【代码实现指南】:RNN从理论到实践的步骤详解
发布时间: 2024-09-05 12:56:14 阅读量: 54 订阅数: 45 

白色大气风格的旅游酒店企业网站模板.zip
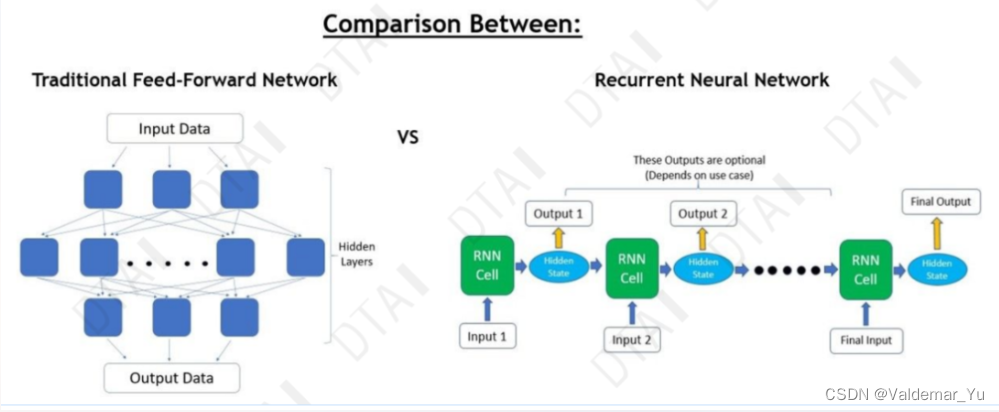
# 1. RNN基础理论简介
## 1.1 循环神经网络的起源与概念
循环神经网络(Recurrent Neural Networks,RNNs)是深度学习领域的一种重要网络结构,用于处理序列数据。它通过保留上一个时间步的信息,为当前时间步输入增加了上下文信息,从而捕捉数据的时序特性。
## 1.2 RNN的工作原理
RNN的核心在于其循环连接,这种连接使得网络具备了处理可变长度输入的能力。在训练过程中,RNN通过时间展开来处理序列,每个时间步的输出可以作为下一个时间步的输入,实现信息的持续传递。
## 1.3 RNN的应用场景
RNN广泛应用于语音识别、自然语言处理、时间序列分析等领域。其对于上下文敏感的特性,使其在处理有时间关联性的数据时表现出色。比如,RNN能够根据前文内容预测文本或语言中的下一个词。
# 2. RNN的数学原理和模型结构
### 2.1 RNN的数学基础
#### 2.1.1 序列数据和时间步的概念
序列数据是一种按特定顺序排列的数据集合,例如时间序列数据、文字、音视频信号等。这些数据的共同特点在于,它们都具有时间或序列上的相关性,这种相关性在时间维度上连续的序列数据中尤为明显。时间步(timestep)是序列数据的一个基本单位,用于表示序列中的每个时间点,数据在这个时间点的值构成了序列中的一个元素。
在RNN中,时间步是描述数据流中单个时刻的重要概念。网络在每个时间步接收一个输入并生成一个输出,同时内部状态会根据输入和前一时间步的状态进行更新。这种设计使得RNN能够处理任意长度的序列数据。
#### 2.1.2 循环神经网络的前向传播
循环神经网络的前向传播是数据在时间步上通过网络的流动过程。在时间步`t`,RNN接受当前的输入`x_t`和前一时间步的隐藏状态`h_{t-1}`,并产生当前时间步的隐藏状态`h_t`和输出`o_t`。数学表达式如下:
```math
h_t = f(W \cdot h_{t-1} + U \cdot x_t + b)
```
其中,`f`代表激活函数(如tanh或ReLU),`W`和`U`是权重矩阵,`b`是偏置向量。隐藏状态`h_t`是网络记忆的中间表示,它捕捉了历史信息,并影响当前和未来的输出。
### 2.2 RNN核心模型的构建
#### 2.2.1 基本RNN单元的工作原理
基本RNN单元通过在时间维度上复制参数来处理不同时间步的输入,这个复制参数的设计允许网络存储和访问之前的序列信息。在每个时间步,单元将当前输入和前一个时间步的状态作为输入,通过权重矩阵将它们映射到输出。
#### 2.2.2 RNN单元在数学上的表达
用数学符号表达,RNN单元的计算如下:
```math
h_t = \phi(W \cdot [h_{t-1}, x_t])
```
这里的`[h_{t-1}, x_t]`是前一个隐藏状态和当前输入的拼接,`W`是权重矩阵,`φ`是作用在加权输入上的激活函数。
#### 2.2.3 长短期记忆网络(LSTM)和门控循环单元(GRU)
由于基本RNN单元容易受到梯度消失或爆炸的问题影响,研究者提出了LSTM和GRU两种RNN变体,以改善序列数据学习的效率和准确性。LSTM通过引入“门”的概念控制信息流,而GRU简化了这种门机制。
LSTM单元包括遗忘门、输入门和输出门,这些门决定了信息的保留和更新。GRU则融合了更新门和重置门,简化了LSTM的结构,同时保留了其处理长序列的能力。
### 2.3 RNN的变体与优化
#### 2.3.1 RNN常见的问题和限制
尽管RNN在处理序列数据上表现出色,但它也面临着一些固有问题,如梯度消失和梯度爆炸。这些问题导致RNN难以学习长距离的依赖关系,使得网络难以捕捉序列中的长期依赖信息。
#### 2.3.2 RNN变体的性能比较和选择
由于基本RNN存在局限性,多种变体被开发出来以应对不同的挑战。例如,LSTM和GRU是两种流行的变体,它们在保持长距离依赖学习能力的同时,简化了参数结构,提高了训练效率。
选择RNN变体时,需要考虑数据的特性、训练的复杂度以及所追求的性能指标。如果数据中的时间依赖性较长,建议使用LSTM或GRU。对于简单任务,基本RNN或其变体可能已经足够。
在下一章节,我们将深入探讨RNN的编程实现和训练技巧。
# 3. RNN编程实现与训练技巧
## 3.1 RNN的编程实践
### 3.1.1 使用Python和TensorFlow实现RNN
在这一节中,我们将通过实际的代码示例,展示如何使用Python和TensorFlow框架来实现RNN网络。TensorFlow是谷歌开发的开源机器学习库,提供了全面的工具来构建和部署机器学习模型。
首先,确保安装了TensorFlow库。在Python环境中,可以使用pip安装TensorFlow:
```python
pip install tensorflow
```
接下来,我们将构建一个基本的RNN模型。这里使用的是`tf.keras`模块,它是TensorFlow 2.x版本推荐的高级API,可以让模型构建过程更加直观和简洁。
```python
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# 定义序列长度、特征数量和输出类别数量
sequence_length = 10
feature_size = 5
output_size = 1
# 实例化一个序贯模型
model = Sequential()
# 添加一个RNN层,其中units参数为RNN单元的数量
model.add(SimpleRNN(units=32, input_shape=(sequence_length, feature_size)))
# 添加一个全连接层,输出大小为output_size
model.add(Dense(output_size, activation='sigmoid'))
# 编译模型,指定损失函数、优化器和评价指标
***pile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 模型摘要信息
model.summary()
```
在这个例子中,我们首先导入了必要的TensorFlow模块。随后创建了一个`Sequential`模型,并添加了一个`SimpleRNN`层,其中`u

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了循环神经网络(RNN)的基本原理,揭示了其处理序列数据的神秘面纱。从线性代数到概率论,专栏深入剖析了RNN的数学基础,并提供了构建精准预测模型的完整指南。专栏还深入探讨了RNN中梯度消失的挑战和解决方案,以及超参数调优和性能优化的技巧。此外,专栏还详细介绍了RNN的变体,如LSTM和GRU,以及它们在自然语言处理、语音识别、图像标注和深度学习中的应用。专栏还提供了代码实现指南、模型监控技巧和数据预处理策略,以帮助读者从理论到实践掌握RNN。最后,专栏探讨了RNN的可解释性、个性化推荐和金融数据分析等前沿应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
技术手册制作流程:如何打造完美的IT产品手册?
# 摘要
技术手册作为重要的技术沟通工具,在产品交付和使用过程中发挥着不可或缺的作用。本文系统性地探讨了技术手册撰写的重要性和作用,详述了撰写前期准备工作的细节,包括明确编写目的与受众分析、构建内容框架与风格指南、收集整理技术资料等。同时,本文进一步阐述了内容创作与管理的方法,包含文本内容的编写、图表和视觉元素的设计制作,以及版本控制与文档管理策略。在手册编辑与校对方面,本文强调了建立高效流程和标准、校对工作的方法与技巧以及互动反馈与持续改进的重要性。最后,本文分析了技术手册发布的渠道与格式选择、分发策略与用户培训,并对技术手册的未来趋势进行了展望,特别是数字化、智能化的发展以及技术更新对手册
掌握车载网络通信:ISO15765-3诊断工具的实战应用案例研究

# 摘要
本文综述了车载网络通信基础,深入探讨了ISO15765-3协议的架构、通信原理以及诊断服务功能。通过对ISO15765-3诊断工具的选择、配置、操作实践以及高级功能的详细分析,本文旨在提供一套完整的车载网络故障诊断解决方案。案例分析部分通过具体故障排查实例,展示了如何应用这些工具和策略来解决实际问题,并提出了优化建议。最后,本文展望了ISO15765-3诊断工具的未来发展
【Sysmac Studio调试高手】:NJ指令实时监控与故障排除技巧

# 摘要
Sysmac Studio中的NJ指令集是用于工业自动化领域的重要技术,它提供了高效、可靠的控制解决方案。本文全面介绍了NJ指令的概念、实时监控基础、故障排除技巧以及监控与故障排除的进阶方法。通过对NJ指令的工作原理、应用场景、与其他指令的比较、监控系统组件和数据处理流
数字逻辑电路设计:从理论到实践的突破性指导

# 摘要
本文系统地探讨了数字逻辑电路设计的理论基础和应用实践,涵盖了从基本逻辑门到复杂的时序逻辑电路设计的各个方面。文章首先介绍了数字逻辑电路设计的基础理论,包括数字逻辑门的功能与特性及其最小化和优化方法。随后,文章深入分析了组合逻辑电路和时序逻辑电路的构建、分析以及稳定性问题。文章还探讨了硬件描述语言(HDL)和数字电路仿真
【Deli得力DL-888B打印机终极指南】:从技术规格到维护技巧,打造专家级条码打印解决方案

# 摘要
本文对Deli得力DL-888B打印机进行全面的技术概览和深入理解,涵盖了硬件组件、打印技术原理以及所支持的条码和标签标准。文章详细介绍了安装、配置流程,包括硬件安装、软件与驱动安装以及网络连接设置。还探讨了高级应
【SQL Server查询优化】:高级技巧让你效率翻倍
# 摘要
本文对SQL Server查询优化的各个方面进行了系统阐述,包括查询优化的基础知识、执行计划的重要性及分析、索引机制以及慢查询的识别与优化。进一步,文章深入探讨了高级查询优化技术,如查询重写、存储过程优化以及查询提示的应用。实践中,通过电商交易系统和大数据分析两个案例,展示了查询优化策略的实际应用和效果。最后,本文介绍了性能监控
康耐视扫码枪数据通讯秘籍:三菱PLC响应优化技巧

# 摘要
本文详细探讨了康耐视扫码枪与三菱PLC之间数据通信的基础技术与实践应用,包括通讯协议的选择与配置、数据接口与信号流程分析以及数据包结构的封装和解析。随后,文章针对数据通讯故障的诊断与调试提供了方法,并深入分析了三菱PLC的响应时间优化策略,包括编程响应时间分析、硬件配置改进和系统级优化。通过实践案例分析与应用,提出了系统集成、部署以及维护与升级策略。最后,文章展
【APS系统常见问题解答】:故障速查手册与性能提升指南

# 摘要
本文全面概述了APS系统故障排查、性能优化、故障处理及维护管理的最佳实践。首先,介绍了故障排查的理论依据、工具和案例分析,为系统故障诊断提供了坚实的基础。随后,探讨了性能优化的评估指标、优化策略和监控工具的应用,
【SEMI-S2半导体制程设备安全入门】:初学者的快速指南
# 摘要
随着半导体产业的迅速发展,SEMI-S2半导体制程设备的安全性成为行业关注的焦点。本文系统性地介绍了SEMI-S2标准的理论基础、安全标准、操作规程、安全管理及持续改进方法,以及通过案例分析强调实际操作中的安全要求和事故预防。文章还展望了智能化与自动化在安全管理中的潜在应用,并探讨了未来安全技术的发展趋势。本文为
刷机升级指南:优博讯i6310B_HB版升级步骤详解与效率提升秘诀
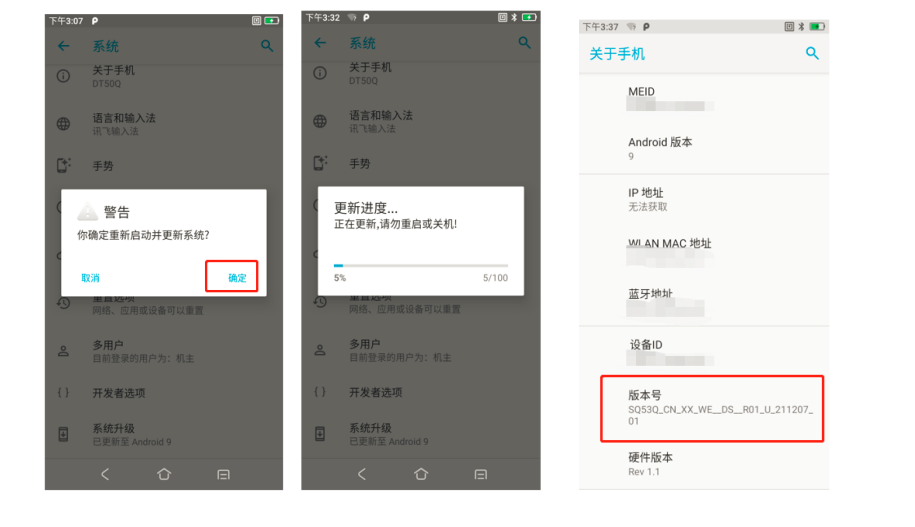
# 摘要
本文旨在为读者提供刷机升级的基础知识、详细步骤和效率提升技巧,以及刷机后可能出现的问题的诊断与解决方案。首先介绍了刷机的基础知识,接着详细讲解了优博讯i6310B_HB版固件的刷机步骤,包括刷机前的准备工作、操作流程详解和刷机后的系统配置。然后,文章提供了刷机效率提升的技巧,包括提高成功率、获取刷机工具与资源以及自动化刷机流程的实现。最后,文章探讨了刷机后可能遇到的问题及其解决方法,强调了系统稳定
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )