【数值解析新手指南】:常微分方程的稳定性和全局优化方法
发布时间: 2025-01-05 21:12:29 阅读量: 17 订阅数: 9 

数值方法求解常微分方程_数值方法解常微分方程_
# 摘要
本文系统地介绍了常微分方程的基础理论和数值解析的基本原理,同时着重讨论了稳定性的概念及其对数值解析的影响。文章阐述了数值解析方法的分类和误差控制策略,并通过案例分析了常微分方程稳定性分析与全局优化方法的实际应用。此外,本文提供了关于数值解析软件工具和库的详细介绍,并展示了如何在多学科中进行应用。最后,文章展望了数值解析和全局优化的未来发展趋势,包括新兴数值解析方法和理论挑战,以及全局优化的新算法和应用前景。
# 关键字
常微分方程;数值解析;稳定性分析;全局优化;误差控制;软件工具
参考资源链接:[Maple求解常微分方程解析解与验证](https://wenku.csdn.net/doc/2iocu8z7tf?spm=1055.2635.3001.10343)
# 1. 常微分方程的基础理论
在这一章中,我们将探索常微分方程(ODEs)的基础知识,这是理解和掌握数值解析的起点。我们将从微分方程的基本概念入手,解释它们在描述物理世界变化中的作用。常微分方程作为数学领域的一个核心组成部分,为物理、工程、金融和其他科学领域提供了建模的工具。
## 1.1 微分方程的定义和分类
微分方程是一类包含未知函数及其导数的方程。具体地,常微分方程涉及的是一个或多个自变量的一阶或高阶导数。根据方程的阶数和线性特性,微分方程被分类为一阶线性、高阶线性以及非线性等类型。理解这些分类有助于我们选择合适的解析方法。
## 1.2 初值问题和边界值问题
在实际应用中,微分方程常常配合初始条件或边界条件来求解。初值问题(IVP)通常涉及的是在某一初始时刻给定的函数值及其导数,而边界值问题(BVP)则是在自变量的两个或多个点上给定条件。这两类问题的求解策略存在显著差异,它们分别对应于不同的实际情境。理解这些基础概念,将为后面章节中更高级的数值解析方法打下坚实的基础。
# 2. 数值解析的基本原理
### 2.1 稳定性的概念和重要性
#### 2.1.1 稳定性的定义
在数值解析领域,稳定性是一个至关重要的概念。它通常指的是当对一个数学模型进行数值求解时,由于近似和误差的累积,所得到的数值解是否能在长时间内保持其准确性,不会因计算过程中的小扰动而发生剧烈变化。更具体地,对于一个数值解析方法而言,如果它的数值解在足够小的误差范围内保持了与精确解的一致性,那么这个方法就被认为是稳定的。
稳定性通常分为两类:绝对稳定和条件稳定。绝对稳定是指无论初始条件如何,数值解都能够保持其稳定性;而条件稳定则是指只有当初始条件满足某些特定条件时,数值解才表现出稳定性。在实际应用中,由于条件稳定的限制,我们通常会偏好使用绝对稳定的数值解析方法。
#### 2.1.2 稳定性对数值解析的影响
稳定性对数值解析的影响是深远的,它直接关系到我们能否得到可靠的数值解。如果一个数值解析方法不够稳定,那么即使是很小的误差也可能导致最终解的显著偏差。这种现象在工程领域中尤为关键,因为错误的数值解可能会导致物理设备的损坏或安全事故。
例如,在天气预测模型中,如果不稳定的方法被使用,那么预测结果可能会因为初始条件的微小误差而迅速发散,导致天气预报完全失效。因此,研究者们在设计数值方法时,通常会非常重视稳定性的考量,并在实际应用中采取各种措施来确保数值解析过程的稳定性。
### 2.2 数值解析方法概述
#### 2.2.1 显式和隐式方法的比较
在数值解析中,方法可以被分为显式和隐式两大类。显式方法的特点是每一步的数值解都直接依赖于前一步的解,而隐式方法则需要解一个包含当前步数值的方程。
显式方法的优点在于它的实现相对简单,计算速度快,因为它不需要解决额外的方程。然而,显式方法有一个致命的缺点——它通常只在时间步长足够小的情况下才是稳定的,这限制了它在需要较大步长时的应用。一个典型的例子是显式欧拉方法。
隐式方法则相反,它允许使用较大的时间步长,因为它具有内在的稳定性。但是,隐式方法的缺点是每一步都需要求解一个方程,这通常需要更复杂的迭代方法,如牛顿法或不动点迭代,导致计算成本较高。
#### 2.2.2 初始值问题与边界值问题的解析策略
初始值问题(IVP)和边界值问题(BVP)是两种常见的常微分方程问题。数值解析时,这两种问题通常需要不同的策略。
初始值问题需要给定一个初始条件,并通过这个条件来推算未来的行为。显式和隐式方法在解决IVP中都扮演了重要的角色,具体选择取决于对稳定性和计算效率的权衡。
边界值问题需要在两个或多个边界上给定条件,并要求解出区间内的函数形式。解决BVP通常需要特殊的技巧,如有限差分法、谱方法或有限元法等。这些问题往往需要数值方法能够同时满足边界条件和微分方程,因此可能需要更复杂的设置和计算步骤。
### 2.3 误差分析与控制
#### 2.3.1 数值误差的来源
数值解析过程中的误差来源主要包括舍入误差和截断误差。舍入误差是指由于计算机中的数字表示有限制,无法精确表示实数,因此在运算过程中会产生误差。截断误差则是由于我们将一个连续的问题离散化,用近似的方法来代替精确的数学操作产生的。
舍入误差通常是不可避免的,但可以通过选择合适的数值解析方法、增加计算精度或采用适当的舍入策略来控制。例如,使用双精度浮点数而不是单精度浮点数能够减小舍入误差的影响。
截断误差的控制则取决于我们选择的数值方法和步长的大小。一般来说,步长越小,截断误差越小,但相应的计算量也会增大。因此,找到合适的步长是减少截断误差的关键。
#### 2.3.2 提高数值解析精度的方法
为了提高数值解析的精度,我们可以采取多种策略。首先,选择合适的数值解析方法至关重要。在某些情况下,多步方法如亚当斯-巴什福斯方法比单步方法更适合,因为它考虑了更多的历史信息,从而减少了截断误差。
其次,步长的控制也是一个重要的因素。自适应步长方法可以根据问题的局部行为动态调整步长,这样可以在需要的地方采用较小的步长以提高精度,在变化平缓的地方采用较大的步长以节省计算资源。
另外,差分格式的选择也会影响最终的精度。例如,使用中心差分代替前向或后向差分通常可以减少截断误差。
最后,多重网格法和谱方法等高级技术也可以用来提高数值解析的精度。这些方法通过在不同的尺度上进行计算,能够更精确地捕捉问题的本质特征。
为了进一步说明这一点,考虑如下Python代码块,它展示了一个简单的数值解析过程,通过使用`scipy.integrate.solve_ivp`函数来解决一个初始值问题,并且对步长和数值方法进行控制。
```python
import numpy as np
from scipy.integrate import solve_ivp
# 定义微分方程
def ode_system(t, y):
return -y
# 初始条件
y0 = 1
# 时间区间
t_span = [0, 2]
t_eval = np.linspace(t_span[0], t_span[1], 20)
# 解决初始值问题
sol = solve_ivp(ode_system, t_span, y0, t_eval=t_eval)
# 输出结果
print(sol.t)
print(sol.y)
```
该代码段利用了`scipy`库中的`solve_ivp`方法,它提供了一个接口来解决IVP问题,并允许用户指定求解器、初始条件、时间区间等。在实际应用中,可以通过`atol`和`rtol`参数来控制求解过程中的绝对和相对误差容忍度,这有助于改善求解的精度。
# 3. 稳定性和全局优化方法的实践应用
## 3.1 常微分方程的稳定性分析
### 3.1.1 线性稳定性分析
线性稳定性分析是一种分析微分方程解的行为的方法,尤其是当解偏离平衡点时的情况。考虑一个常微分方程系统,其形式为:
\[ \frac{dx}{dt} = Ax \]
其中,\( A \) 是一个 \( n \times n \) 矩阵,\( x \) 是一个 \( n \) 维向量。假设系统处于平衡点 \( x = 0 \),线性稳定性分析通过计算矩阵 \( A \) 的特征值来判断平衡点的稳定性。
如果所有的特征值的实部都是负的,那么平衡点是稳定的。反之,如果至少有一个特征值的实部是正的,那么平衡点是不稳定的。特征值的实部决定了系统从初始扰动中恢复或偏离平衡点的速度。
### 3.1.2 非线性稳定性分析案例
非线性稳定性分析比线性情况要复杂得多。考虑非线性系统:
\[ \frac{dx}{dt} = f(x, \mu) \]
其中,\( f \) 是关于状态变量 \( x \) 和参数 \( \mu \) 的非线性函数。这类系统没有通用的解析稳定性准则,但可以使用如Lyapunov方法等理论工具来分析特定系统的稳定性。
以范德波尔方程 \( \ddot{x} - \mu (1 - x^2)\dot{x} + x = 0 \) 为例,其中 \( \mu > 0 \) 是控制参数。此方程描述了带阻尼的非线性振荡器。通过定义适当的Lyapunov函数,可以分析出在不同参数值下系统行为的稳定性。
## 3.2 全局优化策略
### 3.2.1 全局优化算法的选择与比较
全局优化算法旨在找到问题的全局最优解,尤其在存在多个局部最优解的情况下。常见的全局优化算法有遗传算法、模拟退火、粒子群优化和差分进化等。它们之间的选择主要取决于问题的特性和要求。
遗传算法通过模拟自然选择和遗传机制来寻找最优解,适合解决组合优化问题。模拟退火借鉴了固体退火的原理,通过模拟热力学系统的退火过程来避免陷入局部最优解。粒子群优化算法通过模拟鸟群觅食行为来优化问题,易于实现且收敛速度快。差分进化算法使用差分向量来驱动搜索过程,适合处理多模态和高维问题。
每种算法都有其优势和局限性,在实际应用中,可能需要对算法进行调整或者参数优化以达到最佳的优化效果。
### 3.2.2 实际问题中的全局优化应用
全局优化在工程、金融、物流等多个领域都有广泛的应用。以物流领域的车辆路径问题为例,需要设计一组路径以最小化总运输成本,同时满足货物配送和收货约束。该问题是一个典型的组合优化问题,具有多个局部最优解。
在这种情况下,可以使用遗传算法或者模拟退火算法来解决这个问题。遗传算法通过选择、交叉和变异操作来迭代寻找最优路径组合;模拟退火则通过逐渐减小“温度”参数来跳出局部最优解,逐渐接近全局最优解。
## 3.3 混合数值解析与优化技术
### 3.3.1 混合方法的理论基础
混合数值解析与优化技术结合了数值解析和全局优化算法的优点,以应对复杂的动态系统建模和优化问题。这类方法通常包括对模型进行初步的数值解析以获得系统行为的近似理解,然后应用全局优化算法在参数空间中搜索最优解。
混合方法的关键在于选择合适的数值解析方法以及优化算法,并决定两者的结合点。例如,在分析一个动态系统时,可以先使用欧拉方法或龙格-库塔方法对系统进行初步模拟,然后用遗传算法调整系统参数以最小化某个性能指标。
### 3.3.2 混合方法在复杂系统中的应用
在复杂系统中,混合方法可以用来处理模型参数的不确定性。例如,在气候模型中,可以利用混合方法来优化模型参数,以便更好地预测气候趋势和极端天气事件。
具体操作时,首先使用数值解析方法对气候模型进行模拟,并分析不同参数配置下的模拟结果。随后,运用全局优化算法(如差分进化)在参数空间中寻找能够最好地拟合实际观测数据的参数设置。这种方法不仅可以帮助科学家理解和预测气候系统的动态行为,还可以为政策制定提供科学依据。
### 3.3.3 混合方法的实际应用案例
以一个涉及多学科的案例来说明混合数值解析与优化技术的实际应用。考虑一个机械工程问题:设计一个用于提高汽车燃油效率的发动机冷却系统。此类问题需要综合热力学、流体力学和材料科学的知识。
首先,可以通过数值方法(如有限元分析)模拟冷却系统的工作过程和热量传递。然后,采用全局优化算法(如粒子群优化)来寻找最优的冷却液流速、管道直径以及其他关键设计参数,以达到最佳的冷却效果和能效比。
通过混合方法的应用,工程师可以在满足一系列约束条件(如成本、重量、尺寸等)的情况下,寻找到最佳设计解决方案。
# 4. 数值解析软件工具和库
## 4.1 数值解析软件介绍
### 4.1.1 MATLAB、Mathematica、Maple等软件对比
MATLAB、Mathematica、Maple是广泛用于数值解析、符号计算和可视化展示的三大软件。它们各有优势与适用场景,用户需要根据实际需求选择最适合的工具。
MATLAB以其强大的矩阵运算能力和丰富的工具箱在工程应用和学术研究中占据重要地位。它提供了大量的内置函数,适用于线性代数、信号处理、控制系统设计等领域。此外,MATLAB的Simulink模块可以用来进行动态系统和嵌入式系统的仿真。
Mathematica则是一款符号计算软件,其特点在于强大的符号处理能力,可以进行复杂的数学推导和变换。Mathematica的编程语言具有高度的表达能力,它集成了广泛的数学函数库,并且提供了高级的图形用户界面。
Maple的特色在于其强大的符号计算功能和图形化界面,它在教学和学术研究中尤为流行。Maple的编程环境与数学符号表达紧密集成,适合解决复杂的数学问题和进行数学实验。
### 4.1.2 选择合适的数值解析软件
选择合适的数值解析软件时,应考虑如下几个方面:
1. **应用领域**:不同软件在不同的领域内有各自的优势。例如,MATLAB在工程领域使用较多,Mathematica则在数学研究领域更受欢迎。
2. **功能需求**:根据需要解决的问题,选择功能覆盖全面的软件。例如,如果需要进行大规模矩阵计算,MATLAB将是更合适的选择。
3. **学习曲线**:软件的易用性和学习难度也是重要考量。有些软件具有更直观的界面和更友好的用户交互设计。
4. **社区和文档支持**:一个活跃的社区和丰富的文档可以帮助快速解决问题和学习新技术。
5. **成本**:软件购买、使用许可或订阅成本也是不可忽视的因素。对于预算有限的用户,开源软件可能更具吸引力。
## 4.2 编程实现数值解析
### 4.2.1 使用Python的SciPy库
Python是一种流行的编程语言,其简洁易读的语法使其成为科研工作者的首选语言。SciPy库是Python中用于科学计算的一个库,它提供了一系列用于数值计算和统计分析的功能。
```python
import numpy as np
from scipy.integrate import odeint
# 定义常微分方程组
def model(y, t):
dydt = np.zeros(2)
dydt[0] = y[1]
dydt[1] = -y[0]
return dydt
# 初始条件
y0 = [1.0, 0.0]
# 时间点
t = np.linspace(0, 20, 200)
# 求解
solution = odeint(model, y0, t)
import matplotlib.pyplot as plt
# 绘图
plt.plot(t, solution[:, 0], 'r', label='y(t)')
plt.legend(loc='best')
plt.xlabel('t')
plt.grid()
plt.show()
```
以上代码演示了使用SciPy的`odeint`函数求解一个简单的二阶线性微分方程组。代码块中的逻辑分析包括导入必要的模块、定义微分方程组、初始化条件、时间点设置、求解过程以及最后的绘图展示。该例子向用户展示了如何使用Python和SciPy库来实现数值解析过程。
### 4.2.2 使用C++的Eigen库
C++语言以其性能优势在科学计算领域有着广泛的应用。Eigen是一个高级C++库,它支持线性代数、矩阵和向量运算,常用于数值分析中。
```cpp
#include <iostream>
#include <Eigen/Dense>
using namespace Eigen;
using namespace std;
int main()
{
// 定义一个3x3的矩阵
Matrix3d m = Matrix3d::Random();
cout << "随机矩阵m是:" << endl << m << endl;
// 转置矩阵
cout << "m的转置是:" << endl << m.transpose() << endl;
// 计算行列式
cout << "m的行列式是:" << endl << m.determinant() << endl;
// 计算矩阵的逆
cout << "m的逆是:" << endl << m.inverse() << endl;
return 0;
}
```
这段代码展示了Eigen库的基础用法,包括矩阵创建、转置、计算行列式以及求矩阵的逆。通过这个简单的例子,可以了解到Eigen在处理线性代数运算中的便捷性。对于需要高性能计算的数值解析任务,Eigen库提供了一个出色的解决方案。
## 4.3 跨学科应用案例分析
### 4.3.1 物理学中的应用实例
在物理学研究中,数值解析方法常常用于解决复杂系统的动态演化问题,如模拟天体运动、粒子系统和流体动力学等。这里介绍一个简化的天体物理模拟案例。
```python
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import solve_ivp
# 天体物理模拟函数
def gravity(t, y):
# y为包含物体位置和速度的数组
G = 6.67430e-11 # 万有引力常数
masses = np.array([1.989e30, 5.972e24, 7.348e22, 1.081e24]) # 四个主要行星的质量
r = y.reshape(4, 3) # 每行代表一个行星的x,y,z位置
v = y.reshape(4, 3)[:, 3:] # 每行代表一个行星的x,y,z速度
rrel = r[:, np.newaxis, :] - r[np.newaxis, :, :] # 相对位置
dist = np.sqrt(np.sum(rrel**2, axis=2)) # 两两距离
rrel[dist == 0] = 0 # 排除自身距离为零的情况
acc = -G * np.einsum('ijk,ik->ij', rrel, masses) / dist**3 # 计算加速度
return v.flatten()
# 初始条件
y0 = np.array([ # 行星位置和速度,单位为米和米/秒
-1.49598023e+11, 0.0, 0.0, 0.0, -29783.0, 0.0, # 太阳
-1.08208215e+11, -5.66136782e+10, 0.0, 0.0, 102689.3234, 18433.1788, # 地球
# ... (其他行星的初始条件)
])
# 时间跨度
t_span = (0, 3.154e+7) # 模拟一年
# 解决
sol = solve_ivp(gravity, t_span, y0, rtol=1e-9, atol=1e-12, t_eval=np.linspace(*t_span, 365*100))
# 绘图
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in range(4):
ax.plot(sol.y[i*3], sol.y[i*3+1], sol.y[i*3+2], label=f'Planetary body {i+1}')
ax.legend()
plt.show()
```
该代码使用`scipy.integrate.solve_ivp`函数来模拟四个主要行星围绕太阳的运动。通过这个例子可以看出,数值解析不仅能够解决单一学科的问题,还能够促进跨学科研究的发展。
### 4.3.2 生物学中的应用实例
在生物学领域,数值解析同样有广泛的应用,例如用于模拟细胞生长、基因表达网络和流行病学模型等。以下是使用Lotka-Volterra方程模拟捕食者和猎物动态平衡关系的一个例子。
```python
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
# Lotka-Volterra方程组
def lotkavolterra(t, y):
alpha = 1.
beta = 0.1
gamma = 1.5
delta = 0.75
x, y = y
return [alpha*x - beta*x*y, -gamma*y + delta*x*y]
# 初始条件
y0 = [10, 5]
# 时间跨度
t_span = (0, 20)
# 求解方程
sol = solve_ivp(lotkavolterra, t_span, y0, t_eval=np.linspace(*t_span, 100))
# 绘图展示
plt.plot(sol.y[0], sol.y[1])
plt.xlabel('Prey')
plt.ylabel('Predator')
plt.title('Lotka-Volterra Model')
plt.show()
```
这个模型通过数值解析方法,可以对捕食者和猎物的数量随时间的变化进行可视化模拟,从而帮助生物学家研究种群的动态变化规律。
通过上述跨学科的应用案例,我们可以看到数值解析软件和库在实现复杂系统模型中起到了关键作用,同时它们在不同领域的研究中表现出巨大的灵活性和高效性。
# 5. 未来发展趋势和研究方向
## 5.1 新兴数值解析方法
### 5.1.1 多尺度方法与模型
在科学和工程领域中,多尺度模型已经成为了研究复杂系统的重要工具。多尺度方法允许在不同尺度上同时进行计算,从而能够更全面地理解系统的动力学行为。例如,在材料科学中,原子尺度上的模拟可以揭示材料的微观属性,而宏观尺度上的计算则可以反映整个结构的性能。传统的数值解析方法往往只适用于单一尺度问题,而新兴的多尺度方法正试图解决这些局限性。
多尺度方法通常涉及以下几个方面:
- **宏-微耦合**:通过宏-微耦合算法,可以在宏观尺度的计算中嵌入微观尺度的模拟。
- **异质模型**:在不同尺度上应用不同的物理模型,并确保模型间的无缝对接。
- **跨尺度数值方法**:例如有限元-分子动力学耦合(FE-MD)方法,以及格子玻尔兹曼方法(LBM)等。
这些方法的发展推动了从微纳级别到宏观级别的无缝集成,对于理解材料、流体动力学、生物系统等领域的复杂现象至关重要。
### 5.1.2 机器学习在数值解析中的应用
随着人工智能的快速发展,机器学习特别是深度学习技术已经开始对数值解析领域产生影响。机器学习模型能够从大量数据中提取特征并进行非线性拟合,这在处理传统数值方法难以应对的问题时显得尤为有用。
应用机器学习到数值解析中,主要体现在以下几个方面:
- **模式识别与预测**:例如使用神经网络来预测系统中的突发事件或不稳定行为。
- **数据驱动的建模**:利用机器学习从实验数据中提取模型参数,而不完全依赖于理论推导。
- **优化数值方案**:机器学习能够帮助自动选择最合适的数值解析方法和参数,以提高计算效率和精度。
机器学习的加入不仅提升了数值解析的能力,也预示着未来数值计算与人工智能融合发展的趋势。
## 5.2 数值解析的理论挑战
### 5.2.1 高维问题的解析难度
随着问题维度的增加,数值解析的难度呈指数级增长。高维问题不仅意味着需要更多的计算资源,还带来了所谓的“维度的诅咒”,其中数据稀疏性和计算精度问题尤为突出。例如,在计算流体动力学中,三维模型的解析比二维模型复杂得多。
解决高维问题的挑战,研究者们正在探索多种方法:
- **降维技术**:如主成分分析(PCA)、独立成分分析(ICA)等,这些技术可以减少问题的维数,简化模型。
- **稀疏表示**:开发适用于高维数据的稀疏表示和逼近方法。
- **随机方法**:利用蒙特卡洛模拟或随机过程等方法来处理不确定性。
### 5.2.2 非线性系统的全局行为预测
非线性系统是科学和工程中常见的复杂系统,其全局行为预测对于理解系统演化至关重要。非线性系统往往具有多个稳定和不稳定的解,这种复杂性使得预测系统未来的行为非常具有挑战性。
为了解决这个问题,研究者们正在:
- **发展新的解析技术**:比如正则化方法、摄动理论等,来分析非线性项的影响。
- **采用动力系统理论**:应用分叉理论和混沌理论来理解非线性系统中的关键因素和行为。
- **结合数据驱动方法**:使用机器学习技术,基于观测数据来识别非线性系统的关键特征和行为模式。
## 5.3 全局优化的前沿进展
### 5.3.1 复杂系统优化的新算法
复杂系统常常涉及大量变量和约束条件,全局优化这类问题往往难以求得精确解,因此,开发高效的优化算法显得尤为重要。当前,许多新算法和策略正在被提出来应对这些挑战。
一些具有前景的研究方向包括:
- **启发式与元启发式算法**:如蚁群算法、粒子群优化(PSO)等,这些算法能够在复杂的解空间中搜索最优解。
- **混合优化方法**:结合多种优化策略,利用各自的优点,以提高解决复杂问题的能力。
- **量子计算和量子优化算法**:利用量子计算的并行性和量子纠缠特性,对于某些优化问题展现出超越经典计算的潜力。
### 5.3.2 优化理论在大数据中的应用前景
大数据环境下,优化理论的应用前景变得十分广阔。数据的收集和处理,以及基于这些数据做出决策的需求,都需要高效的优化算法作为支撑。这些算法可以帮助我们从海量数据中提取有用信息,做出快速响应,并提高整体效率。
优化理论在大数据中的应用正在向以下方向发展:
- **大规模数据集优化**:研究如何在保持较高精度的前提下,处理数以亿计的数据点。
- **在线优化和实时决策**:适应数据动态变化,进行实时优化和决策。
- **隐私保护优化问题**:如何在保证数据隐私的同时,进行有效的优化计算。
在这些领域中,优化理论不仅需要与机器学习、网络理论等交叉学科结合,还需要考虑到计算的可行性和实时性问题。随着研究的深入和技术的成熟,我们可以期待优化理论在大数据时代中的更多创新应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以常微分方程为主题,提供全面的解析解方法。从理论基础到实践应用,涵盖18个必备技巧、数值解析、边界问题、奇异积分、Green函数、多尺度分析、变分法、误差分析等深入内容。专栏还介绍了mq135空气质量检测传感器的原理图,展示了常微分方程在实际应用中的重要性。通过深入浅出的讲解和丰富的案例分析,本专栏旨在帮助读者全面掌握常微分方程的解法,并将其应用于科学、工程和数据分析等领域。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB高效求解非线性规划:专家揭秘实用工具箱及实例分析
# 摘要
本文详细介绍了非线性规划问题的数学基础,并通过MATLAB非线性规划工具箱的介绍和使用指南,提供了非线性规划问题求解的实践方法。首先,概述了非线性规划的基本概念和MATLAB工具箱的安装与配置。其次,深入讨论了工具箱的主要功能、命令以及高级定制选项。在实践指南部分,通过单变量、多变量和带有约束条件的非线性规划实例,展示了MATLAB在解决这些问题时的具体实现和结果分析。进阶应用章节探讨了多目标优化、全局优化问题求解,以及非线性规划在实际工程和经济问题中的应用。最后,章节五展望了深度学习与非线性规划结合的前景,以及未来的发展方向。本文旨在为工程设计优化和经济学模型提供有效的问题解决方法
前端开发技术栈:现代网页设计与优化的7大秘诀
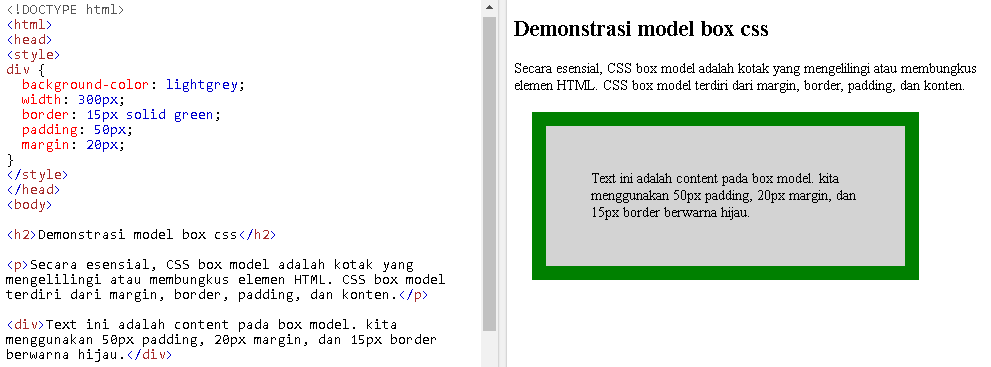
# 摘要
随着互联网技术的快速发展,现代网页设计对用户体验和开发效率的要求日益提升。本文围绕现代网页设计的核心理念、技术选型以及前端开发工具链与流程优化进行了全面探讨。通过分析前端工具链的进化、构建工具的应用、性能优化策略以及界面设计和用户体验的提升,本文揭示了如何利用CSS预处理器、响应式设计、交互设计等技术提高网页的可维护性和互动性。同时,深入实践章节涵盖了前端安全防护、服务器端渲染、静态站点生成以及前端测试与持续集成的
Java并发编程实战:2024年面试官最想问的10个问题
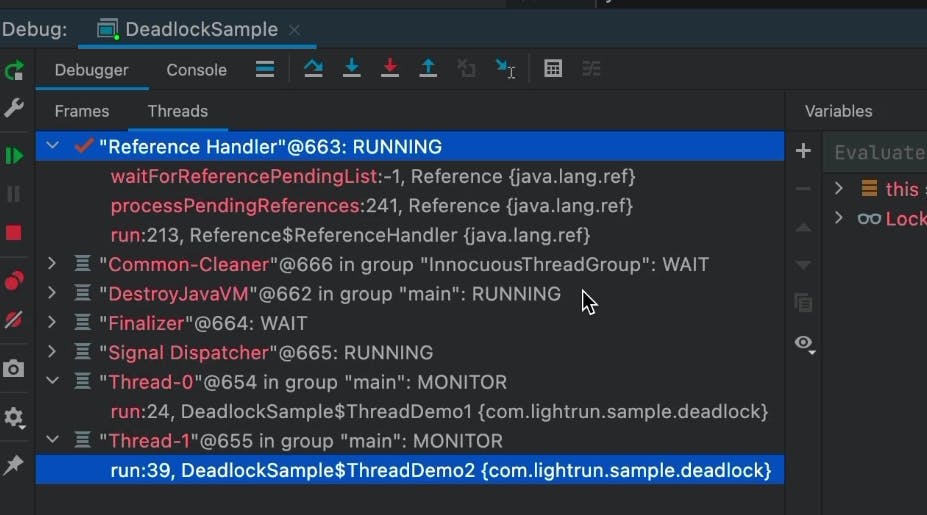
# 摘要
Java并发编程是提升应用性能与响应能力的关键技术之一。本文从核心概念出发,深入探讨了Java并发工具类的原理与应用,包括同步辅助类、并发集合、原子变量以及线程池的构建与管理。文章还提供了实践技巧,如线程安全的单例模式实现,死锁的预防与诊断,以及并发编程中常见的问题解决方法。此外,本文分析了并发
移动优先设计指南:打造完美响应式网站
# 摘要
随着移动设备的普及,移动优先设计成为构建现代Web应用的关键策略。本文系统地阐述了移动优先设计的概念和响应式网站设计的理论基础,包括媒体查询、弹性布局和响应式设计的三大支柱。文章深入探讨了实践中的响应式设计技巧,如布局、排版以及用户界面组件的响应式实现,并强调了性能优化与测试的重要性。此外,本文展望了移动优先设计的高级应用,包括集成前端框架、工具以及进阶
MELSEC iQ-F FX5编程提升:掌握5个高级编程技巧,实现FB篇的最优应用
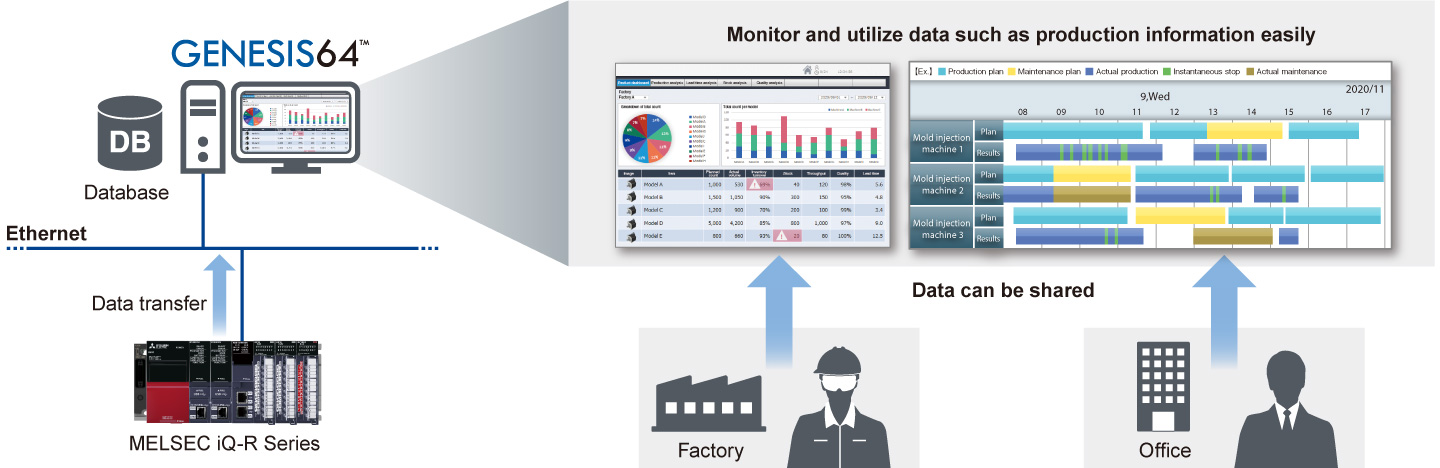
# 摘要
本文全面介绍了MELSEC iQ-F FX5系列PLC的基础知识、编程环境、语言概述以及高级编程技巧,旨在帮助工程师深入掌握并高效运用该系列PLC。从基础配置到编程结构、从指令集到数据类型,文章详细阐述了该系列PLC的关键技术要素。同时,通过对功能块的复用、间接寻址技术、数据处理、中断和异常处理、以及通信
【向量化计算简化术】:NumPy广播机制的高效应用
# 摘要
NumPy是Python中用于科学计算的核心库,它提供了高性能的多维数组对象和一系列操作这些数组的工具。本文首先介绍了NumPy的基本概念、安装方法以及数组的基础使用,包括数据类型的选择、数组的创建、索引、形状改变、合并分割等。接着深入探讨了NumPy的广播机制,包括广播的规则、高级应用及性能影响。文章最后聚焦于NumPy在实际数据分析、科学计算和机器学习模型中的应用,以及与其他流行库如Pand
【音麦脚本性能提升】:10个高效策略助你优化脚本运行效率(专家建议)

# 摘要
音麦脚本性能优化是确保音频处理系统高效运行的关键环节。本文首先概述了音麦脚本性能优化的重要性,接着通过性能分析与诊断的方法,识别性能瓶颈,并介绍了性能评估的关键指标。文章进一步探讨了代码级和系统级的优化策略,包括高效算法的选择、循环与递归优化
【仿真从基础到高级】
# 摘要
仿真技术作为模拟复杂系统行为的关键工具,在工程、科学研究以及产品设计等领域扮演着至关重要的角色。本文首先概述了仿真技术的基本概念,并深入探讨了其理论基础,包括数学模型的分类与应用、系统动力学原理以及仿真验证与确认的原则和方法。随后,本文分析了仿真软件和工具的选择、应用和编程实践,以及仿真在工程应用中的具体案例和优化策略。最后,本文展望了高级仿真算法的发展趋势,包括与机器学习的融合及高性能计算的应用,并讨论了跨学科仿真面临的挑战及未来的方向。
# 关键字
仿真技术;数学模型;系统动力学;验证与确认;仿真软件;优化策略;跨学科研究
参考资源链接:[Surface Pro 6 黑苹果安
【故障诊断】:PDN直流压降实战技巧,专家分享
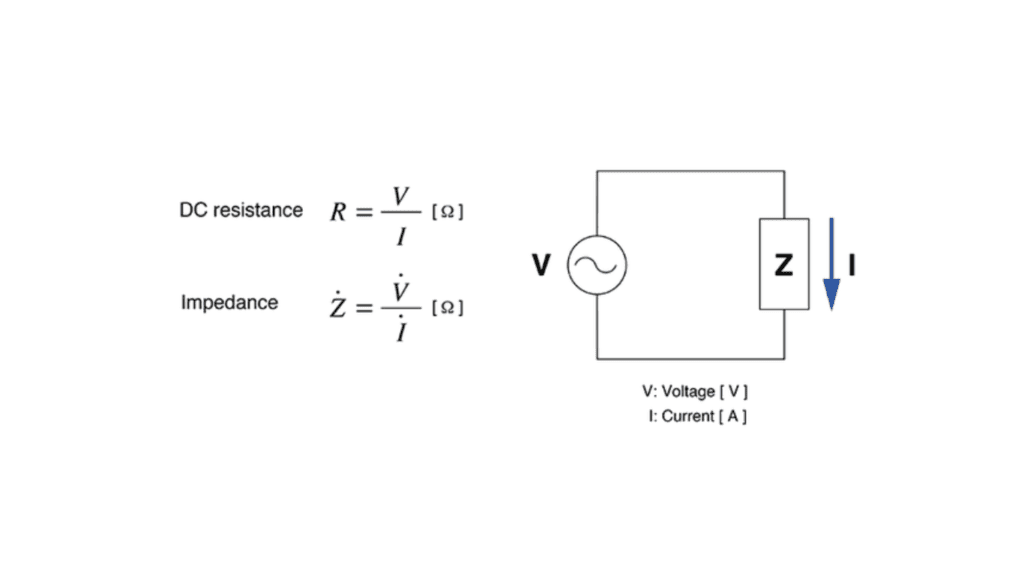
# 摘要
本文系统地介绍了电源分配网络(PDN)直流压降的基础知识、理论模型、计算方法和优化策略。首先阐述了PDN压降的基础理论,深入分析了影响压降的关键因素,随后探讨了压降的计算方法,包括电阻与阻抗的计算以及电流分布与压降的关系。文章接着详细描述了PDN设计中的压降优化策略,强调了减少电阻率和阻抗、布局优化的重要性。在PDN压降测试与分析工具章节中,介绍了多种测试工具和分析软件
ST7701S故障排除与维护策略:专家级解决方案

# 摘要
本文旨在为技术工作者提供一套全面的ST7701S故障排查与维护指南。首先介绍了ST7701S的基本故障排查流程和工作原理,包括硬件架构、软件架构及其常见故障的理论分析。其次,通过实际案例分析,详细阐述了故障诊断工具与方法、实战案例处理及维修与更换组件的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )