




【feedparser高级技巧】:定制解析与数据处理的高效方法


feedparser:用Python解析提要
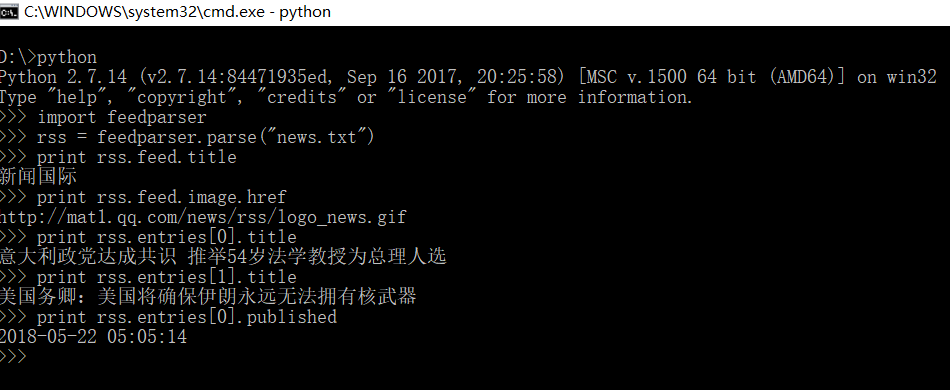
1. feedparser库简介与基础应用
feedparser库是Python中一个广泛使用的第三方库,它专门用于解析RSS和Atom feeds。这一库不仅能够帮助开发者读取和解析各种标准的XML格式数据流,而且极大地简化了将信息嵌入到Python应用程序中的流程。feedparser在数据抓取、网站内容聚合、定时更新提醒等众多场景下被广泛应用。
1.1 feedparser的安装与配置
首先,确保你安装了Python环境。接着,使用pip安装feedparser库:
- pip install feedparser
安装完成后,可以通过导入模块并解析一个RSS源来测试安装是否成功:
- import feedparser
- feed = feedparser.parse('***')
如果上述代码运行没有错误,并且可以看到RSS源的相关数据结构,那么feedparser库已经成功安装并配置完毕。
1.2 feedparser的基本使用方法
feedparser模块的parse()函数用于获取和解析网络上的RSS或Atom feed。该函数接收一个URL或者本地文件路径作为参数,并返回一个包含解析后数据的feed对象。以下是如何使用feedparser的基本步骤:
- import feedparser
- # 解析一个RSS源
- url = '***'
- feed = feedparser.parse(url)
- # 检查是否成功获取到数据
- if feed['bozo']:
- print('There was an error parsing the feed.')
- else:
- print(f'Feed title: {feed["feed"]["title"]}')
通过上述代码,我们可以获取到BBC新闻RSS源的标题,并判断解析过程是否出错。如果一切正常,将输出"Feed title: BBC News"。如果出现错误,则输出错误信息。
在下一章中,我们将深入探讨feedparser的工作机制,以及如何处理复杂的XML和RSS数据流。
2. ```
第二章:深入理解feedparser的工作机制
feedparser是一个流行的Python库,用于解析各种网络上内容的RSS和Atom源。在深入到如何优化feedparser性能以及处理异常之前,本章节将探讨feedparser的工作机制,包括其数据解析流程、高级配置选项以及如何拓展其用法。
2.1 feedparser的数据解析流程
2.1.1 XML和RSS解析基础
RSS(Really Simple Syndication)以及Atom是两种常用的网络内容分发格式,广泛用于新闻站点和博客的更新信息。它们都基于XML(eXtensible Markup Language)标准,提供了一种结构化的方式来表示数据。XML是一种标记语言,使用标签来描述数据,而RSS和Atom在此基础上提供了预定义的标签集合,用于描述诸如标题、链接、摘要、更新时间等信息。
feedparser库能够解析这些格式的数据,并将其转换为Python对象,以便于程序化的处理和使用。解析过程中,feedparser首先会检查源的HTTP头部信息,确定内容的类型,并且解析出相应的XML结构。
2.1.2 feedparser的解析模型
feedparser将解析过程封装为简单易用的接口。当给定一个RSS或Atom源时,feedparser会返回一个包含所有元数据和条目的feed对象。这个对象包括了源的标题、描述、链接、作者信息、每个条目的信息等。
feedparser处理XML的方式是逐行读取,并利用内部的XML解析器构建一个数据模型。这个模型是一个树状结构,包含了所有的feed和entry对象,它们又包含了各自的信息。这种处理方式使得feedparser在解析网络上大规模的XML数据时既高效又可靠。
2.2 feedparser的高级配置选项
2.2.1 自定义解析行为
尽管feedparser已经提供了一个非常方便使用的默认解析器,但有时开发者需要对解析行为进行自定义。例如,可能需要调整解析超时时间、处理特定的字符编码、或是添加额外的HTTP头部信息。
feedparser允许开发者通过参数来自定义解析行为。例如,可以设置feedparser.parse函数的request_timeout参数来指定超时时间。这样的高级配置允许开发者精确控制解析过程,以适应不同的应用场景。
2.2.2 处理异常和错误
feedparser在解析过程中,会遇到各种潜在的问题,比如网络请求失败、源文档损坏、或者缺少必要的信息。feedparser内置了异常处理机制,能够捕获并记录这些错误,并提供相应的错误信息。
了解如何处理这些异常和错误对于构建健壮的应用程序至关重要。例如,可以使用try-except语句捕获并处理feedparser.NonXMLContentType异常,这是当feedparser无法将源内容识别为XML或JSON时抛出的异常。
2.3 feedparser的扩展用法
2.3.1 插件机制的利用
feedparser支持插件机制,这意味着开发者可以编写自己的插件来扩展feedparser的功能。通过编写插件,可以添加新的解析器、转换器或修改现有的解析行为。
插件的编写通常涉及到对feedparser的解析过程进行拦截和修改。feedparser的事件驱动的插件架构允许开发者注册回调函数,在解析的不同阶段执行特定的代码。例如,可以在解析到每个entry时,通过插件来过滤和筛选出特定类型的条目。
2.3.2 feedparser与其他库的集成
除了可以自定义和扩展功能外,feedparser还能与其他Python库集成使用,以实现更加复杂的场景。一个常见的例子是与requests库集成,以处理SSL证书验证或者HTTP代理的需求。
集成其他库时,需要确保在调用feedparser.parse之前,已经配置了相应的网络请求设置。例如,使用requests库来设置HTTP头部信息或请求参数,然后将响应对象传递给feedparser进行解析。
在下一章节中,我们将探讨如何使用feedparser进行数据定制与提取,以及如何有效地利用正则表达式来优化数据处理流程。

以上代码展示了一个简单的函数extract_author,它尝试从一个feed中提取作者的名字。如果找不到相关信息,则返回"N/A"。这里的get方法用两个键名来安全地访问字典中的数据,这样做是为了防止在键不存在时引发异常。
3.1.2 数据清洗与转换方法
处理RSS或Atom源时,常常会遇到格式不一致的问题。feedparser允许我们对数据进行清洗和转换,以便统一格式和纠正错误。例如,日期字段经常以不同的格式出现,我们可能需要将其转换为统一的格式。
- from datetime import datetime
- def parse_date(date_string):
- # 尝试不同的日期格式
- for fmt in ("%a, %d %b %Y %H:%M:%S %z", "%Y-%m-%dT%H:%M:%S%z"):
- try:
- return datetime.strptime(date_string, fmt)
- except ValueError:
- continue
- raise ValueError("date format not recognized")
- # 假定我们有一个日期字符串
- date_str = d.feed.updated
- # 解析并打印日期
- print(parse_date(date_str))
这个parse_date函数尝试了多种可能的日期格式来解析一个日期字符串。它用到了异常处理来捕获ValueError异常,如果所有格式都不匹配,函数就会抛出异常。这确保了所有日期都以一种特定的格式输出。
3.2 feedparser的数据提取与排序
3.2.1 条件过滤与数据抽取
在处理大型feed时,可能只想获取符合特定条件的条目。feedparser允许我们通过指定条件对结果集进行过滤。
- # 假定我们只对过去一周内更新的条目感兴趣
- one_week_ago = datetime.utcnow() - timedelta(days=7)
- def filter_entries(feed, threshold):
- for entry in feed.entries:
- updated = datetime(*map(int, entry.updated.split('-')))
- if updated > threshold:
- print(entry.title)
- # 应用过滤器
- filter_entries(d, one_week_ago)
这段代码定义了一个filter_entries函数,它检查每个条目的更新日期,并只打印出在指定时间阈值之后更新的条目的标题。
3.2.2 排序和分页处理
feedparser允许我们对条目进行排序,并且可以轻松实现分页。这对于处理大量数据并希望以用户友好的方式呈现结果非常有用。
- def sort_and_page_entries(feed, page_size=10, page_number=1):
- entries = sorted(feed.entries, key=lambda e: e.published, reverse=True)
- start = (page_number - 1) * page_size
- end = start + page_size
- for entry in entries[start:end]:
- print(entry.title)
- # 获取并排序条目
- sorted_entries = sort_and_page_entries(d)
这段代码首先对条目按发布日期进行逆序排序,然后根据指定的页码和页面大小进行分页显示。这里sorted函数用于排序,而列表切片用于分页。
3.3 feedparser与正则表达式
3.3.1 正则表达式的应用实例
feedparser也支持使用正则表达式来解析和匹配数据。这在处理不规范的数据或需要提取特定模式的数据时非常有用。
- import re
- # 假定我们需要从描述中提取链接
- def extract_links(feed):
- links = []
- pattern = ***pile(r'https?://\S+')
- for entry in feed.entries:
- desc = entry.description
- matches = pattern.findall(desc)
- links.extend(matches)
- return set(links) # 使用set来去除重复的链接
- # 获取链接并打印
- links = extract_links(d)
- for link in links:
- print(link)
这段代码创建了一个正则表达式模式来匹配可能的URL,然后在每个条目的描述中搜索匹配项,并将找到的链接打印出来。
3.3.2 正则表达式在数据处理中的优势
正则表达式在数据清洗和提取过程中非常强大,尤其是在模式匹配和字符串处理方面。它们可以识别复杂的文本模式,并且非常灵活。不过,正则表达式也可能变得非常复杂且难以阅读,因此在实际应用中应谨慎使用。
3.3.3 正则表达式使用注意事项
尽管正则表达式功能强大,但在使用时还需要注意到以下几点:
- 正则表达式可能会非常复杂和难以调试。使用适当的工具来测试你的表达式以确保它们按预期工作。
- 性能问题:对于非常大的数据集,复杂的正则表达式可能会导致显著的性能问题。始终评估表达式的效率,并在必要时进行优化。
- 语言支持:feed中的文本可能包含各种特殊字符或编码,正则表达式需要正确处理这些情况。
表格展示
一个应用正则表达式后的feedparser提取结果示例表格如下:
| 文章链接 | 发布时间 | 作者 |
|---|---|---|
| []( |
- [](
在本节中,我们介绍了feedparser库中一些高级和定制的数据提取和处理技巧,包括字段定制、数据清洗、排序、分页处理以及如何利用正则表达式进行复杂的数据模式匹配。这些技巧为用户提供了强大的工具来处理和分析网络上的RSS或Atom订阅源。在下一章中,我们将深入探讨feedparser在实际应用案例中的具体运用,如新闻聚合、内容监控等场景。
4. feedparser实践案例分析
4.1 feedparser在新闻聚合中的应用
4.1.1 构建新闻聚合器的步骤
新闻聚合器是将来自不同来源的新闻内容整合到一个界面中,方便用户阅读最新新闻。使用feedparser可以非常简单地实现一个基本的新闻聚合器。构建新闻聚合器的步骤可以分为以下几个阶段:
-
需求分析:明确新闻聚合器需要支持的网站和新闻源,确定需要提取的新闻信息字段(如标题、摘要、发布日期、链接等)。
-
源数据收集:编写代码来解析目标网站的RSS或Atom feeds。可以使用feedparser库获取这些feed,并提取相关信息。
-
数据处理:对提取的数据进行清洗和格式化,以统一输出格式。
-
后端存储:将清洗后的数据存储在服务器数据库中,以备前端展示。
-
前端展示:开发用户界面,从后端数据库获取数据并展示给用户。
-
迭代优化:根据用户反馈对聚合器进行优化和功能拓展。
下面的代码示例展示如何使用feedparser来解析RSS feed并提取新闻信息:
这段代码首先导入feedparser模块,定义了一个解析feed的函数parse_feed,该函数接受一个URL作为参数。函数内部,使用feedparser.parse方法解析feed,并遍历解析结果中的每篇文章(feed.entries),分别提取出标题(title)、链接(link)、摘要(summary)和发布日期(published),然后打印出来。
4.1.2 案例解析:个性化新闻订阅系统
个性化新闻订阅系统允许用户根据自己的喜好订阅特定主题的新闻。这样的系统可以包含用户注册、订阅管理、内容聚合以及个性化推荐等功能。下面是构建一个简单的个性化新闻订阅系统的一些关键步骤:
-
用户注册与登录:提供用户注册和登录功能,为用户提供个性化的新闻订阅服务。
-
订阅主题选择:用户可以根据兴趣选择不同的新闻主题或关键词,系统根据这些信息为用户聚合新闻。
-
个性化推荐算法:根据用户的历史阅读习惯和订阅偏好,使用推荐算法为用户推荐新闻。
-
后台定时任务:定时从各个新闻源抓取最新的新闻内容,并及时更新到用户端。
-
前端新闻展示:根据用户偏好,将个性化新闻和推荐新闻展示给用户。
feedparser在这个系统中扮演的是将新闻内容从各个源聚合起来的角色。使用feedparser提取出需要的数据,然后存储在系统后端,前端再从后端获取数据并展示给用户。通过这样的架构,系统可以快速适应新的新闻源,且不需要为每个新闻源编写特定的抓取代码。
下面是整合feedparser与用户个性化设置的伪代码片段:
此伪代码展示了一个简化的个性化新闻聚合过程。在实际应用中,这将需要结合用户数据库和新闻源数据库,并进行相应的异常处理和数据验证。
5. feedparser的性能优化与错误处理
在实际应用中,性能优化和错误处理是确保feedparser库能够稳定、高效运行的关键因素。本章将详细探讨feedparser的性能优化策略,如何进行异常管理和调试,以及如何编写单元测试和维护feedparser库。
5.1 feedparser性能优化策略
性能优化通常涉及到内存和资源的合理使用,以及并发操作的高效处理。feedparser作为一个用于解析XML和RSS的Python库,其性能优化策略主要包括以下两个方面:
5.1.1 内存与资源管理
内存泄漏是导致程序性能下降的主要原因之一。feedparser提供了一些工具来帮助开发者监控和管理内存使用情况。例如,使用gc模块来跟踪对象的创建和回收情况,以及利用Python的调试工具(如objgraph)来检测内存中对象的占用情况。
- import gc
- import objgraph
- # 开始跟踪对象的创建和销毁
- gc.set_debug(gc.DEBUG_LEAK)
- # 进行一些feedparser的操作...
- # 检查是否存在未被回收的对象
- for obj in gc.garbage:
- print(objgraph.type_name(obj))
5.1.2 并发与多线程处理技巧
在处理大量数据或者需要快速响应的情况下,合理使用多线程或异步IO能够显著提高feedparser的性能。在Python中可以使用threading模块进行多线程操作,或者使用asyncio模块实现异步IO操作。
5.2 feedparser的异常管理与调试
异常管理是程序健壮性的核心部分,feedparser提供了丰富的异常类型来帮助开发者更好地理解和处理错误情况。
5.2.1 日志记录与错误追踪
良好的日志记录可以帮助开发者快速定位问题。feedparser库内部会记录一些关键的操作日志,但开发者也可以通过配置日志系统来获取更详细的调试信息。
- import logging
- import feedparser
- # 配置日志级别和格式
- logging.basicConfig(level=***, format='%(asctime)s - %(levelname)s - %(message)s')
- def process_feed(url):
- try:
- feed = feedparser.parse(url)
- # 处理feed...
- except feedparser.NonXMLContentType as e:
- logging.error(f"NonXMLContentType error for {url}: {e}")
- except Exception as e:
- logging.error(f"Unexpected error: {e}")
- process_feed('***')
5.2.2 异常处理的最佳实践
异常处理的最佳实践包括明确异常类型、记录详细错误信息以及提供有用的调试提示。此外,避免异常处理中的逻辑错误同样重要,例如不要捕获Exception类的通用异常,因为它可能会隐藏一些其他重要的错误。
- try:
- # 可能引发异常的代码
- except feedparser.NonXMLContentType as e:
- # 处理特定类型的异常
- print(f"Error: {e}")
- except feedparser.ParseError as e:
- # 处理解析错误
- print(f"Error: {e}")
- except Exception as e:
- # 只在没有其他选择时使用
- print(f"Unexpected error: {e}")
5.3 feedparser的测试与维护
编写单元测试并定期进行库的维护和升级是确保feedparser长期稳定运行的重要手段。
5.3.* 单元测试的编写方法
单元测试有助于确保每个独立代码段按预期工作。feedparser虽然是一个外部依赖库,但依然可以通过模拟(mocking)的方式来编写单元测试。
5.3.2 feedparser库的维护和升级策略
为了维持feedparser库的性能和安全性,定期更新和维护库是非常重要的。开发者应关注feedparser的官方发布日志,了解新版本中的变更和新特性。同时,适当的版本控制和回滚计划也应当准备妥当,以防新版本引入了兼容性问题或者新bug。
在升级feedparser之前,建议开发者在开发环境进行充分测试,并且确保所有的测试用例都已经通过。在生产环境中升级之前,最好先在预发环境进行部署和测试,以确保升级过程中的平滑过渡。
- pip install --upgrade feedparser
执行上述命令将帮助你升级到feedparser的最新版本。此外,维护工作还包括根据新的Python版本和第三方库的更新,定期更新代码以确保兼容性。
以上便是feedparser在性能优化和错误处理方面的详细讨论。通过这些策略的应用,可以显著提升feedparser在实际项目中的表现和稳定性。在下一章节中,我们将进一步探索feedparser在自动化测试和持续集成中的应用,以确保高质量的软件交付。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PySide2故障排除】:DLL加载失败不再成为难题
【打印机故障速解】:HL3150CDN进纸问题的10分钟快速修复法
云计算中的Arthrun:揭秘其卓越的云集成能力
【专业分析】CentOS7.9安装前必备:硬件检查与系统需求深度剖析
【缓存一致性深度解析】:educoder实训作业中的关键挑战及应对
【Tomcat高可用性部署秘诀】:实现零停机时间的策略
GIS设备入门速成:10个核心知识点帮你成为专家
掌握数据库文档精髓:pg016_v_tc.pdf关键信息深度解读
Wireshark基础入门:5分钟掌握网络数据包捕获与分析技巧


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















