Peewee模型序列化与反序列化:构建前后端分离应用
发布时间: 2024-10-01 12:04:56 阅读量: 27 订阅数: 42 

# 1. Peewee简介与前后端分离架构
## 1.1 Peewee简介
Peewee是一个小巧且易于使用的Python ORM(对象关系映射器),它允许开发者通过简单的代码操作数据库,极大地提升了数据库操作的便捷性和代码的可读性。Peewee提供了一组简洁的API,支持多种数据库后端,如SQLite、MySQL和PostgreSQL,特别适合轻量级项目和小型API开发。
## 1.2 前后端分离架构
前后端分离架构已经成为现代Web开发的主流模式,它将前端展示层与后端数据处理层进行解耦,使得前后端开发者可以并行工作,提高了开发效率和系统的可维护性。在这一架构下,Peewee可以作为后端与数据库交互的桥梁,通过提供RESTful API来满足前端的数据需求。
前后端分离不仅使架构更清晰,还带来了诸多好处,比如提高了系统的可扩展性、促进了前端技术的多元化发展、简化了部署流程、易于进行持续集成和持续部署等。下一章我们将深入探讨Peewee模型的基础知识,为深入理解Peewee与前后端分离架构的交互打下基础。
# 2. Peewee模型基础
### 2.1 Peewee模型定义
#### 2.1.1 数据库连接与模型映射
在使用Peewee之前,首先需要建立与数据库的连接。Peewee支持多种数据库系统,如SQLite、MySQL、PostgreSQL等。连接数据库是一个关键步骤,因为所有的数据操作都将在此基础上进行。
```python
from peewee import *
# 定义数据库连接
db = SqliteDatabase('my_database.db')
# 定义模型
class BaseModel(Model):
class Meta:
database = db
# 定义用户模型
class User(BaseModel):
username = CharField(unique=True)
password = CharField()
email = CharField()
# 连接到数据库
db.connect()
```
以上代码展示了如何连接到SQLite数据库,并定义了一个简单的用户模型。数据库连接是通过创建一个`SqliteDatabase`实例来完成的。`BaseModel`类充当所有模型的基类,并设置了`database`属性为`db`,这样所有继承自`BaseModel`的模型都会使用这个数据库实例。
#### 2.1.2 字段类型与数据验证
在Peewee模型中定义字段时,可以通过指定不同的字段类型来映射到数据库的列类型。Peewee提供了多种字段类型,如`CharField`、`IntegerField`、`DateTimeField`等,以适应不同的数据存储需求。
```python
from peewee import *
class User(BaseModel):
username = CharField(unique=True, max_length=30)
password = CharField()
email = CharField()
join_date = DateTimeField()
```
在这个例子中,`username`字段被限制了最大长度为30,且需要在数据库中保持唯一。`password`和`email`字段是普通的字符串,而`join_date`字段使用了`DateTimeField`来存储日期和时间信息。
Peewee还支持在模型字段上添加验证器,以确保传入的数据符合要求。例如,可以使用`RegexValidator`来确保电子邮件地址的有效性。
```python
from peewee import *
class User(BaseModel):
# ...
email = CharField(
null=False,
unique=True,
# 使用正则表达式验证电子邮件
fieldValidators=[RegexValidator(r"[^@]+@[^@]+\.[^@]+")])
```
在上述代码中,`email`字段添加了一个正则表达式验证器来确保字段值匹配电子邮件格式。这有助于提高数据的准确性和质量。
### 2.2 模型查询与操作
#### 2.2.1 基本CRUD操作
CRUD操作是数据库操作的基础,代表创建(Create)、读取(Read)、更新(Update)和删除(Delete)。Peewee提供了一个简洁的API来进行这些操作。
```python
# 创建
User.create(username='testuser', password='password', email='***')
# 读取
user = User.get(User.username == 'testuser')
# 更新
user.email = '***'
user.save()
# 删除
user.delete_instance()
```
在以上例子中,我们演示了如何使用Peewee模型进行基本的CRUD操作。每个操作都是通过相应的方法或属性完成的,如`create()`, `get()`, `save()`, 和`delete_instance()`。Peewee的方法名称清晰地表明了它们各自的功能,使得代码易于理解。
#### 2.2.2 过滤器和聚合查询
过滤器在查询数据库时用于筛选特定条件的数据。Peewee通过`where()`方法提供了灵活的查询条件构建方式。
```python
# 筛选用户名为testuser的用户
users = User.where(User.username == 'testuser').get()
# 或者使用其他操作符进行复杂查询
users = User.where((User.username != 'testuser') & (User.email.endswith('@***')))
```
在这些例子中,我们使用了等于、不等于、以及字符串结尾的操作符来构建查询条件。Peewee的查询构建器支持常见的SQL操作符,并提供了链式调用的接口。
聚合查询通常用于对一组数据进行统计计算,如计数、求和、平均值等。Peewee同样支持这些操作,并将它们封装在模型类中。
```python
# 计算用户总数
total_users = User.select().count()
# 求平均值
average_age = User.select().avg(User.age)
```
以上代码演示了如何使用Peewee进行基本的聚合查询。通过调用`count()`和`avg()`等聚合函数,我们可以轻松地对数据库中的数据进行统计分析。
#### 2.2.3 关联数据的处理
当模型之间存在关系时,Peewee提供了简单的方式来进行关联查询和数据管理。
```python
class Tweet(BaseModel):
user = ForeignKeyField(User, backref='tweets')
content = TextField()
created_at = DateTimeField()
# 获取某个用户的所有推文
tweets = User.get(username='testuser').tweets
```
在上述代码中,我们定义了一个`Tweet`模型,并通过`ForeignKeyField`与`User`模型建立了外键关系。这样,我们就可以轻松地通过用户模型访问其关联的推文数据。
在进行关联查询时,`backref`参数创建了一个反向引用,使得可以从用户实例直接访问其推文集合。这种方法极大地简化了处理关联数据的复杂性,提高了代码的可读性和维护性。
通过这些基础,我们已经完成了对Peewee模型定义、数据库连接、字段类型以及基本CRUD操作的介绍。接下来的章节将深入了解序列化与反序列化理论,并探索如何将Peewee模型与前端数据进行交互。
# 3. 序列化与反序列化理论
在现代Web开发中,数据序列化和反序列化是前后端分离架构的核心组成部分。序列化涉及将数据结构或对象状态转换为可以存储或传输的格式,通常为JSON或XML。反序列化则是执行相反的操作,将存储或传输的格式转换回数据结构或对象状态。理解这两个概念及其实践对于构建高效的前后端交互至关重要。
## 3.1 序列化与反序列化的概念
### 3.1.1 JSON和XML序列化格式介绍
在序列化格式的选择上,JSON和XML是最为常见的两种格式。JSON(JavaScript Object Notation)由于其轻量级和易于人阅读、编写的特性,在Web服务中被广泛采用。与XML相比,JSON在性能上更优,因为它比XML简单,易于解析和生成。
```json
// 示例JSON对象
{
"name": "John Doe",
"age": 30,
"isEmployee": true
}
```
XML(Extensible Markup Language)是一种标记语言,它允许用户自定义标记和文档结构。它在需要复杂文档类型定义(DTD)或在数据交换需要强调文档结构时被采用。
```xml
<!-- 示例XML数据 -->
<person>
<name>John Doe</name>
<age>30</age>
<isEmployee>true</isEmployee>
</person>
```
### 3.1.2 数据传输

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库文件 Peewee,这是一款强大的 ORM(对象关系映射)工具。从基础知识到高级技巧,该专栏涵盖了 Peewee 的各个方面,包括模型创建、数据库连接、事务管理、模型关系、查询优化、数据验证、错误处理、性能调优、扩展库集成以及与不同数据库(如 SQLite、PostgreSQL)的适配。通过深入的讲解和实际示例,该专栏旨在帮助读者掌握 Peewee 的核心概念和最佳实践,从而构建高效、可扩展的数据库应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CanDiva集成解决方案:实现与其他系统无缝连接

# 摘要
CanDiva集成解决方案是一个综合性的系统集成框架,旨在优化数据流管理和技术架构设计。本文首先概述了CanDiva的集成理论基础和实践案例,包括系统集成的概念、发展趋势、技术架构、数据管理和集成过程中的关键因素。其次,文章深入探讨了CanDiva集成的成功实践案例,并分析了实施步骤、解决方案部署以及关键成功因素。
【CUDA与GPU编程】:在Visual Studio中打造强大计算平台的秘诀

# 摘要
本文旨在为读者提供CUDA与GPU编程的系统性指导,从基础概念到实际项目应用的全过程。首先,概述了CUD
AS2.0兼容性危机:如何解决与Flash Player的那些事儿

# 摘要
本文对AS2.0和Flash Player的历史背景进行了回顾,并深入分析了AS2.0的兼容性问题,包括功能性与环境兼容问题的分类及其根本原因
科研必备:MATLAB在二维热传导方程研究中的应用与高级技巧
# 摘要
本文首先介绍了MATLAB在热传导方程研究中的应用,从基础理论讲起,深入探讨了二维热传导方程的数
Pilot Pioneer Expert V10.4故障排除速成课:常见问题与解决方法全攻略

# 摘要
Pilot Pioneer Expert V10.4是一款功能全面的软件,本文旨在概述其基本功能和安装配置。接着,文章深入探讨了软件故障诊断的基础理论,涵盖故障的定义、分类及诊断方法,并介绍了常见软件问题及其排除工具。本文还详细介绍了故障诊断的技巧,包括分析日志文件、性能监控与优化,以及提供了一系列实
RH2288 V2 BIOS固件更新流程:自动化与手动操作的全面解读
# 摘要
本文全面介绍了RH2288 V2服务器BIOS固件更新的策略和方法,包括手动更新流程和自动化更新技术。首先概述了BIOS固件更新的重要性,并指导如何进行准备工作、执行更新和验证。接着深入探讨了自动化更新的优势、策略制定和脚本实现。本文还通过实践案例分析了不同环境下更新策略的对比和风险评估,强调了更新后系统优化与监控的重要性。最后展望了固件更新技术的未来趋势,
FPGA布局必杀技:从零开始,Altium Designer中的布局到优化指南

# 摘要
本文全面探讨了FPGA布局的基础知识、工具使用、实战演练、优化技巧及案例分析。从布局工具Altium Designer的详细介绍开始,深入到基本电路设计、高级布局技巧,以及布局优化与验证的各个方面。文章详细阐述了信号完整性分析、热管理优化以及布局后的验证与测试,旨
HBR3高速连接技术解析:DisplayPort 1.4带你进入快车道
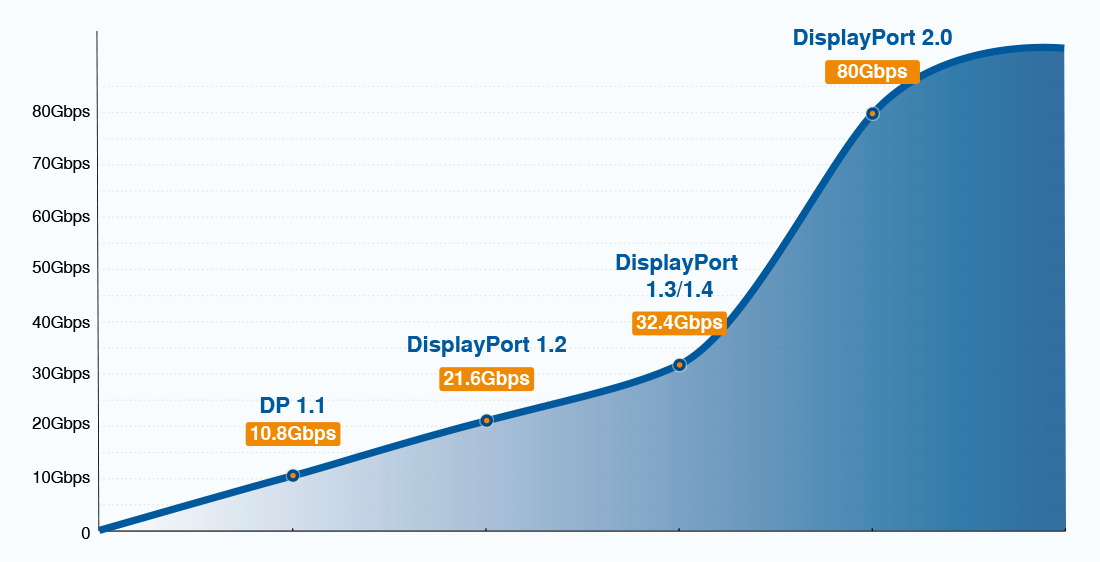
# 摘要
HBR3高速连接技术和DisplayPort 1.4技术标准是现代显示技术的两大支柱,为高端显示器和便携设备提供了先进的连接与显示解决方案。HBR3技术以其高带宽传输的特性在DisplayPort 1.4中得到应用,支持8K视频和HDR,增强了显示流压缩技术。本文详细解读DisplayPort 1.4技术标准,并探讨其在不同应用场景中的
【SPEL+Ref75性能优化】:5大策略助你深度调优SPEL应用性能
# 摘要
随着SPEL(Spring Expression Language)在企业级应用中的广泛应用,其性能优化变得日益重要。本文对SPEL的性能瓶颈进行了深入分析,涵盖了工作原理、性能问题的成因,以及系统资源竞争等多个方面。针对常见的性能瓶颈,本文提出了一系列优化策略,包括代码级别的改进、系统资源配置的优化、并发与同步机制的调整,以及监控与故障排查的方法。通过实际案例,本文详细阐述了每种策略的具
Bootloader开发零基础教程:雅特力MCU AT32F403项目从启动到完成的全过程

# 摘要
本文提供了对Bootloader开发的全面介绍,涵盖从基础理论到深入开发实践的各个方面。首先介绍了Bootloader的概念、作用及其与操作系统的关系,随后详细阐述了其启动流程和结构组件,包括系统复位、初始化以及主要功能模块和硬件抽象层。本文还指导如何搭建开发工具和环境,并且实践
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )