Linux入门指南:快速掌握基本命令与操作方法
发布时间: 2024-01-22 19:12:24 阅读量: 37 订阅数: 21 
# 1. Linux基础概述
## 1.1 什么是Linux操作系统
Linux是一种开源的操作系统,最初由芬兰的林纳斯·托瓦兹(Linus Torvalds)在1991年创建。它基于UNIX操作系统,具有高度的稳定性、安全性和可靠性。Linux操作系统具有良好的兼容性,可以运行在各种硬件平台上,同时支持众多的软件应用。Linux还是一种多用户、多任务操作系统,可以同时支持多个用户的同时运行多个程序。
## 1.2 Linux的优势与特点
Linux操作系统具有许多优势和特点,包括:
- 开源性:Linux的核心代码是开放源代码的,任何人都可以查看、修改和分发。这使得Linux具有高度的透明度和灵活性。
- 稳定性:Linux系统稳定性强,能够长时间运行而不会出现意外崩溃或死机的情况。这得益于Linux的良好的内核设计和错误容错机制。
- 安全性:由于Linux开放源代码的特性,任何人都可以审查系统代码,从而减少了潜在的漏洞和后门,提升了系统的安全性。
- 多样性:Linux有多个发行版可供选择,如Ubuntu、CentOS、Debian等。每个发行版都有自己的特点和适用场景,用户可以根据需求选择最合适的发行版。
- 强大的命令行工具:Linux操作系统提供了丰富而强大的命令行工具,使用户可以通过命令行来完成多种任务,如文件管理、软件安装和配置等。
## 1.3 Linux发行版的选择
Linux有多个不同的发行版可供选择,每个发行版都有自己的特点和适用场景。以下是几个常见的Linux发行版:
- Ubuntu:基于Debian发行版,易于上手,适用于桌面和服务器使用。
- CentOS:基于Red Hat Enterprise Linux (RHEL)发行版,稳定性强,适用于服务器和企业环境。
- Fedora:由Red Hat公司支持的社区发行版,社区活跃,适用于桌面和开发环境。
- Debian:兼具稳定性和灵活性,适用于桌面和服务器环境。
选择合适的Linux发行版需要考虑使用场景、对软件支持的要求、安全性需求等因素。可以根据个人需求和偏好来选择最合适的Linux发行版。
# 2. 命令行基础
## 2.1 基本命令行操作介绍
在Linux系统中,命令行是最常用的操作方式之一,通过命令行可以完成几乎所有的操作任务。下面介绍一些常用的基本命令行操作:
### 2.1.1 文件和目录操作
- `ls`:列出目录内容
- 示例:`ls -l`,以详细列表形式显示目录内容
- 示例:`ls -a`,显示所有包括隐藏文件在内的目录内容
- `cd`:切换目录
- 示例:`cd /usr/local`,切换到/usr/local目录
- 示例:`cd ~`,切换到当前用户的主目录
- `mkdir`:创建目录
- 示例:`mkdir test`,在当前目录下创建名为test的目录
- `rm`:删除文件或目录
- 示例:`rm file1`,删除名为file1的文件
- 示例:`rm -r dir1`,递归删除名为dir1的目录及其内容
- `cp`:复制文件或目录
- 示例:`cp file1 file2`,将file1复制为file2
- 示例:`cp -r dir1 dir2`,递归复制dir1目录及其内容为dir2
- `mv`:移动文件或目录
- 示例:`mv file1 /tmp`,将file1移动到/tmp目录
- 示例:`mv file1 newfile`,将file1重命名为newfile
### 2.1.2 权限管理
- `chmod`:修改文件权限
- 示例:`chmod u+r file1`,给文件file1的所有者添加读权限
- 示例:`chmod g-w file1`,去除文件file1的所属组的写权限
- `chown`:修改文件所有者
- 示例:`chown user1 file1`,将文件file1的所有者修改为user1
- 示例:`chown user1:group1 file1`,将文件file1的所有者修改为user1,并且所属组修改为group1
以上是一些基本的命令行操作介绍,这些命令是Linux系统中必须掌握的基础操作,对于日常的系统管理和开发任务都是至关重要的。
接下来,我们将具体介绍文件编辑与处理的相关命令和技巧。
# 3. 文件编辑与处理
在Linux系统中,文件的编辑和处理是日常工作中非常常见的操作。本章将介绍如何使用Vi或Vim编辑文件,以及一些常用的文本处理工具和实用的文件操作技巧。
#### 3.1 使用Vi或Vim编辑文件
Vi和Vim是Linux系统中非常常用的文本编辑器,对于初学者来说可能需要一些时间来适应其操作方式。以下是一些基本的Vi/Vim操作命令:
- **i**:切换到插入模式,可以开始输入文本
- **Esc**:退出插入模式,返回命令模式
- **:w**:保存文件
- **:q**:退出编辑器
- **:wq**:保存并退出
- **dd**:删除一行
- **yy**:复制一行
- **p**:粘贴
这只是Vi/Vim编辑器的一小部分操作命令,更多高级操作可以通过查阅文档或在线教程学习。
#### 3.2 文本处理工具介绍
除了Vi/Vim之外,Linux还提供了许多命令行下的文本处理工具,如sed和awk。这些工具可以用来进行文本的搜索、替换、提取等操作,非常适合在Shell脚本中进行文本处理。
例如,可以使用sed命令进行简单的文本替换:
```shell
sed 's/old_text/new_text/g' filename
```
#### 3.3 实用的文件操作技巧
在Linux系统中,有许多实用的文件操作技巧可以帮助提高工作效率,比如使用通配符进行文件匹配、使用管道符(|)将多个命令连接起来实现复杂操作等。
下面是一个例子,使用通配符和管道符将多个命令连接起来,实现对多个文件进行搜索并输出结果:
```shell
grep "keyword" /path/to/files/*.txt | sort | uniq
```
这些文件操作技巧能够在实际工作中发挥重要作用,帮助用户更高效地进行文件操作和管理。
# 4. 系统管理命令
在Linux系统中,系统管理是非常重要的任务,而系统管理命令则是我们进行系统管理的重要工具。本章将介绍一些常用的系统管理命令,包括进程管理、网络配置与管理以及包管理工具的基本用法。
#### 4.1 进程管理
在Linux系统中,进程管理是一个非常重要的任务。以下是一些常用的进程管理命令:
- `ps`:显示系统中当前进程的状态。
- `top`:实时显示系统中各个进程的资源占用情况。
- `kill`:终止指定进程。
- `pidof`:查找指定进程的PID。
```bash
# 列出当前系统中的所有进程
ps aux
# 实时查看系统中进程的资源占用情况
top
# 终止PID为1234的进程
kill 1234
# 查找特定进程(如sshd)的PID
pidof sshd
```
#### 4.2 网络配置与管理
在Linux系统中,网络配置与管理也是系统管理的重要部分。以下是一些常用的网络管理命令:
- `ifconfig`:查看和配置网络接口的命令。
- `ping`:用于测试与目标主机的连通性。
- `netstat`:显示网络状态信息。
- `iptables`:用于配置IPv4数据包过滤规则。
```bash
# 查看所有网络接口的配置信息
ifconfig -a
# 测试与目标主机的连通性
ping www.example.com
# 显示系统的网络状态信息
netstat -ant
# 配置IPv4数据包过滤规则
iptables -A INPUT -s 192.168.1.1 -j DROP
```
#### 4.3 包管理工具介绍
在Linux系统中,包管理工具是非常重要的,它可以帮助我们更方便地安装、卸载和管理软件包。以下是一些常用的包管理工具:
- `apt-get`:Debian及其衍生发行版(如Ubuntu)中用于包管理的工具。
- `yum`:Red Hat及其衍生发行版(如CentOS)中用于包管理的工具。
- `dnf`:Fedora中用于包管理的工具。
- `zypper`:openSUSE中用于包管理的工具。
```bash
# 使用apt-get安装更新软件包
sudo apt-get update
sudo apt-get install package_name
# 使用yum安装更新软件包
sudo yum update
sudo yum install package_name
# 使用dnf安装更新软件包
sudo dnf update
sudo dnf install package_name
# 使用zypper安装更新软件包
sudo zypper refresh
sudo zypper install package_name
```
希望以上内容能够帮助你更好地了解Linux系统管理命令的基本用法。
# 5. Shell脚本入门
在本章中,我们将介绍Shell脚本的基础知识和语法,帮助读者快速入门Shell脚本编程。通过学习本章内容,读者将能够掌握Shell脚本的基本概念、变量的使用、条件语句、循环和函数编写等知识。
## 5.1 Shell脚本基础
Shell脚本是一种用来自动化执行一系列命令的脚本语言。它可以帮助用户完成一些重复性的工作,提高工作效率。在Linux系统中,常见的Shell脚本语言包括Bash、Korn shell等。
```bash
#!/bin/bash
# 这是一个简单的Shell脚本示例
echo "Hello, World!"
```
**代码说明:**
- `#!/bin/bash`:指定了使用Bash作为解释器
- `echo "Hello, World!"`:打印输出"Hello, World!"
**代码总结:**
以上示例展示了一个简单的Shell脚本,使用`echo`命令打印了"Hello, World!"的字符串,`#!/bin/bash`是Shebang用来指定解释器路径。
**结果说明:**
在命令行执行该脚本,会输出"Hello, World!"。这是一个最简单的Shell脚本,用于展示基本语法。
## 5.2 变量与条件语句
Shell脚本中可以使用变量来存储数据,并且可以根据条件来执行不同的命令。下面是一个简单的示例,演示了变量和条件语句的使用。
```bash
#!/bin/bash
# 变量和条件语句示例
NAME="John"
if [ "$NAME" = "John" ]; then
echo "Hello, $NAME!"
else
echo "Hello, stranger!"
fi
```
**代码说明:**
- `NAME="John"`:定义了一个名为`NAME`的变量,并赋值为"John"
- `if [ "$NAME" = "John" ]; then`:判断变量`NAME`的取值是否为"John"
- `echo "Hello, $NAME!"`:根据条件输出不同的问候语
**代码总结:**
上述示例演示了如何使用变量和条件语句,根据变量取值的不同输出不同的问候语。
**结果说明:**
在命令行执行该脚本,由于`NAME`变量的取值为"John",所以会输出"Hello, John!"。
## 5.3 循环与函数
Shell脚本也支持循环和函数的定义,通过循环可以重复执行一段命令或一系列命令,通过函数可以封装一段逻辑以便重复使用。下面是一个简单的循环和函数示例:
```bash
#!/bin/bash
# 循环和函数示例
for ((i=1; i<=5; i++)); do
echo "Count: $i"
done
function greet() {
local name=$1
echo "Welcome, $name!"
}
greet "Alice"
```
**代码说明:**
- `for ((i=1; i<=5; i++)); do`:使用`for`循环打印数字1到5
- `function greet() {`:定义了一个名为`greet`的函数,用于打印欢迎词
**代码总结:**
上述示例展示了如何使用`for`循环和定义函数,并在函数中使用局部变量。
**结果说明:**
在命令行执行该脚本,会输出数字1到5,以及"Welcome, Alice!"的欢迎词。
希望这一章的内容能帮助你更好地理解Shell脚本的基础知识和语法,为日常的Shell脚本编程奠定基础。
# 6. 实际应用与技巧
在这一章节中,我们将介绍一些常见的实际应用和技巧,帮助读者更加高效地使用Linux操作系统。
### 6.1 Shell环境配置
在Linux中,Shell是用户与操作系统之间进行交互的一种接口。合理配置Shell的环境可以提高工作效率。以下是一些常见的Shell环境配置技巧:
#### 6.1.1 别名和函数
通过定义别名和函数,可以快速执行一些常用的命令或指令序列。例如,我们可以将常用的命令`ls -l`定义为别名`ll`,即在命令行中输入`ll`等同于输入`ls -l`。
```shell
alias ll='ls -l'
```
另外,我们也可以定义一个函数来完成更加复杂的操作。例如,下面的函数可以一键打开一个有序列表文件,并在文件末尾追加当前日期:
```shell
ol() {
vim ~/path/to/olist.txt
date >> ~/path/to/olist.txt
}
```
#### 6.1.2 Shell提示符定制
通过修改Shell提示符的样式和内容,可以使命令行界面更加个性化。例如,我们可以将提示符显示为当前用户名和路径:
```shell
PS1='\[\033[35m\]\w\[\033[0m\]\$ '
```
在上面的例子中,`\[\033[35m\]`设置了路径显示为紫色,`\[\033[0m\]`用于关闭颜色设置。
### 6.2 实际案例演示
本节将通过一个实际案例,演示如何使用Linux的一些高级命令和技巧解决问题。
#### 6.2.1 案例场景
假设我们有一个存储着大量日志文件的目录,并且我们需要查找其中包含特定关键词的文件。该目录结构如下:
```
logs/
├── log1.txt
├── log2.txt
├── log3.txt
└── ...
```
我们的目标是查找包含关键词`error`的日志文件。
#### 6.2.2 解决方案
首先,我们可以使用`grep`命令来查找包含关键词的文件,然后使用`find`命令来查找指定目录下的文件。具体命令如下:
```shell
find logs/ -type f -exec grep -l "error" {} +
```
上述命令将在`logs/`目录下递归搜索所有文件,并且对每个文件使用`grep`命令进行关键词匹配,匹配成功则输出文件路径。
### 6.3 常用工具与技巧
在Linux中,有许多强大且实用的工具和技巧可以提高工作效率。以下是一些常见的工具和技巧:
- 使用`screen`或`tmux`命令进行会话管理,可以在一个终端窗口中同时运行多个会话。
- 使用`ssh`命令实现远程登录和执行命令,方便远程管理服务器。
- 使用`rsync`命令进行文件同步和备份,可以快速进行文件传输和同步。
- 使用`grep`命令进行文本搜索,可以快速查找文件中的指定字符串。
- 使用`awk`或`sed`命令进行文本处理,可以方便地进行文本替换、格式化等操作。
以上仅是一些常见的工具与技巧,读者可以根据自己的实际需求进行深入学习和应用。
希望通过本章的介绍,读者能够更好地掌握Linux的实际应用和技巧,提高自己的工作效率。下一章节我们将总结全书的内容并给出一些学习建议。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏着眼于Linux操作系统中的关键要素Linux、Vim编辑器和ext4文件系统,提供了一系列实用的指南和技巧,帮助读者快速掌握基本命令与操作方法,提高对文本编辑的效率,理解默认文件系统和文件管理技巧,以及定制编辑环境和优化文件存储效率。此外,专栏还涵盖了Linux权限管理、Vim高级功能探秘、Linux系统管理技巧、Vim插件使用实例、ext4文件系统备份与恢复策略、Linux网络配置与优化、以及与其他编辑器的比较与切换等主题。通过深入剖析和实际操作,读者能够掌握Shell脚本编程基础,修复文件系统故障,以及提高编辑效率。无论您是Linux初学者还是有一定经验的用户,本专栏将为您提供全面而实用的指导,助您成为Linux与Vim的有力专家。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
机器学习中的变量转换:改善数据分布与模型性能,实用指南
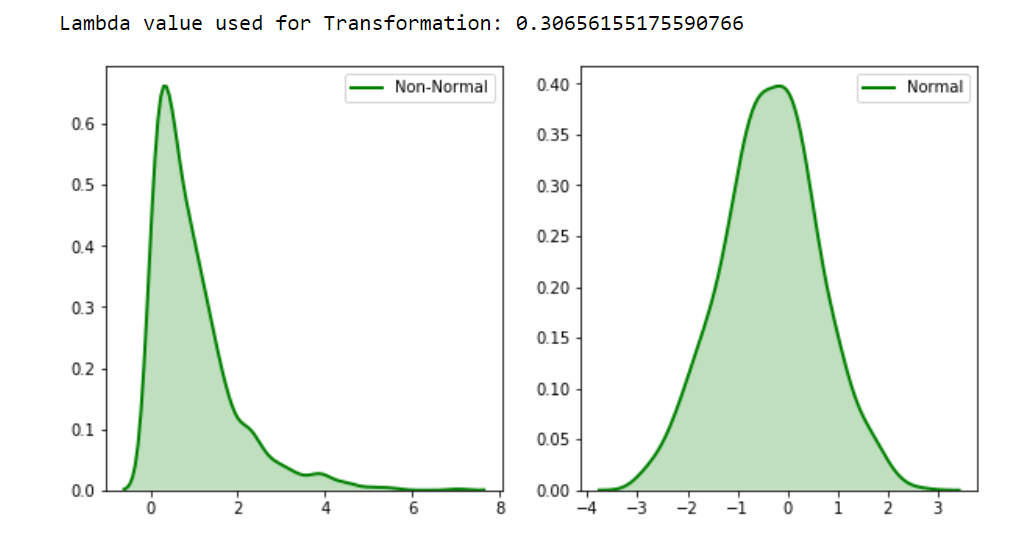
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
大规模深度学习系统:Dropout的实施与优化策略
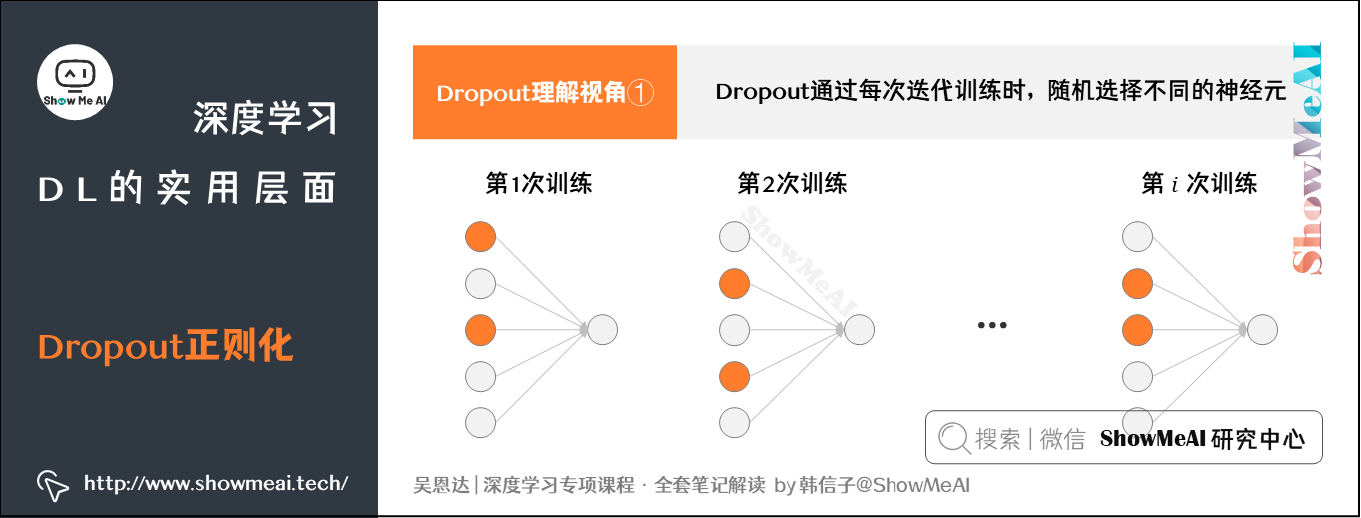
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
ANOVA深度解析:如何通过方差分析提升机器学习模型性能(权威指南)
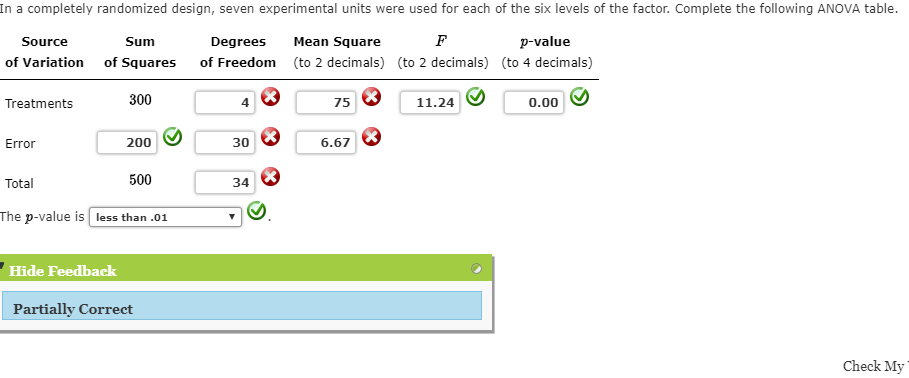
# 1. ANOVA方差分析概述
方差分析(ANOVA)是一种统计方法,用于评估三个或更多样本均值之间的差异是否具有统计学意义。它被广泛用于实验设计和调查研究中,以分析影响因素对结果变量的独立作用。
## 1.1 方差分析的重要性
在数据分析中,当我们想了解分类变量对连续变量是否有显著影响时,方差分析就显得尤为重要。它不
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
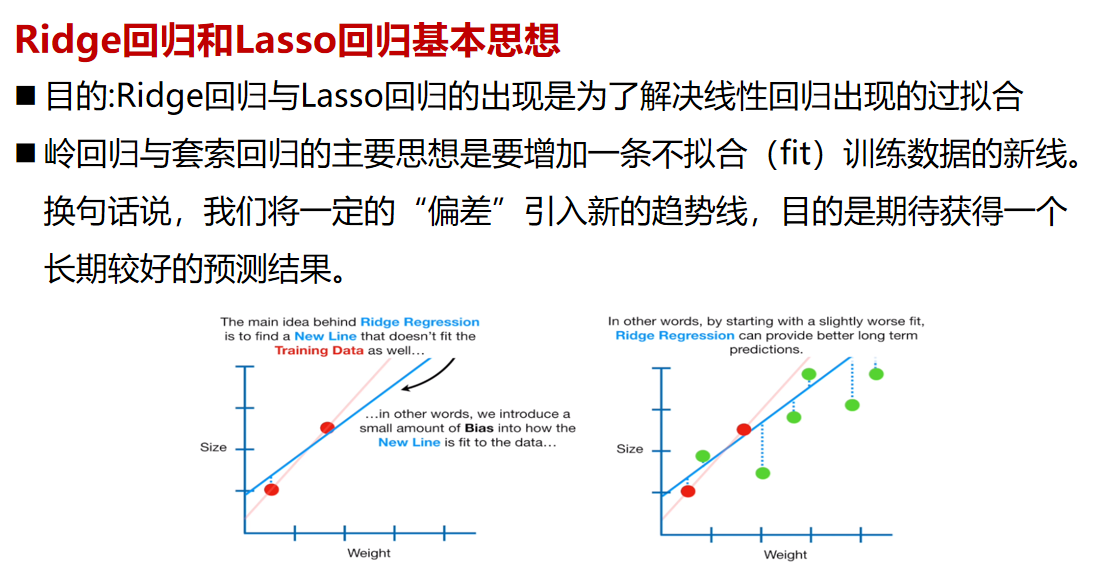
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
推荐系统中的L2正则化:案例与实践深度解析
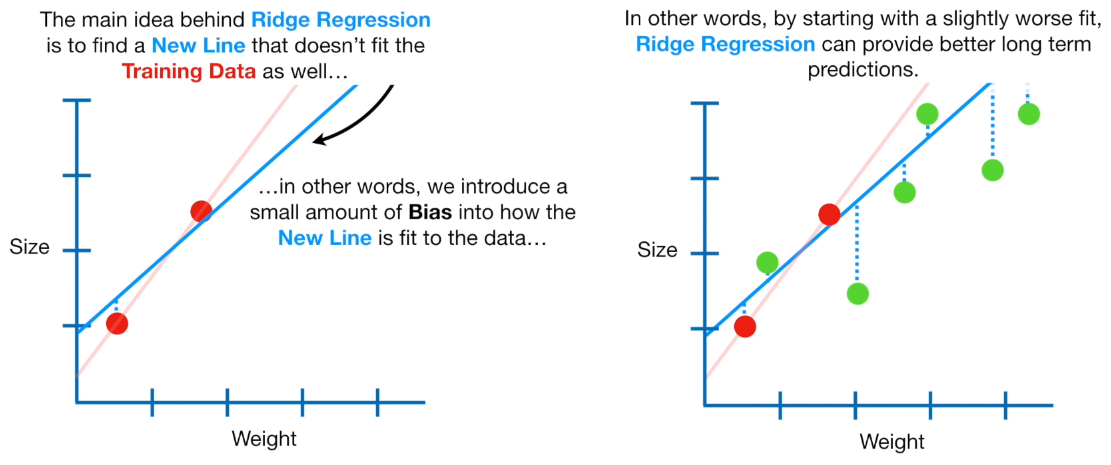
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )