




性能提升揭秘:Java Scanner类的10个优化技巧


Java Scanner类及其方法使用图解
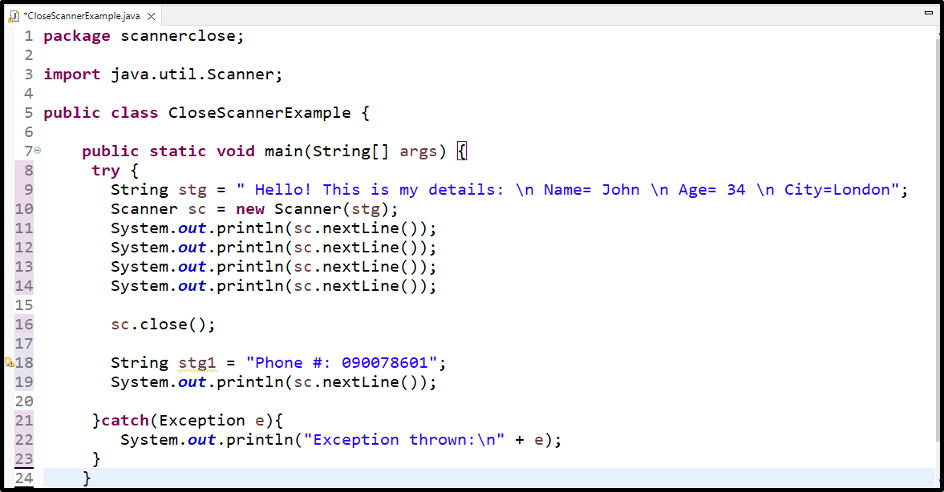
1. Java Scanner类基础介绍
Java中的Scanner类是JDK标准库提供的一个用于解析原始类型和字符串的简单文本扫描器。它可以通过定义的分隔符,将输入的字符串分割成多个标记(tokens),从而允许开发者轻松地读取数据。
在Java程序中,Scanner通常用于处理标准输入输出流(System.in)、文件(FileReader)、字符串(String)等。它支持多种数据类型,如整数、浮点数、字符串等。
尽管Scanner提供了灵活的接口和简单易用的API,但它的性能并不总是最优。特别是在处理大量数据或需要高效解析的应用场景中,它的局限性就会变得明显。但在本章中,我们将专注于它基础的使用方法和构造。
下面是一个简单的例子,演示如何使用Scanner类从标准输入读取一行文本:
- import java.util.Scanner;
- public class ScannerExample {
- public static void main(String[] args) {
- Scanner scanner = new Scanner(System.in); // 创建Scanner实例
- System.out.println("请输入一些文本:");
- if (scanner.hasNextLine()) {
- String inputLine = scanner.nextLine(); // 读取一行文本
- System.out.println("您输入的文本是: " + inputLine);
- }
- scanner.close(); // 关闭Scanner实例
- }
- }
这段代码创建了一个Scanner对象,用来读取用户的输入。通过hasNextLine()方法检查是否还有更多行输入,然后使用nextLine()读取一行文本。最终,我们关闭了Scanner以释放相关资源。
2. ```
第二章:深入理解Scanner类的性能瓶颈
扫描器类Scanner是Java的实用程序类,它用于解析基本类型的输入。尽管Scanner易于使用,但在需要处理大量输入或需要高性能时,它可能会显示出性能瓶颈。本章将深入探讨Scanner类的工作原理,揭示其性能瓶颈,并分析影响性能的环境因素。
2.1 Scanner类的工作原理
在深入性能问题之前,了解Scanner类的基础和它的工作机制是必要的。Scanner类使用Token分析机制将输入分解为多个Token,并根据默认解析策略进行解析。
2.1.1 Token分析机制
Scanner在解析输入时,首先要进行Token分析。Token是输入中可以被解释为程序语言的一个元素,如整数、浮点数、字符串、特殊字符等。Token分析器读取输入流,并根据预定义的规则将字符序列分割成Token。例如,输入"123 abc"会被Scanner分解为两个Token:一个整数Token(123)和一个标识符Token(abc)。
Token分析的内部机制
Scanner在内部使用了一个名为Scanner.Token的内部类来表示Token,并使用一个名为Scanner.ScannerImpl的实现类来执行实际的Token分析。这个实现类会逐步读取输入流,检测到Token边界时,如空格、标点符号或换行符,便生成相应的Token对象。
为了更好地理解Scanner的Token分析机制,下面是一个简单的代码示例和其逻辑分析:
- Scanner scanner = new Scanner("123 abc");
- if (scanner.hasNextInt()) {
- int i = scanner.nextInt();
- }
上述代码片段首先创建了一个Scanner对象,并将其初始化为处理字符串"123 abc"。hasNextInt()方法检查下一个Token是否为整数,是的话就返回true。如果返回true,则可以安全地调用nextInt()方法来读取该整数。
2.1.2 默认解析策略的影响
Scanner类的默认解析策略对于一些简单任务来说非常方便,但是对于复杂的解析需求或者对性能要求较高的场合,其默认行为可能会成为瓶颈。默认解析策略包含了对各种不同数据类型的支持,这意味着Scanner在解析输入时会尝试识别多种类型的数据。
默认解析策略的问题
默认解析策略的问题在于它会尝试将所有可能的数据类型都解析出来。如果输入中包含数字后紧跟一个字母,Scanner可能会误判为一个长整数。此外,由于Scanner使用了正则表达式来识别Token,如果输入流较大,这个过程可能会造成显著的性能负担。
避免默认解析策略问题的方法
为了避免这种问题,如果只关心特定类型的数据,可以使用重载的hasNext()方法和对应的next()方法,如hasNextInt()和nextInt(),从而减少不必要的解析尝试。例如,下面的代码片段只解析整数:
- Scanner scanner = new Scanner("123 abc");
- while (scanner.hasNextInt()) {
- int i = scanner.nextInt();
- // 处理整数
- }
2.2 标准输入输出的性能分析
在性能分析方面,Scanner类与BufferedReader等其他标准输入处理类进行了比较,以揭示性能差异。此外,还考虑了不同环境因素对Scanner性能的影响。
2.2.1 基准测试:Scanner与BufferedReader对比
基准测试是评估代码性能的一种有效手段。下面展示了如何比较Scanner和BufferedReader在读取大量文本时的性能。
基准测试设计
首先创建一个包含大量文本的文件。然后分别使用Scanner和BufferedReader类读取这个文件,记录读取时间。代码示例如下:
- // 使用Scanner读取
- Scanner scanner = new Scanner(new File("largeFile.txt"));
- long startTimeScanner = System.nanoTime();
- while (scanner.hasNextLine()) {
- scanner.nextLine();
- }
- long endTimeScanner = System.nanoTime();
- // 使用BufferedReader读取
- BufferedReader reader = new BufferedReader(new FileReader("largeFile.txt"));
- long startTimeReader = System.nanoTime();
- String line;
- while ((line = reader.readLine()) != null) {
- // 处理每一行
- }
- long endTimeReader = System.nanoTime();
性能分析结果
通常,BufferedReader在处理大量文本时性能优于Scanner。这是因为BufferedReader设计为快速读取文本,而Scanner则提供了更多解析功能,增加了额外的开销。
2.2.2 影响Scanner性能的环境因素
环境因素包括JVM版本、操作系统、硬件资源等,这些都可能对Scanner的性能产生影响。
JVM优化和垃圾回收机制
JVM的优化和垃圾回收机制对性能有很大影响。例如,对于长时间运行的程序,频繁地实例化Scanner对象可能会导致显著的垃圾回收开销。为了避免这种情况,可以考虑重用一个Scanner实例。
系统资源与多线程
系统资源,如CPU和内存,以及多线程环境也会影响Scanner的性能。多线程编程中,多个线程可能会同时访问同一个Scanner实例,导致竞态条件。为了避免竞态条件,可以考虑使用线程安全的 Scanner包装器或使用ThreadLocal<Scanner>。
总结
本章节深入探讨了Scanner类的工作原理、性能瓶颈,以及标准输入输出的性能分析。通过了解Scanner的Token分析机制和默认解析策略的影响,以及其在基准测试中的表现,我们能够更好地理解Scanner在性能方面的局限性,并在实际应用中作出更明智的选择。

在上述代码中,我们使用hasNext(Pattern)方法代替了hasNextInt()。这种方式允许我们使用正则表达式来匹配整数,这比Scanner默认的解析策略更加灵活和高效。通过正则表达式,我们可以预先过滤掉非整数字符串,减少 Scanner 在解析过程中可能遇到的异常和回溯,从而提高整体性能。
3.1.2 字符串与正则表达式匹配的改进
对于字符串的解析,我们可以采用预编译正则表达式的方式提高性能。这是因为正则表达式的编译是一个耗时的过程,如果每次都动态编译,会增加处理时间。预编译可以将这部分时间分摊到程序的运行过程中,减少单次调用的成本。以下是一个使用预编译正则表达式的例子:
- import java.util.Scanner;
- import java.util.regex.Pattern;
- public class RegexPrecompilation {
- private static final Pattern numberPattern = ***pile("\\d+");
- public static void main(String[] args) {
- String input = "123abc456def789";
- Scanner scanner = new Scanner(input);
- while (scanner.hasNext(numberPattern)) {
- System.out.println("Matched number: " + scanner.next(numberPattern));
- }
- scanner.close();
- }
- }
在这里,numberPattern是预编译过的正则表达式。通过使用预编译的正则表达式,我们可以更快地匹配和解析字符串。这种优化方式特别适用于需要频繁进行模式匹配的场景。
3.2 避免不必要的资源消耗
3.2.1 使用合适的数据结构减少内存占用
在解析大量数据时,内存使用会成为问题。为了避免大量的内存占用,我们可以选择使用合适的数据结构来存储解析后的数据。例如,如果我们知道即将处理的数据只包含小整数,那么使用byte或short类型的数组可能会比使用int数组更节省内存。此外,我们也可以考虑使用避免自动装箱的原始数据类型。
3.2.2 避免频繁的实例化和垃圾回收
频繁创建Scanner实例会导致大量的对象实例化,从而触发垃圾回收器频繁工作,影响性能。一种有效的策略是重用单个Scanner实例。如果数据源是连续的,我们可以通过设置分隔符或缓冲区来实现。以下是一个示例:
在这个示例中,我们设置了分隔符为逗号,从而不需要为每一条记录创建一个新的Scanner实例。这样可以显著减少实例化操作,避免频繁的垃圾回收,提高整体性能。
3.3 并发环境下Scanner的使用策略
3.3.1 多线程中Scanner实例的安全共享
在多线程环境中使用Scanner时,我们需要确保多个线程可以安全地共享同一个Scanner实例。一种方法是使用同步关键字,确保在任何时刻只有一个线程可以调用Scanner的方法。另一种方法是使用线程局部变量,这将在下一节详细讨论。
3.3.2 利用线程局部变量优化性能
线程局部变量(Thread Local)可以确保每个线程拥有Scanner的一个独立实例。这样,不同的线程就不会竞争同一个实例,从而避免了锁竞争和同步开销。以下是一个使用线程局部变量的例子:
在这个例子中,每个线程通过threadLocalScanner获取独立的Scanner实例。这样做可以保证多线程环境中Scanner的线程安全使用,同时避免了不必要的锁竞争。
在本章节中,我们深入了解了Scanner类的优化技巧,从数据解析优化到避免资源消耗,再到并发环境下的使用策略。这些技巧将有助于我们在实际应用中更好地利用Scanner类,提升程序的性能。在下一章节中,我们将通过实际案例来展示如何将这些优化技巧付诸实践。
4. Scanner类优化实践案例分析
4.1 大规模数据处理的优化方案
在处理大规模数据时,Java程序经常遇到性能瓶颈。使用Scanner类时尤其如此,由于其内部解析机制的局限性,当面对大量数据的解析时,性能问题尤为突出。在这一部分,我们将探讨优化方案,这些方案能够帮助我们处理大型数据集,同时提升性能。
4.1.1 分批读取与缓冲处理
传统的 Scanner 类在处理大规模数据时容易遇到性能问题。一个常见的优化方法是使用分批读取和缓冲处理。通过这种方式,我们可以减少内存的消耗,并改善数据处理的效率。
这段代码展示了一个简单的分批读取和缓冲处理的实现。程序使用ReadableByteChannel从数据源中读取数据,并将其分批处理。每当缓冲区被填满时,它会通过Scanner进行解析,然后处理完缓冲区内的数据后清空缓冲区,为下一批数据做准备。
4.1.2 与流处理框架的整合使用
在处理大数据集时,流式处理框架(如Java 8的Streams API)能够提供更好的性能和易用性。将Scanner与流处理框架结合使用能够进一步优化大规模数据的处理。
这个例子演示了如何将Scanner与IntStream结合,通过循环读取数据并进行流式处理。这种方式使我们能够利用Scanner的灵活性来解析数据,同时利用流处理框架的高级功能,如并行处理和延迟计算。
4.2 自定义Scanner类的实现
当标准库提供的Scanner类不再满足性能或功能需求时,开发一个自定义的Scanner类是必要的。通过重构Scanner来支持更高效的解析,我们可以根据实际需求定制解析逻辑,甚至使用动态代理和反射来进一步提升性能。
4.2.1 重构Scanner以支持更高效的解析
重构Scanner的一个关键点是优化其解析逻辑。标准的Scanner类在某些情况下会进行不必要的解析,而自定义的Scanner类可以去掉这些多余的步骤,专注于我们需要的解析。
在上面的代码中,自定义的CustomScanner类使用BufferedReader进行高效的数据读取,并对每一行使用Pattern匹配。我们可以根据需要添加多个模式,并在读取每一行时进行匹配,从而达到更高的性能。
4.2.2 动态代理和反射在优化中的应用
为了提高灵活性,我们可以利用Java的动态代理和反射机制来进一步优化自定义的Scanner类。通过这些高级特性,我们可以在运行时动态地处理不同的解析需求,而无需编写大量的样板代码。
这段代码创建了一个动态代理类DynamicScannerProxy,该代理类在调用方法之前可以执行自定义的逻辑,如添加性能监控和日志记录等。这对于需要高度可定制化和可扩展性的场景非常有用。
通过以上案例分析,我们可以看到,尽管Java的Scanner类在处理标准输入输出时具有简便性,但在面对大规模数据和特殊解析需求时,其性能和灵活性存在限制。通过分批读取、缓冲处理、流式处理整合以及自定义实现等优化方案,我们可以显著提升数据处理的性能。同时,借助动态代理和反射等高级特性,我们可以在不牺牲代码可维护性的前提下,获得更高的灵活性和扩展性。
5. 扩展阅读与未来展望
随着技术的发展,Java I/O生态系统也在不断进步和变革。程序员需要关注这些变化,以便于更高效地处理数据流和文件操作。本章将对替代Scanner的高级类库进行探讨,并展望Java I/O生态系统未来的发展方向。
5.1 探索替代Scanner的高级类库
5.1.1 使用正则表达式类库处理复杂模式
在处理文本数据时,正则表达式是一种强大的工具。它们可以帮助我们以极其灵活的方式匹配字符串模式。Java中内置了java.util.regex包,提供了强大的正则表达式处理功能。
- import java.util.regex.Matcher;
- import java.util.regex.Pattern;
- public class RegexExample {
- public static void main(String[] args) {
- Pattern pattern = ***pile("正则表达式字符串");
- Matcher matcher = pattern.matcher("待匹配的字符串");
- if (matcher.find()) {
- System.out.println("匹配成功!");
- }
- }
- }
正则表达式类库适用于复杂的模式匹配,但需要注意的是,正则表达式可能会非常消耗性能,尤其是当模式非常复杂或者输入数据量很大时。
5.1.2 高级解析库对比:StAX, SAX, 和DOM解析器
XML是另一种常见的数据格式。在Java中解析XML数据时,通常会使用StAX, SAX, 或者DOM这三种解析器中的一种。
-
StAX(Streaming API for XML)提供了一种基于游标的方法来处理XML流,是基于事件的解析方式,适合大型文档。
-
SAX(Simple API for XML)同样基于事件,但它是一个顺序解析器,无法修改文档,也难以向前或向后导航。
-
DOM(Document Object Model)解析器会将整个XML文档加载到内存中,构建一个树形结构,适合小型文档,但可能会消耗较多的内存。
每种解析器都有其适用场景,开发者应根据实际需要选择合适的解析器。
5.2 Java I/O生态系统的发展趋势
5.2.1 Java 9及以上版本的模块化I/O改进
Java 9 引入了模块系统,对 I/O 库也进行了一系列改进。例如,引入了新的流 API (java.util.stream),支持并行处理和更强的函数式编程能力。同时,Files 类也得到了增强,增加了许多实用的方法,例如 Files.readAllLines 和 Files.write。
- import java.nio.file.Files;
- import java.nio.file.Paths;
- import java.util.List;
- public class FileIOExample {
- public static void main(String[] args) throws Exception {
- List<String> lines = Files.readAllLines(Paths.get("文件路径"));
- for(String line : lines) {
- System.out.println(line);
- }
- }
- }
5.2.2 对性能和易用性改进的期待
随着Java版本的更新,对性能和易用性的改进始终是开发者社区的重要期待。未来可能会出现更多的改进,包括但不限于:
- I/O操作的异步API支持,减少线程阻塞。
- 更高效的内存管理机制,降低大文件处理时的内存消耗。
- 更简单的API设计,减少开发者实现复杂I/O操作的门槛。
Java I/O生态系统在未来的发展中,仍将继续以提供更高效、更简洁的解决方案为目标。对于广大开发者而言,紧跟这些变化,并且适当地应用到实际开发中,将有助于提升开发效率和系统性能。
在本章的结尾,我们对替代Scanner的高级类库和Java I/O生态的未来趋势进行了探讨。这不仅能帮助我们更好地理解目前可用的工具,同时也为未来可能遇到的技术挑战做好了准备。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【光缆故障不再怕】:检测与应对技术策略
虚拟化与云服务:华三模板在数据中心的革新应用
Helix QAC高级功能宝典:提升生产力的十大技巧
内网环境Kubernetes CI_CD实现:一步到位的自动化部署秘籍
【Copula模型高级教程】:MATLAB实战演练与优化算法
DVE自动化脚本编写:提高工作效率:自动化脚本编写与管理实战
【ES7243芯片温度管理手册】:3个环境因素保障ADC语音设备性能稳定
【优化数据精修过程】:Fullprof参数设置的权威指南
【信令监控实战】:TDD-LTE工具使用与故障排除技巧
【服务网格技术在12306的应用】:微服务架构下的网络挑战与解决方案


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















