深度强化学习在自然语言处理的语言大师:提升语言理解能力,解锁沟通新境界
发布时间: 2024-08-22 21:49:42 阅读量: 42 订阅数: 21 

深入探索Transformer:重塑自然语言处理的强大引擎.pdf
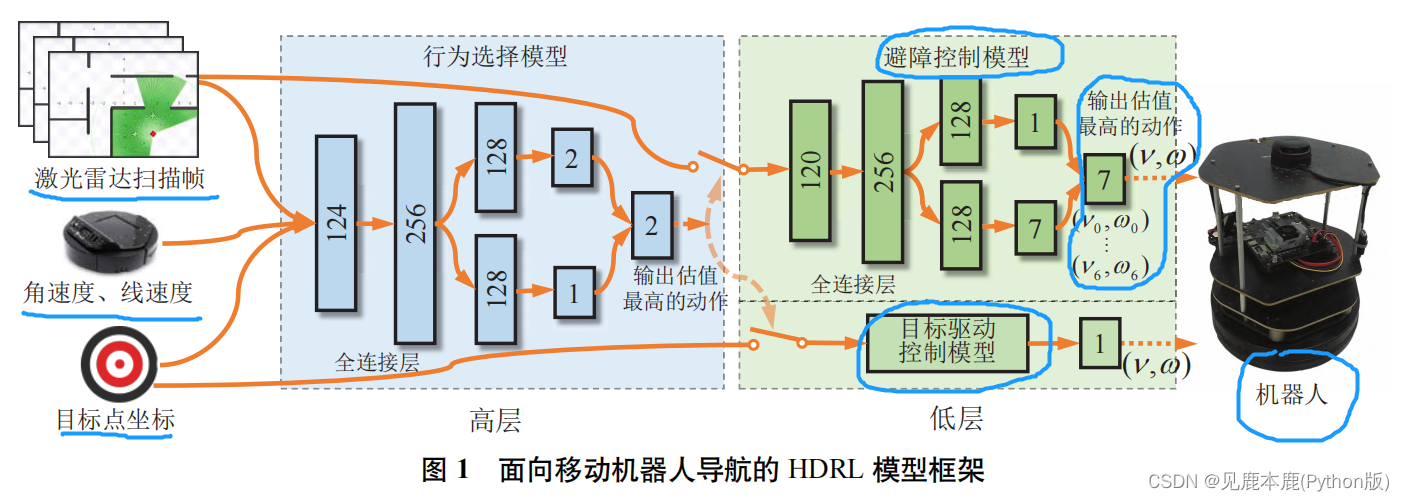
# 1. 深度强化学习与自然语言处理**
深度强化学习(DRL)是一种机器学习技术,它通过与环境的交互来学习最优策略。它与自然语言处理(NLP)的结合为解决 NLP 任务开辟了新的可能性。
DRL 在 NLP 中的优势在于其能够处理复杂的任务,例如文本生成和文本理解。通过使用奖励函数来指导学习,DRL 模型可以学习从输入数据中提取有意义的信息,并生成高质量的输出。此外,DRL 模型可以适应不断变化的环境,从而提高其在现实世界应用中的鲁棒性。
# 2. 深度强化学习在自然语言处理中的应用
深度强化学习 (DRL) 是一种机器学习技术,它使算法能够通过与环境交互并从其错误中学习来解决复杂问题。在自然语言处理 (NLP) 中,DRL 已被成功应用于各种任务,包括文本生成和文本理解。
### 2.1 文本生成
文本生成是指生成类似人类的文本的能力。DRL 已被用于开发文本生成模型,这些模型可以执行各种任务,例如语言建模、对话生成和机器翻译。
#### 2.1.1 语言模型
语言模型是概率分布,它为给定文本序列中下一个单词出现的概率建模。DRL 已被用于训练语言模型,这些模型可以生成连贯且语法正确的文本。
```python
import torch
import torch.nn as nn
class LanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(LanguageModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim)
self.linear = nn.Linear(hidden_dim, vocab_size)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x)
x = self.linear(x)
return x
# 训练语言模型
model = LanguageModel(vocab_size, embedding_dim, hidden_dim)
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(num_epochs):
for batch in train_data:
optimizer.zero_grad()
output = model(batch)
loss = nn.CrossEntropyLoss()(output, batch)
loss.backward()
optimizer.step()
```
**参数说明:**
* `vocab_size`:词汇表大小
* `embedding_dim`:词嵌入维度
* `hidden_dim`:LSTM 隐藏状态维度
* `num_epochs`:训练轮数
**逻辑分析:**
该代码定义了一个语言模型,该模型使用 LSTM 网络来学习单词之间的依赖关系。模型使用交叉熵损失函数进行训练,以最小化预测单词和实际单词之间的差异。
#### 2.1.2 对话生成
对话生成是指生成类似人类的对话的能力。DRL 已被用于开发对话生成模型,这些模型可以与人类进行自然而连贯的对话。
```python
import tensorflow as tf
class DialogueGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(DialogueGenerator, self).__init__()
self.encoder = tf.keras.layers.LSTM(hidden_dim)
self.decoder = tf.keras.layers.LSTM(hidden_dim)
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, x):
x = self.embedding(x)
x, _ = self.encoder(x)
x, _ = self.decoder(x)
x = self.dense(x)
return x
# 训练对话生成模型
model = DialogueGenerator(vocab_size, embedding_dim, hidden_dim)
optimizer = tf.keras.optimizers.Adam()
for epoch in range(num_epochs):
for batch in train_data:
with tf.GradientTape() as tape:
output = model(batch)
loss = tf.keras.losses.SparseCategoricalCrossentropy()(batch, output)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
```
**参数说明:**
* `vocab_size`:词汇表大小
* `embedding_dim`:词

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了深度强化学习在各个领域的实际应用,从游戏 AI 到医疗保健、物流、制造业、机器人、网络安全、自然语言处理、计算机视觉、推荐系统、搜索引擎和社交网络。通过深入浅出的文章,专栏揭示了深度强化学习的强大潜力,从小白到高手,打造你的下棋 AI;从入门到精通,解锁 AI 奥秘;揭秘 AlphaGo 的制胜秘诀;辅助诊断和治疗,提升医疗效率;优化配送效率,提升物流效能;提高生产效率,迈向智能制造;赋予机器人智能,开启自动化新时代;防御网络攻击,守护网络空间;提升语言理解能力,解锁沟通新境界;让计算机学会看,洞悉世界奥秘;个性化推荐,打造用户专属体验;提升搜索结果相关性,直达用户需求;优化用户体验,打造社交新风尚。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
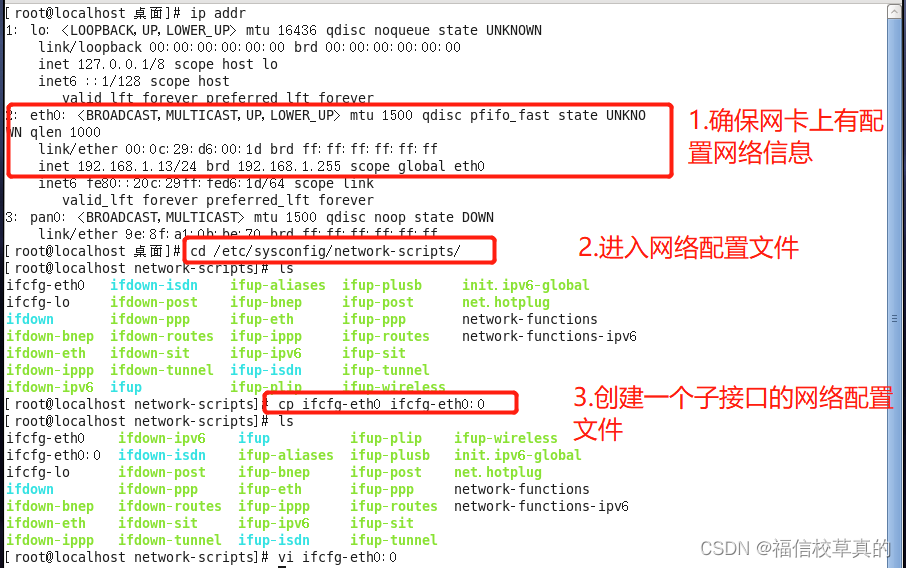
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
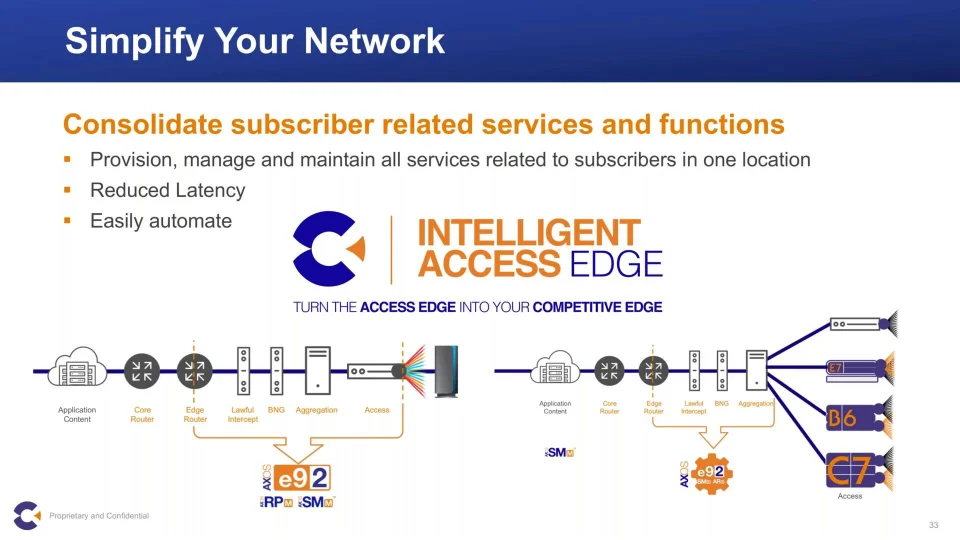
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )