MATLAB代码优化秘笈:10个技巧提升性能和可读性
发布时间: 2024-06-06 03:35:20 阅读量: 325 订阅数: 44 

数分1.11Tableau安装及使用教程

# 1. MATLAB代码优化基础**
MATLAB代码优化涉及提高代码性能和可读性的技术。性能优化通过减少执行时间和内存使用来提升代码效率,而可读性优化则通过清晰的命名约定、注释和组织结构来提高代码的可维护性。
MATLAB代码优化基础包括理解MATLAB语言的特性,例如矢量化、并行化和数据结构。矢量化可以避免使用循环,从而提高性能。并行化利用多核处理器来加速计算。选择合适的容器(如数组、结构体、单元格数组)和预分配内存可以优化数据结构,从而提高代码效率和可读性。
# 2. MATLAB代码性能优化技巧
### 2.1 矢量化和并行化
#### 2.1.1 矢量化:避免循环
**优化目标:**消除不必要的循环,提高代码效率。
**原理:**
MATLAB中的矢量化操作可以一次性对数组或矩阵中的所有元素进行操作,避免使用循环逐个元素处理。
**代码示例:**
```matlab
% 循环求和
sum = 0;
for i = 1:100000
sum = sum + i;
end
% 矢量化求和
sum = sum(1:100000);
```
**逻辑分析:**
循环版本需要执行100000次加法操作,而矢量化版本只需一次操作即可完成。
#### 2.1.2 并行化:利用多核处理器
**优化目标:**充分利用多核处理器,提高计算速度。
**原理:**
MATLAB支持并行计算,允许将任务分配到多个处理器内核同时执行。
**代码示例:**
```matlab
% 创建并行池
parpool;
% 并行求和
sum = parsum(1:100000);
% 关闭并行池
delete(gcp);
```
**逻辑分析:**
`parsum`函数利用并行池中的多个内核同时计算和,显著提高计算速度。
### 2.2 数据结构优化
#### 2.2.1 选择合适的容器
**优化目标:**根据数据类型和访问模式选择合适的容器,优化内存使用和性能。
**原理:**
MATLAB提供多种数据容器,如数组、结构体、单元格数组和哈希表。选择合适的容器可以减少内存开销和提高访问效率。
**代码示例:**
```matlab
% 存储字符串数组
data = {'a', 'b', 'c', 'd', 'e'};
% 使用单元格数组
cell_data = cellstr(data);
% 使用字符串数组
string_data = string(data);
```
**逻辑分析:**
单元格数组适合存储异构数据,而字符串数组更适合存储同质字符串数据,后者具有更高的内存效率和访问速度。
#### 2.2.2 预分配内存
**优化目标:**预先分配内存空间,避免多次内存分配和释放,提高性能。
**原理:**
MATLAB在创建数组或矩阵时会动态分配内存。预分配内存可以防止内存碎片化,提高分配效率。
**代码示例:**
```matlab
% 预分配内存
A = zeros(1000, 1000);
% 逐行分配内存
for i = 1:1000
A(i, :) = zeros(1, 1000);
end
```
**逻辑分析:**
预分配内存版本只进行一次内存分配,而逐行分配版本需要进行1000次内存分配,显著降低性能。
### 2.3 算法优化
#### 2.3.1 使用高效算法
**优化目标:**选择最合适的算法,减少计算复杂度,提高效率。
**原理:**
MATLAB提供多种算法,如排序、搜索、数值积分等。选择最合适的算法可以显著降低计算时间。
**代码示例:**
```matlab
% 冒泡排序
for i = 1:n
for j = 1:n-i
if A(j) > A(j+1)
temp = A(j);
A(j) = A(j+1);
A(j+1) = temp;
end
end
end
% 快速排序
[~, idx] = sort(A);
A = A(idx);
```
**逻辑分析:**
快速排序算法比冒泡排序算法效率更高,复杂度为O(n log n),而冒泡排序算法复杂度为O(n^2)。
#### 2.3.2 避免不必要的计算
**优化目标:**消除重复或不必要的计算,提高效率。
**原理:**
通过分析代码逻辑,可以识别出不必要的计算,并将其消除或优化。
**代码示例:**
```matlab
% 计算平方
for i = 1:1000
result(i) = sqrt(i^2);
end
% 优化后
result = i.^2;
```
**逻辑分析:**
计算平方根是一个耗时的操作。优化后的代码直接计算平方,避免了不必要的平方根计算。
# 3. MATLAB代码可读性优化技巧
### 3.1 命名约定和注释
#### 3.1.1 使用有意义的变量名
变量名是MATLAB代码中标识变量的标签。使用有意义的变量名可以提高代码的可读性,让其他程序员和你自己更容易理解代码的目的和用途。
**示例:**
```matlab
% 不佳的变量名
x = 10;
y = 20;
% 更好的变量名
width = 10;
height = 20;
```
#### 3.1.2 编写详细的注释
注释是添加到代码中的说明,用于解释代码的目的、算法或任何其他相关信息。详细的注释可以帮助其他程序员和你自己在以后理解代码。
**示例:**
```matlab
% 计算矩形面积
area = width * height;
% 注释解释了计算面积的目的
% 计算矩形面积
% width: 矩形的宽度
% height: 矩形的高度
area = width * height;
```
### 3.2 代码组织和结构
#### 3.2.1 使用模块化设计
模块化设计将代码分解为较小的、可重用的模块。这使得代码更容易组织和维护,并且可以促进团队协作。
**示例:**
```matlab
% 创建一个计算矩形面积的函数
function area = calculateArea(width, height)
area = width * height;
end
% 在主脚本中调用函数
width = 10;
height = 20;
area = calculateArea(width, height);
```
#### 3.2.2 遵循代码规范
遵循代码规范有助于确保代码的一致性和可读性。MATLAB提供了自己的代码规范,称为MATLAB编码约定。遵循这些约定可以使你的代码更易于其他程序员理解和维护。
**示例:**
* 使用缩进和空白来组织代码块。
* 使用一致的命名约定(例如,小写字母和下划线)。
* 避免使用冗长的行和复杂的表达式。
### 3.3 错误处理和调试
#### 3.3.1 编写健壮的错误处理代码
健壮的错误处理代码可以防止代码在遇到意外情况时崩溃。这可以通过使用`try-catch`块来实现,该块捕获错误并执行恢复操作。
**示例:**
```matlab
try
% 尝试执行可能引发错误的操作
catch err
% 如果发生错误,捕获错误并执行恢复操作
disp(err.message);
end
```
#### 3.3.2 使用调试工具
MATLAB提供了各种调试工具,可以帮助你识别和解决代码中的错误。这些工具包括:
* **调试器:**允许你逐行执行代码并检查变量的值。
* **断点:**允许你在代码的特定位置暂停执行。
* **错误消息:**提供有关错误原因的详细信息。
# 4. MATLAB代码高级优化技巧
### 4.1 代码生成和编译
#### 4.1.1 使用代码生成器
MATLAB代码生成器允许您将MATLAB代码转换为其他编程语言,例如C/C++或Java。这可以显著提高代码性能,特别是在涉及大量数值计算或循环的情况下。
**代码示例:**
```
% 生成C代码
codegen -language C my_function.m
```
**逻辑分析:**
* `codegen` 命令用于生成C代码。
* `-language` 选项指定目标语言。
* `my_function.m` 是要转换的MATLAB文件。
#### 4.1.2 编译MATLAB代码
MATLAB编译器可以将MATLAB代码编译为机器代码,从而提高执行速度。编译后的代码比解释执行的代码快得多。
**代码示例:**
```
% 编译MATLAB代码
mcc -m my_function.m
```
**逻辑分析:**
* `mcc` 命令用于编译MATLAB代码。
* `-m` 选项指定编译为可执行文件。
* `my_function.m` 是要编译的MATLAB文件。
### 4.2 GPU编程
#### 4.2.1 了解GPU架构
图形处理单元(GPU)是专门设计用于处理大量并行计算的硬件。GPU具有大量的流处理器,可以同时执行多个线程。
**GPU架构图:**
```mermaid
graph LR
subgraph CPU
A[CPU]
B[RAM]
C[Cache]
end
subgraph GPU
D[GPU Memory]
E[Streaming Processors]
F[Shared Memory]
end
A --> B
B --> C
C --> E
E --> F
D --> E
```
**说明:**
* CPU由一个或多个内核组成,每个内核一次只能执行一个线程。
* GPU由大量的流处理器组成,可以同时执行多个线程。
* GPU内存与CPU内存分离,需要通过PCIe总线进行数据传输。
#### 4.2.2 编写GPU代码
MATLAB提供了称为Parallel Computing Toolbox的工具箱,用于编写GPU代码。该工具箱提供了用于数据并行化和GPU管理的函数。
**代码示例:**
```
% 创建GPU数组
gpuArray = gpuArray(data);
% 在GPU上执行计算
result = gpuArray * gpuArray;
% 将结果复制回CPU
result = gather(result);
```
**逻辑分析:**
* `gpuArray` 函数用于创建GPU数组。
* 在GPU上执行计算。
* `gather` 函数用于将结果复制回CPU。
# 5.1 性能分析和基准测试
### 5.1.1 使用性能分析工具
MATLAB 提供了多种工具来分析代码性能,包括:
- **MATLAB Profiler:**可生成报告,显示代码中函数调用的时间和内存使用情况。
- **tic 和 toc:**用于测量代码块的执行时间。
- **timeit:**用于重复执行代码块并测量平均执行时间。
```
% 使用 Profiler 分析代码性能
profile on;
% 执行要分析的代码
profile viewer;
```
### 5.1.2 进行基准测试
基准测试是比较不同代码实现或优化技术的性能的一种方法。以下是进行基准测试的步骤:
1. **定义基准:**确定要测量的性能指标,例如执行时间、内存使用或吞吐量。
2. **创建测试用例:**设计代表性测试用例,涵盖各种输入和场景。
3. **执行测试:**在受控环境中运行测试用例,并记录结果。
4. **分析结果:**比较不同实现的性能,并确定最佳选项。
```
% 基准测试不同排序算法
algorithms = {'BubbleSort', 'InsertionSort', 'MergeSort', 'QuickSort'};
dataSizes = [1000, 5000, 10000, 50000, 100000];
results = zeros(length(algorithms), length(dataSizes));
for i = 1:length(algorithms)
for j = 1:length(dataSizes)
data = rand(dataSizes(j), 1);
tic;
eval([algorithms{i}, '(data);']);
results(i, j) = toc;
end
end
% 绘制基准测试结果
figure;
plot(dataSizes, results, 'LineWidth', 2);
legend(algorithms, 'Location', 'best');
xlabel('Data Size');
ylabel('Execution Time (seconds)');
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“MATLAB 或”是一份全面的指南,涵盖了 MATLAB 的各个方面。它提供了从基础到高级的图像处理技术,优化代码性能的技巧,利用多核优势的并行编程,以及从预处理到可视化的数据分析策略。专栏还深入探讨了机器学习、图像分割、特征提取、信号处理、数值计算、GUI 编程、符号计算、数据结构、面向对象编程、数据可视化、云计算、生物信息学、控制系统设计、仿真和建模等主题。通过深入浅出的讲解和丰富的代码示例,该专栏旨在帮助读者充分利用 MATLAB 的强大功能,解决各种复杂问题并获得令人惊叹的视觉效果。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
双闭环直流电机调速:电机类型选择的不传之秘

# 摘要
直流电机在工业领域内广泛应用,其工作原理和分类是电机控制系统设计的基础。本文首先介绍了直流电机的基本工作原理及其分类,然后详细探讨了双闭环直流电机调速系统的结构和关键性能指标。文章深入分析了不同类型直流电机的特性,并提供了电机类型选择的理论计算方法。实践应用方面,本文讨论了工业场景下的电机选型和调速系统设计的综合考量。最后,文章通过案例研究展示了双闭环调速系统的实现、优化以及在工业自动化中
组播路由协议深度探讨:网络中的部署与案例分析

# 摘要
本文全面探讨了组播路由协议的各个方面,包括其理论基础、实践部署、案例分析以及未来发展趋势。首先概述了组播路由协议的重要性及其在组播通信模型中的应用。接着,深入分析了不同类型的组播路由协议,并讨论了组播路由的基本原理和数据包转发机制。在实践部署章节中,本文详细介绍了环境搭建、配置步骤、监控管理以及安全性与性能优化的方法。案例分析部分通过行业应用案例解析和部署挑战的探讨,展现了组播路由在
云原生合规性黄金法则:行业标准与法规的满足秘籍
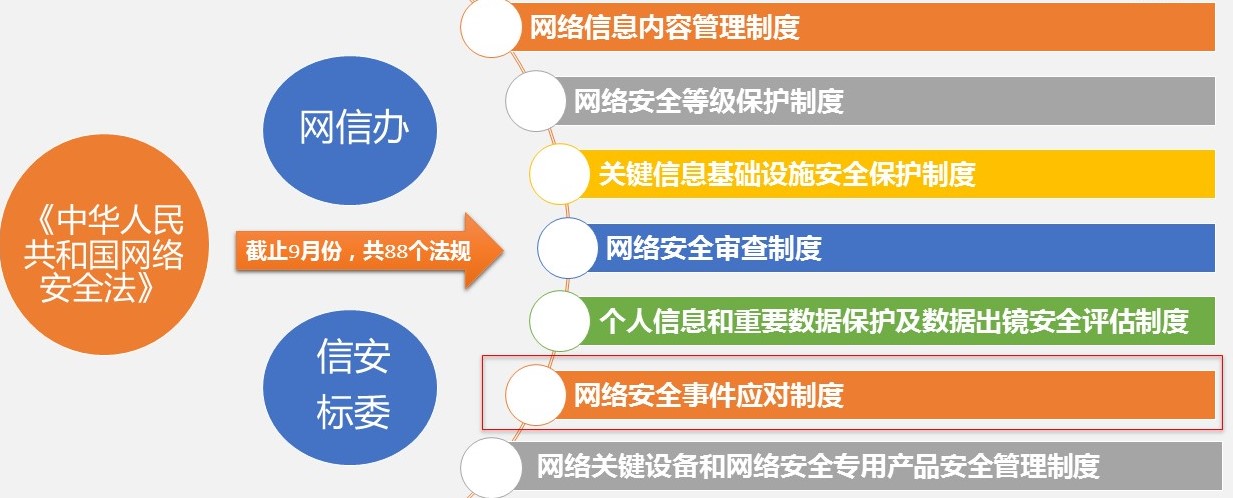
# 摘要
本文系统地探讨了云原生合规性的核心概念,分析了行业标准与法规对企业和组织合规性的重要性。重点介绍了ISO/IEC 27001、SOC 2、GDPR等主要云服务合规标准,并讨论了合规性政策制定、风险评估、员工培训等实施策略。文章进一步阐述了技术实现层面的安全架构设计、监控日志管理、应急响应等关键实践,以及合规性实施的成功案例分析。最后,文章展望了云原生合规性的未来趋势,包括新兴法规适应及技术创新在合规性中的潜在应用。
深入解析CMOS传感器:如何最大化1_4英寸的30万像素潜力
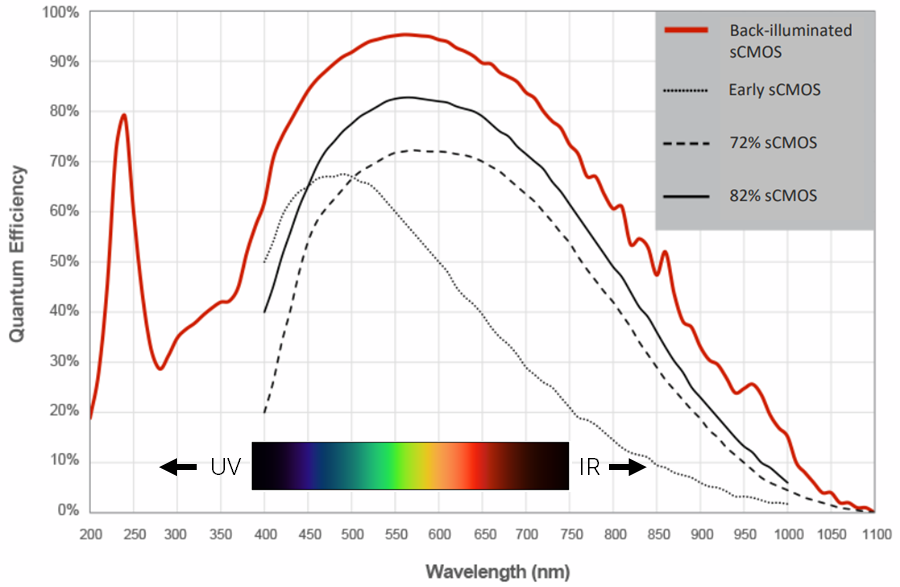
# 摘要
本文全面探讨了CMOS传感器的基础知识、技术参数、图像质量影响因素以及在不同场景下的应用,并分析了30万像素CMOS传感器的潜力挖掘与优化策略。通过对传感器尺寸、读出噪声、色彩还原等关键技术参数的解析,结合低光环境、高速成像等特定应用领域的分析,本文深入讨论了如何通过技术手段提升图像质量。此外,本文还展望了CMOS传感器技术的发展趋势,包括新型像素设计、智能化融合以及绿色节能技
【Python日期处理:进阶挑战】:自定义函数,精确计算年日
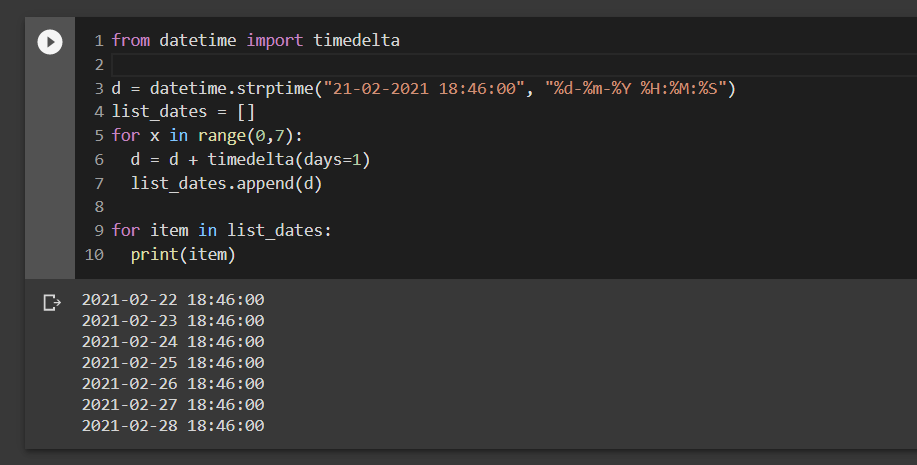
# 摘要
Python是一种广泛使用的编程语言,尤其在日期和时间处理方面提供了强大的库支持。本文首先概述了Python在日期处理方面的基本概念,随后深入讲解了datetime模块的使用,包括日期时间对象的创建和操作,时间的格式化与解析,以及时区的处理。文章第三部分探讨了编写自定义日期处理函数时面临的挑战,并介绍了相关的设计思路和算法选择。第四章着重于提高日期处理精确度的策略,包括理解
欧陆590直流调速器长寿秘诀:维护保养与延长设备寿命的黄金法则

# 摘要
本文首先概述了欧陆590直流调速器的基本情况,然后深入分析了其工作原理、结构与功能以及维护要点。在直流调速器的使用与维护策略方面,文中详细探讨了如何通过正确操作、预防性维护以及环境与电气因素的考量来延长设备的使用寿命。故障诊断与解决技巧章节提供了一系列故障分析、排除步骤和修复方法。最后,文章通过案例研究与行业应用,展示了欧陆590在不同领域的应用情况,分析了设备
商品上架自动化革新:淘宝天猫秒级库存同步技术内幕

# 摘要
随着电子商务的迅速发展,商品上架自动化成为提高效率和响应速度的关键技术革新。本文首先概述了商品上架自动化的基本概念与重要性,随后深入分析了秒级库存同步技术的原理和实践。详细阐述了实现该技术所需的数据抓取、数据同步流程自动化以及实时监控与报警系统的技术细节。通过淘宝天猫
GSM网络创新引擎:TDMA超帧演进的10年回顾与前瞻
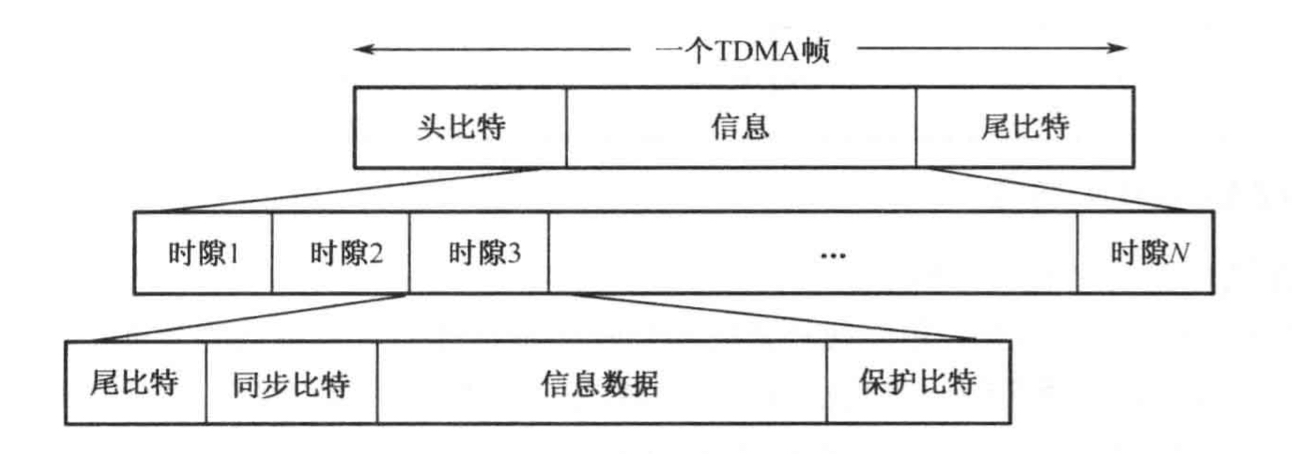
# 摘要
本文概述了GSM网络和TDMA技术的发展历程及其超帧结构的演进。文章详细介绍了TDMA超帧的起源、主要变化及其对网络性能的影响,探讨了在技术创新与实践中的无线接口技术、网络架构优化以及无线资源管理的改进。同时,本文也针对网络安全问题、新兴技术融合以及网络覆盖与服务升级方面的挑战提出了应对策略。最后,文章展望了TDM
SX-DSV03244_R5_0C通信参数故障排查:从新手到高手
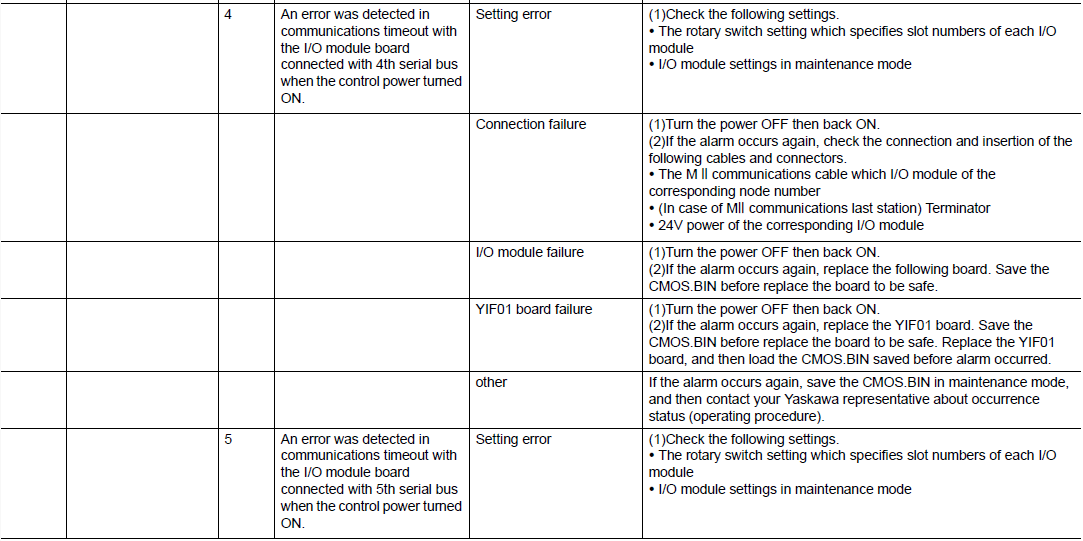
# 摘要
本文旨在深入探讨SX-DSV03244_R5_0C型号通信设备的参数故障排查技术。第一章提供该通信参数的概述,第二章分析通信参数功能的重要性及故障诊断的基础理论。第三章通过实践技巧,介绍了使用测试设备和仿真软件进行故障排查的方法。第四章进一步讨论通信参数设置的影响、高级故障诊断技术和维护策略。第五章探讨故障排查的自动化与智能化路径,展示自动化测试工具和智能故障诊断系统的应用。
Unicode编码国际化与本地化:策略与执行细节

# 摘要
本文全面探讨了Unicode编码的基础知识、国际化策略的理论以及本地化的实际技巧,并进一步分析了Unicode编码在软件中的应用和面对的挑战。首先介绍了字符编码的历史发展和Unicode标准,强调了国际化的需求以及设计原则。随后,本文阐述了本地化过程中的关键实践,包括文本翻译、资源管理以及测试和验证。接着,文章深入探讨了Unicode编码在编程语言实现、用户界面设计以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )