【Jupyter + Anaconda】:打造一站式数据分析与实验平台
发布时间: 2024-12-10 02:39:58 阅读量: 6 订阅数: 17 
# 1. Jupyter与Anaconda的简介及安装配置
## 1.1 Jupyter与Anaconda概述
Jupyter Notebook是基于Web的交互式数据分析和可视化工具,它支持多种编程语言,而Anaconda是一个开源的Python发行版本,专为数据科学设计,它包含了Jupyter Notebook、conda包管理器以及180多个科学包和环境。
## 1.2 安装Jupyter和Anaconda
首先,从[Anaconda官网](https://www.anaconda.com/products/individual)下载安装Anaconda。安装程序将自动安装Jupyter Notebook及Python解释器。安装完成后,在命令行中输入以下命令来启动Jupyter Notebook:
```bash
jupyter notebook
```
这将打开一个浏览器窗口,让您开始使用Jupyter Notebook的全新界面。
## 1.3 环境配置与管理
Anaconda环境允许用户创建多个隔离的环境来管理不同的项目依赖。使用conda命令可以创建、激活、删除和管理环境:
```bash
# 创建一个新的环境
conda create --name myenv python=3.8
# 激活环境
conda activate myenv
# 删除环境
conda remove --name myenv --all
```
这为数据科学工作者提供了灵活性和控制力,以确保不同项目之间的依赖性不会相互冲突。
这些简单的步骤将帮助您开始使用Jupyter和Anaconda,为深入的数据分析和项目开发打下基础。
# 2. Jupyter Notebook的数据分析基础
## 2.1 数据分析概念和工具
### 2.1.1 数据分析的定义与重要性
数据分析是现代企业决策制定的关键,其本质上是通过探索和解释数据来发现信息、得出结论并支持决策的过程。有效的数据分析能够帮助企业理解业务表现、市场趋势以及客户行为,从而在竞争激烈的市场中保持领先。数据分析的几个重要步骤包括数据收集、处理、分析、解释以及可视化。
在IT行业,数据分析尤其重要,因为数据的规模和复杂性往往更大,专业分析工具的需求更为迫切。高质量的数据分析可以优化业务流程,提高运营效率,并且能够帮助技术团队更好地理解产品使用情况、用户反馈以及市场动态。
### 2.1.2 Jupyter Notebook的特性与优势
Jupyter Notebook是一个开源Web应用程序,允许用户创建和共享包含代码、可视化和解释性文本的文档。这些文档被称为“notebooks”,能够支持多种编程语言,但最常用于Python。Notebook的特性使得数据分析工作变得更加直观和互动。
Jupyter Notebook的优势体现在以下几个方面:
- **交互式编程环境:**它提供了一个交互式的界面,用户可以即时运行代码片段,并立即看到结果。
- **多格式支持:**支持Markdown、HTML等多种格式,方便用户在分析报告中集成格式化文本、图片和数据图表。
- **易于分享和协作:**notebook可以通过各种平台分享,支持实时协作,非常适合团队项目和数据科学教育。
## 2.2 基本数据分析操作
### 2.2.1 Notebook的单元格操作
Jupyter Notebook由一个个单元格(cell)组成,每个单元格可以输入代码或者文本。单元格操作是使用Notebook的基础。
- **创建单元格:**在Notebook界面中,点击加号按钮或者按下`Alt + Enter`可以创建新单元格。
- **编辑单元格:**点击单元格后,会进入编辑模式,在此模式下可以输入代码或文本。
- **执行单元格:**选中单元格后,可以通过菜单栏的运行按钮或使用快捷键`Shift + Enter`执行单元格代码。
- **单元格类型:**单元格可以是代码(code)类型也可以是markdown文本(markdown)类型,通过点击单元格右上角的下拉菜单进行切换。
### 2.2.2 Python库在数据分析中的应用
在数据分析中,Python拥有丰富的第三方库,例如Pandas用于数据处理,NumPy用于科学计算,Matplotlib和Seaborn用于数据可视化。
以下是利用Pandas库进行数据分析的一个简单示例:
```python
import pandas as pd
# 创建一个简单的DataFrame作为数据集
df = pd.DataFrame({
'A': [1, 2, 3, 4],
'B': ['a', 'b', 'c', 'd']
})
# 查看数据集前五行
print(df.head())
# 基本的数据操作,如计算列的和
sum_A = df['A'].sum()
print(f"The sum of column A is: {sum_A}")
```
在这个示例中,我们首先导入了Pandas库,并创建了一个包含两列的DataFrame。然后我们使用`.head()`方法查看数据集的前五行,并用`.sum()`方法对列“A”进行求和。通过这样的操作,我们可以对数据集进行初步的探索和分析。
### 2.2.3 数据可视化工具集成
数据可视化是数据分析中不可或缺的一环,它通过图形的方式直观地展示数据,帮助我们更易理解数据背后的信息。Jupyter Notebook天然支持许多流行的Python可视化库。
```python
import matplotlib.pyplot as plt
# 生成一个简单的图表
plt.plot([1, 2, 3, 4], [1, 4, 9, 16])
plt.title('Simple Plot')
plt.xlabel('X Label')
plt.ylabel('Y Label')
plt.show()
```
上述代码块使用了`matplotlib`库绘制了一个简单的折线图。利用这些可视化工具有助于我们分析数据的趋势、模式和异常。
## 2.3 Notebook的高级功能
### 2.3.1 魔法命令的使用
Jupyter Notebook中的魔法命令以百分号`%`开头。这些命令为用户提供了一系列方便的功能,包括系统命令的执行和快速数据分析。
```python
# 列出所有魔法命令
%lsmagic
# 执行系统命令
%ls
# 运行Python代码的魔法命令
%%timeit
for i in range(100):
pass
```
在上面的例子中,`%lsmagic`用于列出所有可用的魔法命令。`%ls`执行了一个系统命令来列出当前目录下的文件。`%%timeit`是一个单元格魔法,用于测量代码执行的时间,是性能分析和优化的好工具。
### 2.3.2 数据清洗与预处理技巧
数据清洗是数据分析中不可或缺的一步,其目的在于处理缺失值、异常值、重复数据等,为后续分析打下坚实基础。
```python
# 处理缺失值
df['C'] = df['A'].apply(lambda x: x if x > 2 else None)
# 去除重复数据
df.drop_duplicates(inplace=True)
```
在这个例子中,我们使用`apply`方法根据条件判断填充缺失值,并用`drop_duplicates`方法去除DataFrame中的重复数据行。
### 2.3.3 数据分析案例实战
假设我们有一个零售商店的销售数据,需要通过数据分析来了解销售趋势、热销产品等信息。
```python
# 加载数据集
sales_data = pd.read_csv("sales_data.csv")
# 分析热销产品
top_products = sales_data.groupby("product_id").sum()["quantity_sold"]
top_products = top_products.sort_values(ascending
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏《Anaconda的代码示例与模板》为数据科学从业者提供了一系列全面的指南,涵盖了Anaconda在数据处理、环境同步、数据流处理、大数据处理、安全管理、性能优化、数据分析和数据可视化等方面的关键应用。通过深入浅出的讲解和丰富的代码示例,专栏旨在帮助读者掌握Anaconda的强大功能,提升数据科学技能,高效地解决实际问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘音频数据的神秘面纱:Sonic Visualiser深度应用与高级技巧
