深度强化学习在机器人的赋能之旅:赋予机器人智能,开启自动化新时代
发布时间: 2024-08-22 21:38:32 阅读量: 36 订阅数: 43 
# 1. 深度强化学习的基本原理**
深度强化学习是一种机器学习方法,它使代理能够通过与环境交互来学习最优行为策略。它基于马尔可夫决策过程(MDP)框架,其中代理在状态空间中采取动作,并根据动作和状态获得奖励。
深度强化学习的关键组件包括:
* **状态空间:**代理可以观察到的环境的表示。
* **动作空间:**代理可以采取的动作集合。
* **奖励函数:**衡量代理行为好坏的函数。
* **价值函数:**状态或动作价值的估计,指导代理决策。
* **策略:**代理根据当前状态选择动作的函数。
# 2.1 机器人运动控制
### 2.1.1 运动规划和轨迹生成
**运动规划**是指确定机器人从初始状态到目标状态的一条可行路径。**轨迹生成**是在给定路径后,生成机器人关节空间中的具体运动轨迹。
**运动规划算法**包括:
- **基于采样的规划算法:**如 RRT(Rapidly-exploring Random Tree)、PRM(Probabilistic RoadMap)等,通过随机采样和连接的方式探索环境,生成路径。
- **基于图搜索的规划算法:**如 A*、Dijkstra 等,将环境表示为图,通过搜索图中的最短路径生成路径。
- **基于优化的方法:**如梯度下降、粒子群优化等,通过优化目标函数(如路径长度、平滑度等)生成路径。
**轨迹生成算法**包括:
- **多项式插值法:**使用多项式拟合关节角度随时间的变化,生成轨迹。
- **最小二乘法:**通过最小化轨迹与给定约束(如速度、加速度等)的误差,生成轨迹。
- **动力学建模:**基于机器人的动力学模型,生成满足运动学和动力学约束的轨迹。
### 2.1.2 力控和阻抗控制
**力控**是指控制机器人的末端执行器对环境施加的力或力矩。**阻抗控制**是指控制机器人的阻抗(力与位移或速度的关系),以实现特定的力学行为。
**力控算法**包括:
- **PID 控制:**使用比例、积分、微分项调节机器人的力输出。
- **自适应控制:**根据环境的反馈调整控制参数,以实现更好的力控效果。
- **神经网络控制:**使用神经网络学习环境的动力学模型,实现更鲁棒的力控。
**阻抗控制算法**包括:
- **经典阻抗控制:**根据阻抗模型(如弹簧-阻尼器模型)设计控制律,实现特定的阻抗行为。
- **变阻抗控制:**根据环境的变化动态调整阻抗参数,以提高机器人的适应性。
- **学习型阻抗控制:**使用强化学习或其他机器学习技术学习环境的阻抗模型,实现更智能的阻抗控制。
# 3. 深度强化学习在机器人赋能中的实践**
**3.1 机器人抓取和操作**
**3.1.1 物体抓取和操纵**
深度强化学习在机器人抓取和操纵中发挥着至关重要的作用,使机器人能够精确地抓取和操纵各种物体。一种常用的方法是使用基于模型的强化学习 (MBRL) 算法,该算法利用物理模型来模拟机器人与物体之间的交互。
例如,研究人员开发了一种基于 MBRL 的机器人抓取系统,该系统利用了物体形状和质地的先验知识。该系统首先使用深度学习算法从图像中提取物体的几何特征,然后使用物理模型预测抓取动作对物体的影响。通过强化学习,该系统不断调整其抓取策略,以最大化抓取成功率。
**代码块:**
```python
import numpy as np
import gym
from stable_baselines3 import PPO
# 创建基于 MBRL 的抓取环境
env = gym.make('FetchReach-v1')
# 创建 PPO 代理
model = PPO('MlpPolicy', env, verbose=1)
# 训练代理
model.learn(total_timesteps=100000)
# 使用训练后的代理抓取物体
obs = env.reset()
for i in range(100):
action, _ = model.predict(obs)
obs, reward, done, _ = env.step(action)
if done:
break
```
**逻辑分析:**
* `gym.make('FetchReach-v1')`

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了深度强化学习在各个领域的实际应用,从游戏 AI 到医疗保健、物流、制造业、机器人、网络安全、自然语言处理、计算机视觉、推荐系统、搜索引擎和社交网络。通过深入浅出的文章,专栏揭示了深度强化学习的强大潜力,从小白到高手,打造你的下棋 AI;从入门到精通,解锁 AI 奥秘;揭秘 AlphaGo 的制胜秘诀;辅助诊断和治疗,提升医疗效率;优化配送效率,提升物流效能;提高生产效率,迈向智能制造;赋予机器人智能,开启自动化新时代;防御网络攻击,守护网络空间;提升语言理解能力,解锁沟通新境界;让计算机学会看,洞悉世界奥秘;个性化推荐,打造用户专属体验;提升搜索结果相关性,直达用户需求;优化用户体验,打造社交新风尚。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ISO20860-1-2008中文版:企业数据分析能力提升指南
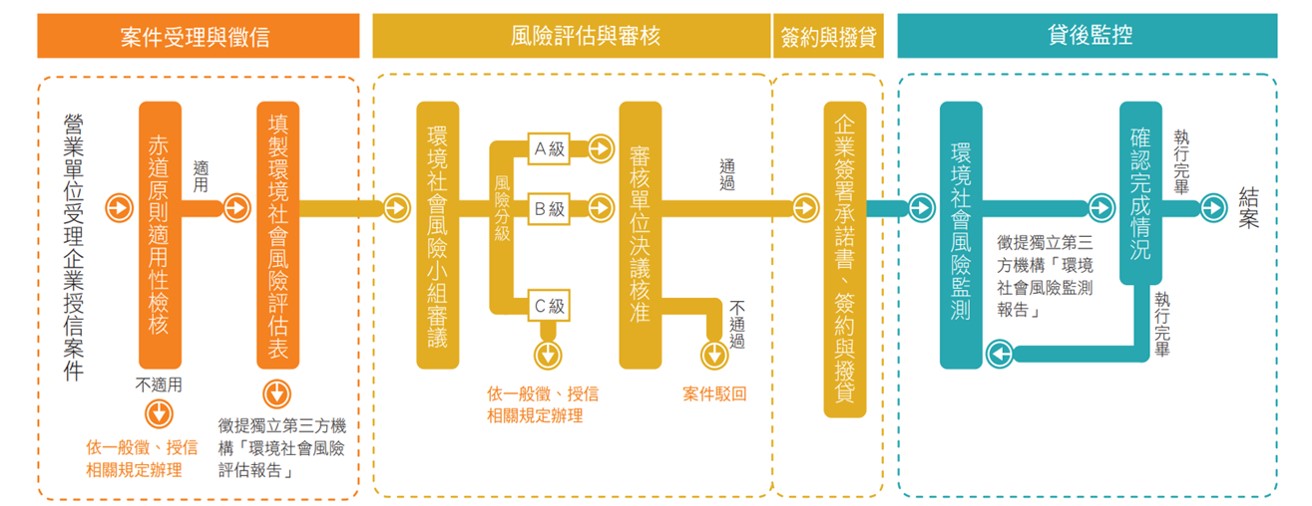
# 摘要
企业数据分析能力对于现代企业的成功至关重要。本文首先探讨了数据分析的重要性以及其理论基础,包括数据分析的定义、核心流程和不同分析方法论。接着,详细介绍了数据预处理技术、分析工具及数据可视化技巧。在实战应用方面,本文深入分析了数据分析在业务流程优化、客户关系管理和风险控制
提升设计到制造效率:ODB++优化技巧大公开

# 摘要
本文全面介绍并分析了ODB++技术的特性、设计数据结构及其在制造业的应用。首先,简要概述了ODB++的优势及其作为设计到制造数据交换格式的重要价值。接着,详细探讨了ODB++的设计数据结构,包括文件结构、逻辑层次、数据精度与错误检查等方面,为读者提供了对ODB++深入理解的框架。第三部分聚焦于ODB++数据的优化技巧,包括数据压缩、归档、提取、重构以及自动化处理流程,旨在提升数据管理和制造效率。第四章通过
【Shell脚本高级应用】:平衡密码管理与自动登录的5大策略

# 摘要
在数字化时代,密码管理和自动登录技术对于提高效率和保障网络安全至关重要。本文首先探讨了密码管理和自动登录的必要性,然后详细介绍了Shell脚本中密码处理的安全策略,包括密码的存储和更新机制。接着,本文深入分析了SSH自动登录的原理与实现,并
【启动流程深度解析】:Zynq 7015核心板启动背后的原理图秘密
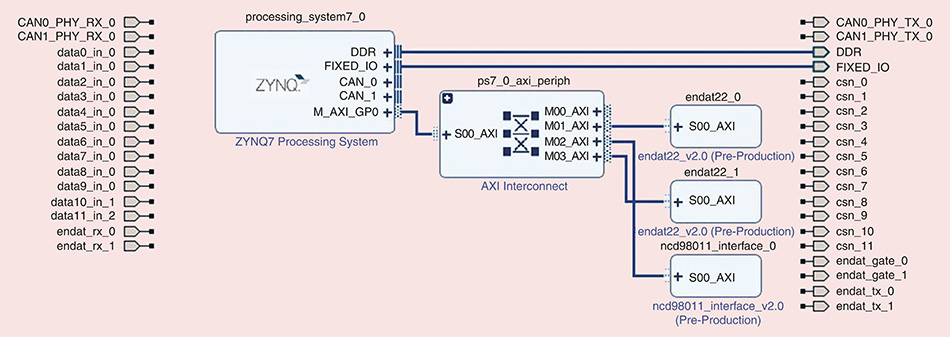
# 摘要
Zynq 7015核心板作为一款集成了双核ARM Cortex-A9处理器和可编程逻辑(PL)的片上系统(SoC),在嵌入式设计领域中扮演着重要角色。本文详细介绍了Zynq 7015核心板的启动过程,包括启动机制的理论基础、启动流程的深入实践以及启动问题的诊断与解决。通过对启动序
卫星导航与无线通信的无缝对接:兼容性分析报告

# 摘要
随着科技的发展,卫星导航与无线通信系统的融合变得越来越重要。本文旨在深入探讨卫星导航和无线通信系统之间的兼容性问题,包括理论基础、技术特点、以及融合技术的实践与挑战。兼容性是确保不同系统间有效互操作性的关键,本文分析了兼容性理论框架、分析方法论,并探讨了如何将这些理论应用于实践。特别地,文章详细评估了卫星导航系统
【客户满意度提升】:BSC在服务管理中的应用之道
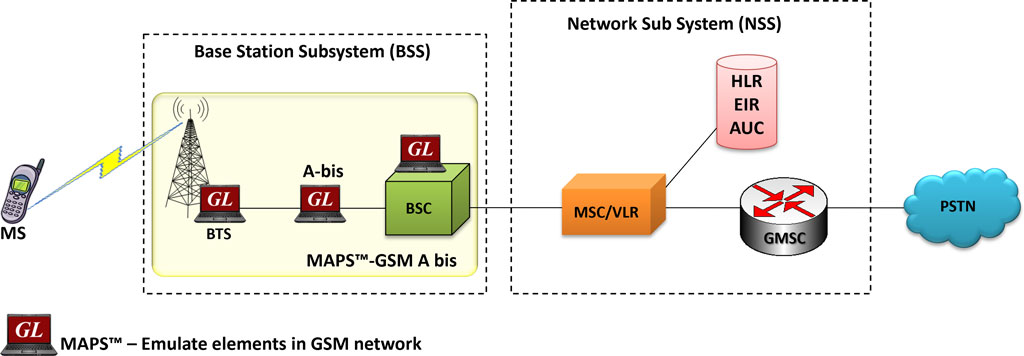
# 摘要
平衡计分卡(BSC)是一种综合绩效管理工具,已被广泛应用于服务管理领域以衡量和提升组织绩效。本文首先概述了BSC的理论基础,包括其核心理念、发展历史以及在服务管理中的应用模型。随后,文章深入探讨了BSC在实践应用中的策略制定、服务流程优化以及促进团队协作和服务创新的重要性。通过对行业案例的分析,本文还评估了BSC在提升客户满意度方面的作用,并提出了面对挑战的应对策略。最后,文章综合评价了BSC的优势和局限性,为企业如何有效整合BSC与服
【SR-2000系列扫码枪性能提升秘籍】:软件更新与硬件升级的最佳实践

# 摘要
本文对SR-2000系列扫码枪的性能提升进行了全面研究,涵盖软件更新与硬件升级的理论和实践。首先介绍了SR-2000系列扫码枪的基础知识,然后深入探讨了软件更新的理论基础、实际操作流程以及效果评估。接着,对硬件升级的必要性、实施步骤和后续维护进行了分析。通过案例分析,本文展示了软件更新和硬件升级对性能的具体影响,并讨论了综合性能评估方法和管理策略。最后,展望了SR-2000系列扫码枪的未来,强调了行业发展趋势、技术革新
鼎甲迪备操作员故障排除速成课:立即解决这8个常见问题
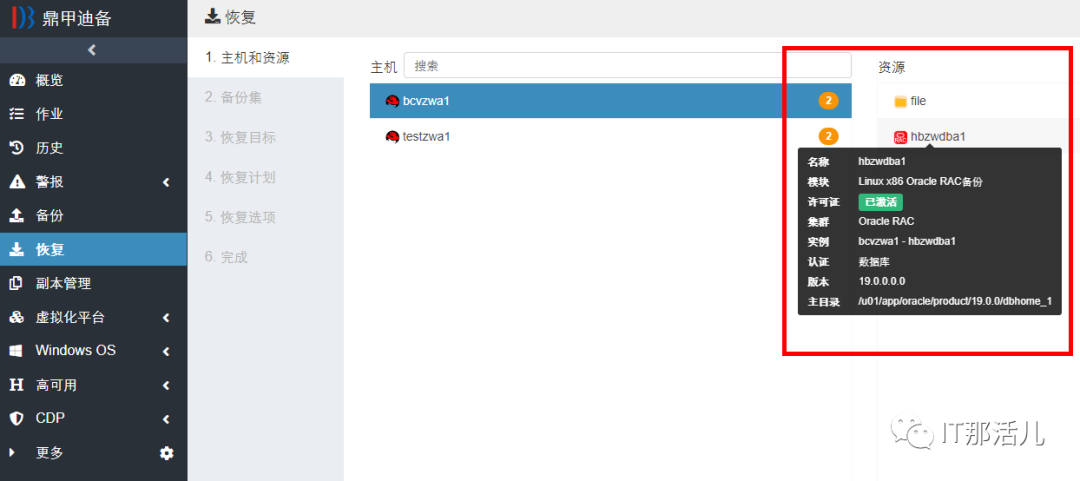
# 摘要
本文全面介绍了鼎甲迪备操作员在故障排除中的综合方法和实践。首先概述了故障排除的基础理论与方法,包括故障诊断的基本原理和处理流程,随后深入探讨了最佳实践中的预防措施和快速响应策略。文章通过具体案例分析,详细解读了系统启动失败、数据恢复、网络连接不稳定等常见问题的诊断与解决方法。进一步,本文介绍了使用专业工具进行故障诊断的
实时系统设计要点:确保控制系统的响应性和稳定性的10大技巧

# 摘要
实时系统设计是确保系统能够及时响应外部事件的重要领域。本文首先概述了实时系统的基本理论,包括系统的分类、特性、实时调度理论基础和资源管理策略。随后,深入探讨了实时系统设计的关键实践,涵盖了架构设计、实时操作系统的应用以及数据通信与同步问题。本文还着重分析了提升实时系统稳定性和可靠性的技术和方法,如硬件冗余、软件故障处理和测试验证。最后,展望了并发控制和新兴技术对实时系统
【IEEE 24 RTS系统数据结构揭秘】:掌握实时数据处理的10大关键策略
# 摘要
本文详细介绍了IEEE 24 RTS系统的关键概念、实时数据处理的基础知识、实时数据结构的实现方法,以及实时数据处理中的关键技术
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )