




Java Scanner高级用法:正则表达式与分隔符处理


Java正则表达式Pattern和Matcher原理详解
1. Java Scanner类概述
Java中的Scanner类是一个用于解析原始类型和字符串的简单文本扫描器。它能将基本类型和字符串分割成标记(token),并为开发者提供一系列有用的方法来获取这些标记。
在本章中,我们将从基础开始,探讨Scanner类的基本功能和用途。我们将学习如何创建Scanner实例,以及如何利用它来读取不同类型的输入数据,包括从文件、标准输入流或字符串等来源中读取数据。本章旨在为读者打下坚实的基础,为后续章节中深入探讨Scanner类的高级用法,如正则表达式匹配、分隔符处理机制、进阶特性和最佳实践等做好铺垫。

在上述简单的Java程序中,我们创建了一个Scanner对象,用于从标准输入读取一行文本和一个整数,并在读取完后关闭了Scanner。这个例子演示了Scanner类最基础的用法,为理解后续的高级特性和应用做好准备。
2. 正则表达式在Scanner中的应用
在Java中,正则表达式是一种强大的文本处理工具,可以用于匹配、查找和替换符合特定模式的字符串。它广泛应用于数据分析、文本提取、日志分析等场景中。 Scanner类提供了与正则表达式结合使用的接口,允许用户根据复杂的模式来解析输入数据。本章将探讨如何在Scanner中应用正则表达式,包括正则表达式的基础知识、Scanner类与正则表达式的结合使用、以及实际案例的分析。
2.1 正则表达式基础
正则表达式是描述字符模式的字符串,它由一系列的字符和操作符构成。了解正则表达式的基础知识对于有效利用Scanner类解析数据至关重要。
2.1.1 正则表达式的组成和语法规则
正则表达式由普通字符(如字母和数字)以及特殊字符(称为"元字符")组成。普通字符在正则表达式中表示自己,而元字符则具有特殊的含义。
以下是一些常见的元字符及其含义:
.:匹配除换行符以外的任意单个字符。*:匹配前面的子表达式零次或多次。+:匹配前面的子表达式一次或多次。?:匹配前面的子表达式零次或一次。{n}:匹配确定的n次。{n,}:至少匹配n次。{n,m}:最少匹配n次且最多匹配m次。[abc]:匹配括号中的任意一个字符。[^abc]:匹配不在括号中的任意字符。(pattern):匹配模式,并记住匹配项。|:或运算符,匹配左右任一表达式。
2.1.2 正则表达式的捕获和非捕获组
在正则表达式中,捕获组可以通过括号()来定义,它使得匹配的子字符串可以被保存供以后引用。非捕获组则用(?:)定义,仅用于分组而不保存匹配的内容。
- String input = "123.456.789";
- Pattern pattern = ***pile("(\\d+)\\.(\\d+)\\.(\\d+)");
- Matcher matcher = pattern.matcher(input);
- if (matcher.matches()) {
- System.out.println("完整匹配: " + matcher.group(0));
- System.out.println("第一组捕获: " + matcher.group(1));
- System.out.println("第二组捕获: " + matcher.group(2));
- System.out.println("第三组捕获: " + matcher.group(3));
- }
代码解释:上述代码使用了正则表达式来匹配三个由点分隔的数字序列,并分别捕获每一组数字。
2.2 Scanner类与正则表达式的结合使用
2.2.1 利用正则表达式进行文本匹配
Scanner类可以和正则表达式结合使用,对输入文本进行模式匹配。通过useDelimiter()方法可以设置Scanner使用的分隔符模式,这使得Scanner能够识别复杂的文本结构。
- String input = "John Doe - 30 - 75kg";
- Scanner scanner = new Scanner(input);
- scanner.useDelimiter("\\s*[-]\\s*"); // 设置分隔符为" - "
- while (scanner.hasNext()) {
- System.out.println(scanner.next()); // 输出每个匹配的元素
- }
代码解释:上述代码将输入文本按照" - "进行分割,从而匹配并输出姓名、年龄和体重等信息。
2.2.2 正则表达式在Scanner中的高级匹配技巧
在高级匹配中,可以使用正则表达式的特殊模式来提取结构化数据。例如,使用命名捕获组来更清晰地标识每个匹配的子字符串。
- String input = "2023-01-01 12:00:00";
- Scanner scanner = new Scanner(input);
- scanner.useDelimiter("(\\d{4}-\\d{2}-\\d{2})|(\\d{2}:\\d{2}:\\d{2})");
- while (scanner.hasNext()) {
- if (scanner.hasNext("\\d{4}-\\d{2}-\\d{2}")) {
- System.out.println("日期: " + scanner.next());
- } else if (scanner.hasNext("\\d{2}:\\d{2}:\\d{2}")) {
- System.out.println("时间: " + scanner.next());
- }
- }
代码解释:上述代码使用正则表达式来匹配日期和时间格式,并根据匹配的内容输出相应的日期或时间。
2.3 实际案例分析
2.3.1 使用Scanner解析复杂的日志文件
日志文件通常包含了大量结构化或半结构化的数据。使用Scanner结合正则表达式可以有效解析这些数据,提取出关键信息。
- String logEntry = "ERROR: User 'john_doe' failed to authenticate at 2023-01-01 13:45:30";
- Scanner scanner = new Scanner(logEntry);
- scanner.useDelimiter("[:\\s]+");
- while (scanner.hasNext()) {
- if (scanner.hasNext("ERROR")) {
- System.out.println("错误类型: " + scanner.next());
- } else if (scanner.hasNext("User '[^']+'")) {
- System.out.println("用户: " + scanner.next());
- } else if (scanner.hasNext("\\d{4}-\\d{2}-\\d{2} \\d{2}:\\d{2}:\\d{2}")) {
- System.out.println("发生时间: " + scanner.next());
- }
- }
代码解释:通过逐个匹配日志文件中的字符串,我们可以提取出错误类型、用户信息和具体时间等关键数据。
2.3.2 结合正则表达式提取特定格式数据
在处理特定格式的数据时,正则表达式可以提供更为精确和灵活的匹配能力。例如,提取Email地址、电话号码等。
- String input = "Contact us: *** or call 123-456-7890";
- Scanner scanner = new Scanner(input);
- scanner.useDelimiter("[^\\w@.]+"); // 使用非单词字符、@和点作为分隔符
- while (scanner.hasNext()) {
- String match = scanner.next();
- if (match.matches("[\\w.]+@[\\w.]+")) {
- System.out.println("Email: " + match);
- } else if (match.matches("\\d{3}-\\d{3}-\\d{4}")) {
- System.out.println("电话: " + match);
- }
- }
代码解释:正则表达式[^\\w@.]+将匹配非单词、非点和非@符号的字符序列作为分隔符。在匹配到的字符串中,通过进一步的正则表达式匹配来识别Email地址和电话号码。
正则表达式为Scanner提供了一种强大的方式来解析和处理文本数据。通过理解正则表达式的组成和语法规则,结合Scanner类的灵活使用,可以极大地提高数据解析的准确性和效率。在实际案例中,这种技术组合被广泛应用于日志分析、数据提取以及多种文本处理场景中。
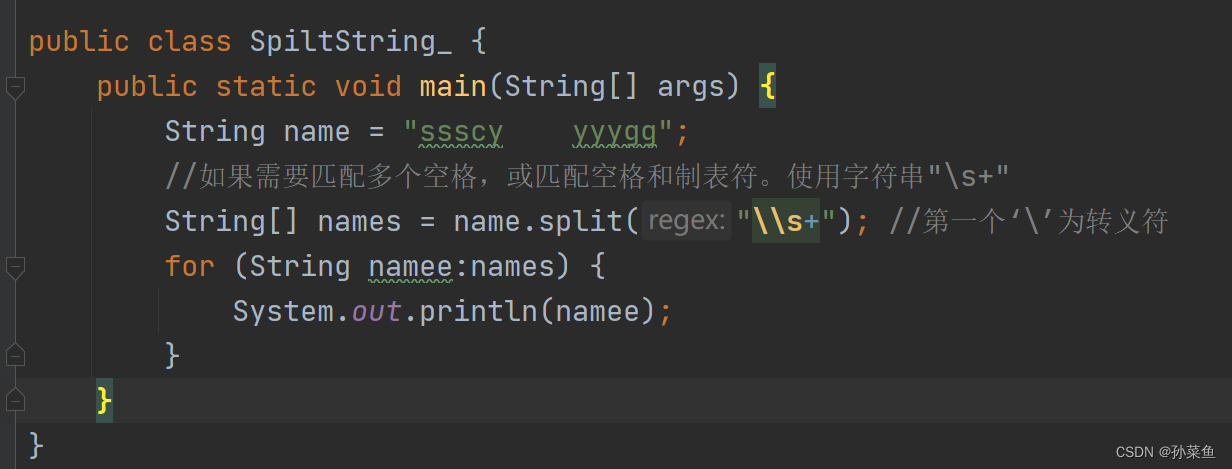
3. Scanner的分隔符处理机制
3.1 分隔符的概念和设置
3.1.1 Scanner默认分隔符的行为
在处理输入流时,分隔符扮演了非常关键的角色。默认情况下,Java的Scanner类使用空白字符作为分隔符,这意味着它将连续的非分隔符序列识别为单独的令牌。然而,不同的应用场景要求对分隔符的定义进行调整。了解和掌握如何自定义分隔符是使用Scanner时的一个关键能力,它能极大地提高数据解析的灵活性和效率。
3.1.2 自定义分隔符的步骤和方法
要自定义Scanner类的分隔符,可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
销售额预测模型构建指南:618销售预测与库存管理策略
核辐射探测仪器安全设计指南:确保人员与环境安全的必要措施
跨团队协作的安全意识:人为风险的10大减少策略
【NEH算法与Java实战】:10个步骤掌握流水车间调度优化
数据质量管理实战:CP与CPK在实际中的6种应用技巧
【架构师必备】:掌握挂售转卖商城的五大技术框架
MATLAB回声消除:从理论到实践的完美转变
winsecs_.net深度解析:掌握核心框架与安全机制
【AIDL常见问题与解决方案】:深入分析与应对策略
【电源革命:SC8815方案揭秘】:掌握双向65W PD技术,打造高效充电系统


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