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. 音频数据解析与Sonic Visualiser简介
音频数据解析是数字信号处理领域的一个重要分支,涉
ST-Link V2 原理图解读:从入门到精通的6大技巧
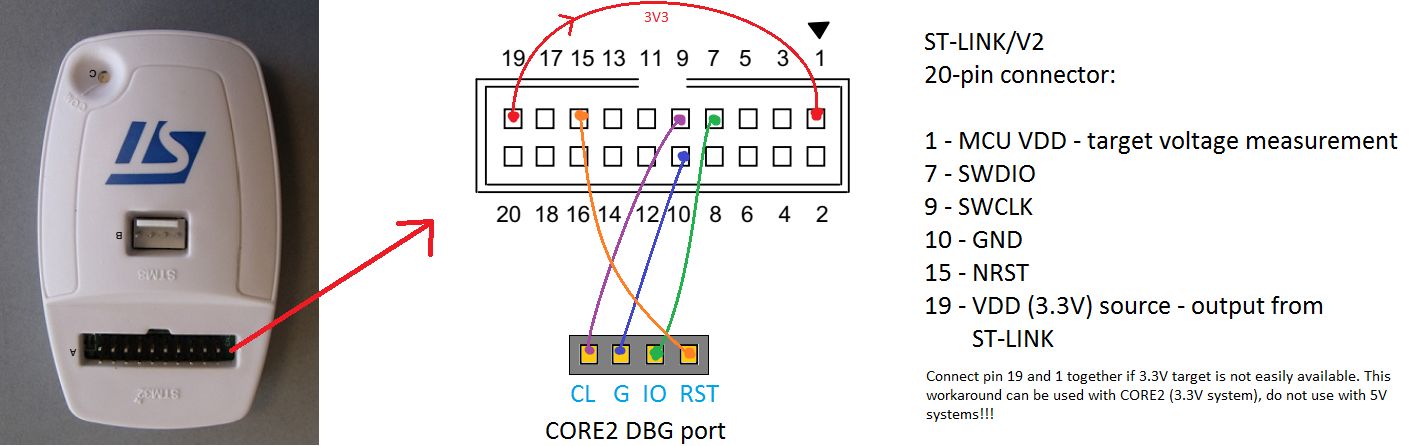
参考资源链接:[STLink V2原理图详解:构建STM32调试下载器](https://wenku.csdn.net/doc/646c5fd5d12cbe7ec3e52906?spm=1055.2635.3001.10343)
# 1. ST-Link V2简介与基础应用
ST-Link V2是一种广泛使用的调试器/编
Cognex VisionPro 标定流程优化攻略:8个秘诀帮你提升效率与准确性
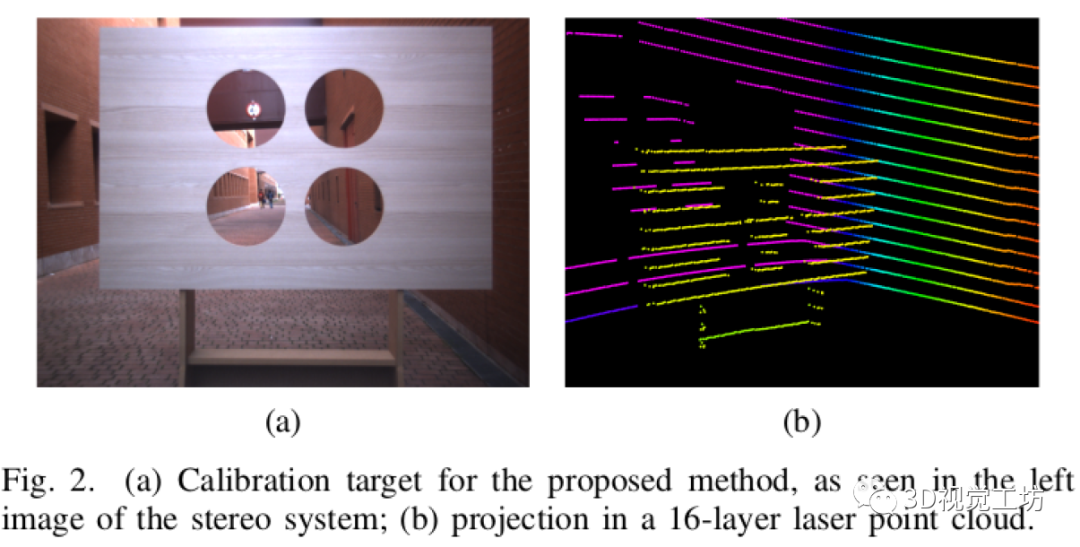
参考资源链接:[Cognex VisionPro视觉标定流程详解:从九点标定到旋转中心计算](https://wenku.csdn.net/doc/6401abe0cce7214c316e9d24?spm=1055.2635.3001.10343)
# 1. Cognex VisionPro 标定流程概述
在现代工业自动化和计算机视觉领域中,准确的标定是至关重要的,它确保了系统可以正确理
【IEC62055-41数据交换全解】:智能电表通信的STS单程通信分析

参考资源链接:[IEC62055-41标准传输规范(STS).单程令牌载波系统的应用层协议.doc](https://wenku.csdn.net/doc/6401ad0ecce7214c316ee1f8?spm=1055.2635.3001.10343)
# 1. IEC62055-41标准概述
## 1.1 IEC62055-41标准
【WPF摄像头应用性能优化】:MediaKit实践中的8个关键提升点
参考资源链接:[WPF使用MediaKit调用摄像头](https://wenku.csdn.net/doc/647d456b543f84448829bbfc?spm=1055.2635.3001.10343)
# 1. WPF摄像头应用性能优化概述
在当今数字时代,视频捕获和处理是许多软件应用的核心部分,尤其是对于WPF(Windows Presentation Foun
逼真3D效果的秘密:Geomagic Studio高级渲染技术
参考资源链接:[GeomagicStudio全方位操作教程:逆向工程与建模宝典](https://wenku.csdn.net/doc/6z60butf22?spm=1055.2635.3001.10343)
# 1. Geomagic Studio渲染技术概述
Geomagic Studio是一款被广泛使用的3D扫描和建模软件,其强大的渲
深度学习革新:NVIDIA Ampere架构的AI训练优化攻略

参考资源链接:[NVIDIA Ampere架构白皮书:A100 Tensor Core GPU详解与优势](https://wenku.csdn
用友U8备份策略灵活性:如何制定可扩展的备份计划
参考资源链接:[用友U8自动备份失效解决方案全攻略](https://wenku.csdn.net/doc/2h5qv6x3e0?spm=1055.2635.3001.10343)
# 1. 用友U8备份策略概述
在当今信息化时代,企业数据的完整性和安全性已经成为企业竞争力的重要组成部分。用友U8作为一款广泛应用于企业资源规划(ERP)的软件,其数据备份工作显得尤为重要。本章将从整体上对用友U
提升燃料电池仿真精度:ANSYS Fluent参数调整与案例分析
参考资源链接:[ANSYS_Fluent_15.0_燃料电池模块手册(en).pdf](https://wenku.csdn.net/doc/64619ad4543f844488937562?spm=1055.2635.3001.10343)
# 1. 燃料电池仿真概述
燃料电池作为清洁能源技术的核心设备之一,其性能与效率的提升对环境可持续
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )