【动态SQL构建策略】:Commons-DbUtils与灵活SQL语句的碰撞
发布时间: 2024-09-25 21:13:55 阅读量: 97 订阅数: 31 

commons-dbutils.jar.rar

# 1. 动态SQL构建的基础知识
在开始探讨动态SQL构建的高级技巧之前,我们需要打下坚实的基础知识。本章节将从动态SQL的基本概念开始,逐步引导读者深入理解动态SQL的重要性和实际应用场景。
## 1.1 动态SQL的定义
动态SQL是一种在运行时根据条件动态构建SQL语句的技术。它允许开发者根据不同的业务逻辑和数据状态生成不同的SQL查询,这在复杂的应用场景中尤其有用。
## 1.2 动态SQL的必要性
由于业务需求的多变性,预先定义好的静态SQL往往难以适应所有的查询需求。动态SQL能够提供更大的灵活性,使得应用程序能够通过参数化的方式构造查询,从而提高代码的复用性和系统的可维护性。
## 1.3 动态SQL与静态SQL的对比
与静态SQL相比,动态SQL虽然在某些方面增加了复杂度,但也提供了更高的灵活性和适应性。静态SQL适用于查询条件和结构固定的场景,而动态SQL可以适应多变的查询需求,是解决复杂查询问题的有效手段。
在后续章节中,我们将深入探讨Commons-DbUtils框架的细节,以及如何在实际开发中运用动态SQL构建技术来解决实际问题。
# 2. Commons-DbUtils框架解析
## 2.1 Commons-DbUtils的核心组件
### 2.1.1 查询处理器(QueryRunner)
`QueryRunner` 是 Commons-DbUtils 框架中的核心类之一,它负责执行基本的数据库操作,如插入、更新、删除和查询。使用 `QueryRunner` 类可以让这些操作变得非常简单和方便,因为它抽象了底层的 `java.sql` API。
下面是一个使用 `QueryRunner` 执行查询操作的示例代码:
```***
***mons.dbutils.QueryRunner;
***mons.dbutils.handlers.BeanHandler;
***mons.dbutils.QueryRunner;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
public class DbUtilsExample {
private DataSource dataSource;
// 假设已经初始化了dataSource
// ...
public <T> T query(String sql, ResultSetHandler<T> rsh) {
QueryRunner qr = new QueryRunner(dataSource);
try {
return qr.query(sql, rsh);
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
DbUtilsExample example = new DbUtilsExample();
String sql = "SELECT * FROM users WHERE id = ?";
BeanHandler<User> handler = new BeanHandler<>(User.class);
User user = example.query(sql, handler);
if (user != null) {
System.out.println("Name: " + user.getName());
}
}
}
```
在这个示例中,`query` 方法接受 SQL 语句和一个 `ResultSetHandler`,然后使用 `QueryRunner` 执行查询并返回处理结果。这里 `BeanHandler` 用于将结果集中的行映射到一个 `User` 类的实例。
**参数说明和逻辑分析:**
- `QueryRunner`: 这是执行数据库操作的主要类,它使用传入的 `DataSource` 来获取数据库连接。
- `BeanHandler`: 这是一个 `ResultSetHandler` 的实现,用于将结果集中的第一行数据自动转换为 JavaBean 对象。
- `dataSource`: 这是一个 `DataSource` 对象,它代表了数据库连接的来源,根据不同的配置(如连接池或直接连接)可以有不同的实现。
### 2.1.2 数据处理助手(ResultSetHandler)
`ResultSetHandler` 是处理 `java.sql.ResultSet` 的接口,用于将 `ResultSet` 中的数据转换成所需的形式。 Commons-DbUtils 提供了多种实现,如 `BeanHandler`、`ScalarHandler` 等,可以处理不同类型的数据映射。
下面是一个使用 `ResultSetHandler` 实现自定义数据处理逻辑的示例代码:
```***
***mons.dbutils.ResultSetHandler;
***mons.dbutils.QueryRunner;
***mons.dbutils.handlers.ScalarHandler;
import java.sql.Connection;
import java.sql.SQLException;
public class CustomResultSetHandler {
private QueryRunner queryRunner;
// 初始化QueryRunner
// ...
public Object query(String sql) {
try {
return queryRunner.query(sql, new ResultSetHandler<Object>() {
@Override
public Object handle(ResultSet rs) throws SQLException {
if (rs.next()) {
// 自定义处理逻辑,例如聚合数据
return rs.getObject(1);
}
return null;
}
});
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
CustomResultSetHandler handler = new CustomResultSetHandler();
String sql = "SELECT COUNT(*) FROM users";
Long count = (Long) handler.query(sql);
System.out.println("Total users: " + count);
}
}
```
在这个示例中,我们使用一个匿名类实现了 `ResultSetHandler` 接口,以便执行一些自定义的处理逻辑(例如,统计数据库中的用户总数)。
**参数说明和逻辑分析:**
- `ScalarHandler`: 它实现了 `ResultSetHandler` 接口,用于从结果集中提取单个值,比如用于 `COUNT(*)` 这样的聚合查询。
- `rs.getObject(1)`: 这里获取结果集中第一列的值,由于是聚合查询,这里假设结果集中只有一行一列。
### 2.2 Commons-DbUtils在动态SQL中的作用
#### 2.2.1 动态SQL的构建基础
动态SQL是指在程序运行时,根据业务逻辑动态构建SQL语句。Commons-DbUtils 通过提供数据处理助手(`ResultSetHandler`)和查询处理器(`QueryRunner`)简化了动态SQL的构建过程。
在动态SQL的构建中,`QueryRunner` 提供了 `update` 方法来执行插入、更新、删除等操作,而 `ResultSetHandler` 可以与查询结果动态交互。
#### 2.2.2 Commons-DbUtils提供的SQL模板功能
Commons-DbUtils 本身并不直接提供SQL模板功能,但其设计理念与SQL模板相契合。开发者可以结合模板引擎如 Apache Velocity 或 FreeMarker 来创建SQL模板,并通过 Commons-DbUtils 来执行这些模板产生的动态SQL语句。
例如,使用 Apache Velocity 生成动态SQL:
```java
import org.apache.velocity.app.VelocityEngine;
import org.apache.velocity.VelocityContext;
import org.apache.velocity.Template;
import org.apache.velocity.runtime.resource.loader.ClasspathResourceLoader;
// Velocity配置和模板使用代码...
VelocityContext context = new VelocityContext();
context.put("id", 1);
Template template = velocityEngine.getTemplate("sql_template.vm", "UTF-8");
StringWriter writer = new StringWriter();
template.merge(context, writer);
String sql = writer.toString();
// 使用QueryRunner执行上述生成的SQL...
```
在这个示例中,我们使用 Apache Velocity 模板引擎来生成 SQL 语句,然后使用 `QueryRunner` 的 `query` 方法执行这个 SQL。
**逻辑分析:**
- `VelocityEngine`: 这是 Velocity 模板引擎的主要类,用于配置和初始化模板引擎。
- `VelocityC

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入介绍了 Commons-DbUtils 库,这是一个 Java 数据库访问库,可简化 JDBC 编程。专栏涵盖了从入门指南到高级使用技巧的广泛主题。读者将学习如何使用 DbUtils 执行数据库查询、处理结果集、管理连接池和处理异常。此外,专栏还探讨了 DbUtils 在复杂查询、事务处理、性能优化和安全性方面的应用。通过本专栏,Java 开发人员可以掌握 DbUtils 的强大功能,并提高其数据库操作的效率和可靠性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
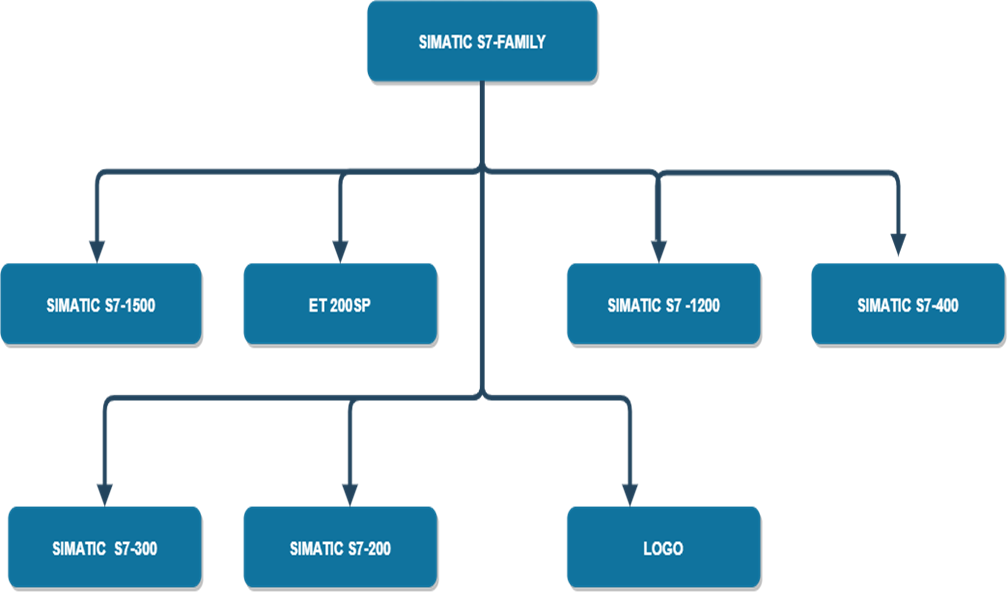
S7-1500 PLC编程实战手册:图形化编程技巧深度揭秘
# 摘要
随着自动化和智能制造的快速发展,S7-1500 PLC编程技术的应用变得日益广泛。本文首先介绍了S7-1500 PLC的基本编程概念及其在TIA Portal环境下的图形化编程基础,随后探讨了编程中的高级技巧,如数据类型处理、功能块应用以及异常处理和优化。接着,文中分析了图形化编程在实践中的应用案例,从自动化项目的需求分析到高级控制策略的实现。在问题诊断与解决章节,讨论了编程错误的识别、性能分析以
Halcon函数应用全解读

# 摘要
本文全面介绍了Halcon软件在图像处理与机器视觉领域的应用。首先概述了Halcon的基础知识和软件特性,然后详细阐述了Halcon函数在图像预处理、特征提取、图像分割和目标识别中的具体应用。接着,文章通过实战案例,深入探讨了相机标定、三维重建、表面检测和运动目标跟踪等关键技术。此外,本文还提供了Halcon函数的高级开发技巧,包括图像分析算法的实现、自定义工具
PELCO-D协议全面解读:数据传输与优化策略

# 摘要
本文对PELCO-D协议进行了全面的介绍和分析,包括协议的基本理论、实践应用、高级功能以及未来的发展趋势。PELCO-D是一种广泛应用于监控系统中的通信协议,用于控制和管理相机等设备。文章首先概述了PELCO-D协议的基本概念,然后深入探讨了其数据格式、控制命令和通信机制。在实践应用方面,本文讨论了PELCO-D在监控系统中的集成步骤、数据加密和安全机制,以及性能优化的实践策略。高级功能与案例分析章节进一步探讨了扩展命
解决Tecplot标注难题:希腊字母和数学符号的精确操控秘籍

# 摘要
Tecplot软件广泛应用于技术绘图和数据可视化领域,其强大的标注功能对于提升图形和报告的专业性至关重要。本文详细介绍了希腊字母及数学符号在Tecplot中的精确应用方法,包括标准与非标准希腊字母的输入技巧、自定义方法以及数学符号的分类、功能和输入技巧。此外,本文还探讨了Tecplot标注功能的深度定制,强调了用户自定义标注功能的重要性,并提供了脚本基础和高级应用的指导。文章
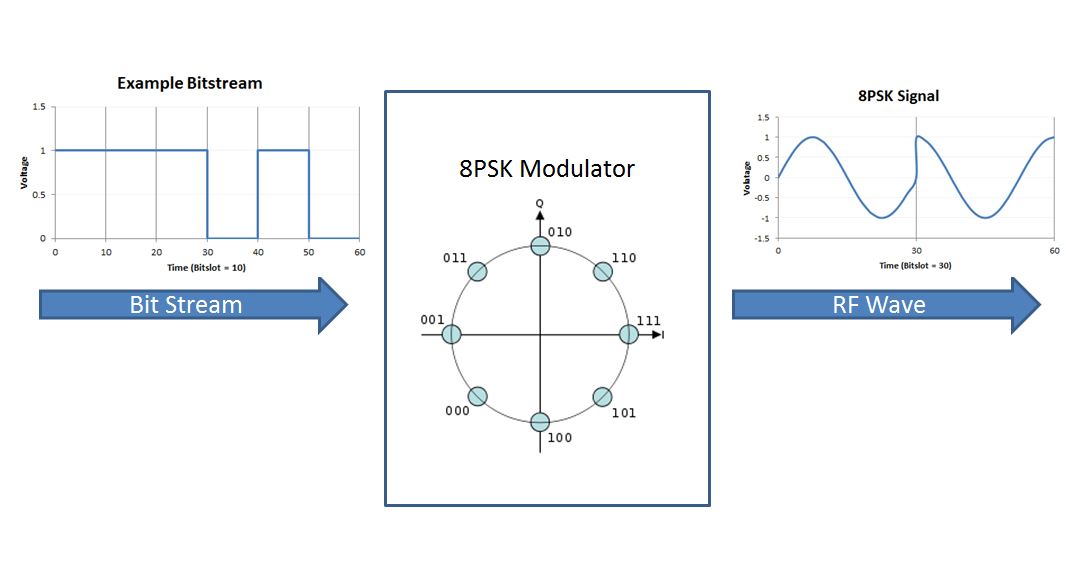
手机射频技术实战指南:WIFI_BT_GPS性能优化与信号强度提升技巧
# 摘要
本文综述了手机射频技术的现状与挑战,首先介绍了射频技术的基本原理和性能指标,探讨了灵敏度、功率、信噪比等关键性能指标的定义及影响。然后,针对WIFI性能优化,深入分析了MIMO、波束成形技术以及信道选择和功率控制策略。对于蓝牙技术,探讨了BLE技术特点和优化信号覆盖范围的方法。最后,本文研究了GPS信号捕获、定位精度改进和辅
雷达信号处理的关键:MATLAB中的回波模拟与消除技巧

# 摘要
雷达信号处理是现代雷达系统中至关重要的环节,涉及信号的数学建模、去噪、仿真实现和高级处理技术。本文首先概述雷达信号处理的基本概念,随后深入介绍MATLAB在雷达信号处理中的应用,包括编程基础、工具箱的利用及信号仿真。文章重点探讨了雷达回波信号的数学描述、噪声分析、去噪技术以及回波消除方法,并讨论了自适应信号处理技术、空间和频率域处理方法以及MUSIC算法。最后,通过案例分析展示了MATLAB在
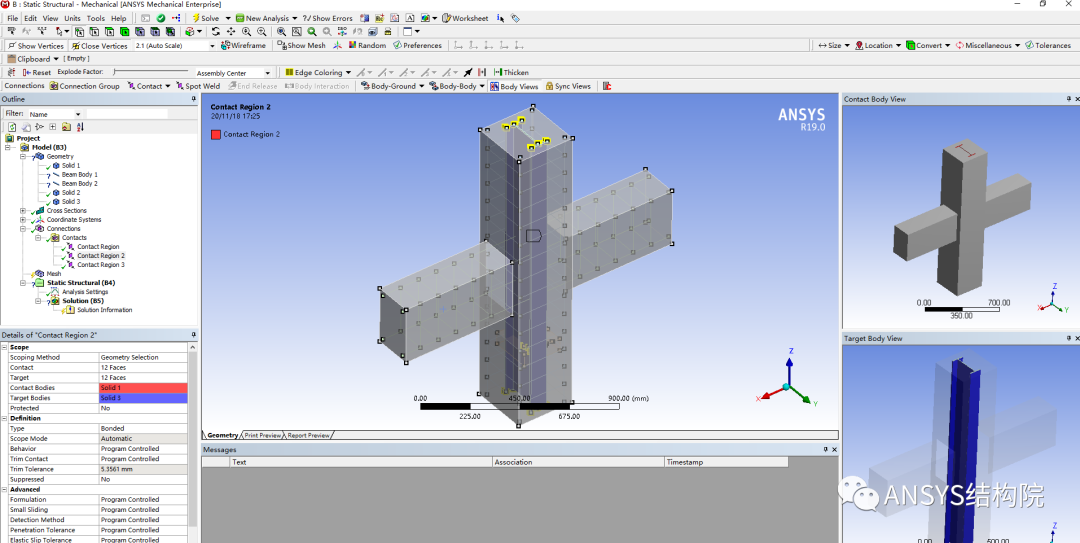
【CAD数据在ANSYS中完美预处理】:专业清理与准备指南
# 摘要
随着工程设计复杂性的增加,CAD数据的处理和ANSYS预处理成为了确保仿真分析准确性的重要步骤。本文详细探讨了从CAD数据导入、组织管理到几何处理的完整流程,强调了数据清理、简化与重构的技巧,以及网格划分的重要性。此外,文章还讨论了如何在ANSYS中准确地定义材料属性和载荷,以及为动态分析做准备。最后,本文展望了预处理流程自动化和优化的可能性,并分析了工程师在预处
【GNU-ld-V2.30链接脚本秘籍】:从入门到实践的快速指南

# 摘要
GNU ld链接器作为重要的工具,它在程序构建过程中扮演着至关重要的角色。本文深入解析了GNU ld链接器的基础知识、链接脚本的核心概念,并探讨了链接脚本的高级功能和组织结构。通过对实战演练的分析,本文提供了基本与高级链接脚本技术应用的实例,并详细讨论了脚本的调试
银河麒麟桌面系统V10 2303版本特性全解析:专家点评与优化建议
# 摘要
本文综合分析了银河麒麟桌面系统V10 2303版本的核心更新、用户体验改进、性能测试结果、行业应用前景以及优化建议。重点介绍了系统架构优化、用户界面定制、新增功能及应用生态的丰富性。通过基准测试和稳定性分析,评估了系统的性能和安全特性。针对不同行业解决方案和开源生态合作进行了前景探讨,同时提出了面临的市场挑战和对策。文章最后提出了系统优化方向和长期发展愿景,探讨了技术创新和对国产操作系统生态的潜在贡献。
# 关键字
银河麒麟桌面系统;系统架构;用户体验;性能评测;行业应用;优化建议;技术创新
参考资源链接:[银河麒麟V10桌面系统专用arm64架构mysql离线安装包](http
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )