系统集成的注意事项。文章详细阐述了温控仪516P的结构与组件、定期检查与预防性维护、故障诊断与处理、校准工具的选择与操作流程以及如何通过高级维护技术提升性能。通过对具体案例的分析,本文提供了故障解决和维护优化的实操指导,旨在为工程技术人员提供系统的温控仪维护与
QZXing集成最佳实践:跨平台二维码解决方案的权威比较

# 摘要
随着移动设备和物联网技术的快速发展,二维码作为一种便捷的信息交换方式,其应用变得越来越广泛。QZXing库以其强大的二维码编码与解码功能,在多平台集成与自定义扩展方面展现出了独特的优势。本文从QZXing的核心功能、跨平台集成策略、高级应用案例、性能优化与安全加固以及未来展望与社区贡献等方面进行深入探讨
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )