【Python简单json终极指南】:一步到位掌握高效数据处理秘诀
发布时间: 2024-10-10 08:33:09 阅读量: 136 订阅数: 35 

Python中的JSON处理:解析与生成全面指南
# 1. JSON基础与Python的关联
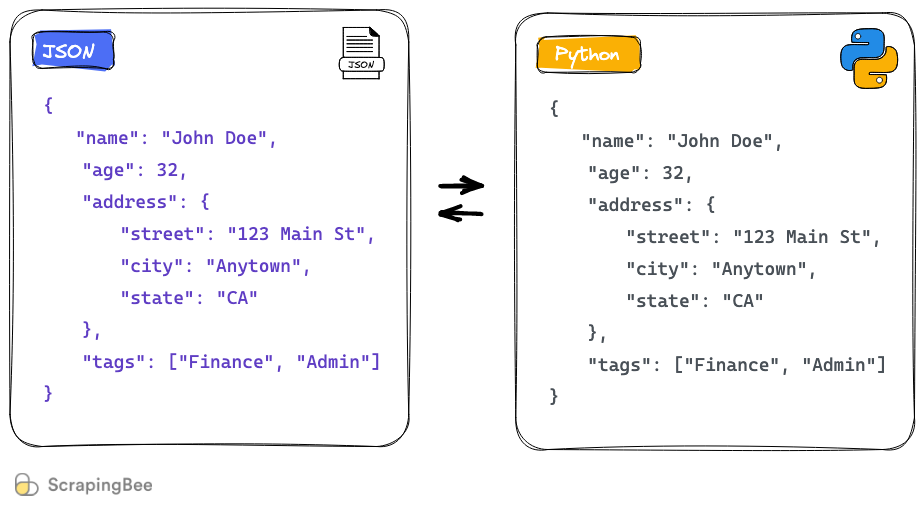
在现代的网络世界中,JSON(JavaScript Object Notation)已成为一种轻量级的数据交换格式。由于其轻便性,JSON被广泛地用于Web应用和API通信中。Python,作为一门高级编程语言,提供了强大的标准库来处理JSON数据,其`json`模块是操作JSON数据的官方推荐方式。
JSON的基本组成单元是值,这些值可以是字符串、数字、布尔值、数组、对象或者null。而Python中的JSON处理主要是通过将JSON格式的数据解析为Python的数据类型(如字典和列表),或者将Python对象转换成JSON格式的字符串来实现。
接下来的章节将详细介绍如何在Python中使用`json`模块进行JSON数据的解析与生成,以及一些高级操作和实践案例,最后探讨如何优化JSON处理以及未来的发展趋势。
```python
import json
# 示例:将JSON字符串解析为Python对象
json_str = '{"name": "John", "age": 30, "city": "New York"}'
python_obj = json.loads(json_str)
print(python_obj) # 输出: {'name': 'John', 'age': 30, 'city': 'New York'}
# 示例:将Python对象转换为JSON字符串
python_obj = {
"name": "John",
"age": 30,
"city": "New York",
"is_member": True,
}
json_str = json.dumps(python_obj)
print(json_str) # 输出: {"name": "John", "age": 30, "city": "New York", "is_member": true}
```
在这个过程中,Python的`json`模块为开发者提供了一套简洁的API,使得JSON数据的处理变得简单和直观。
# 2. Python中JSON数据的解析与生成
## 2.1 Python的json模块解析
### 2.1.1 json模块的基本使用方法
在Python中,处理JSON数据通常使用内置的`json`模块。Python的`json`模块提供了一种简单的方法来编码和解码JSON数据。基本使用方法包括将JSON格式的字符串转换为Python的数据类型(如列表、字典),或者将Python的数据类型转换为JSON格式的字符串。
首先,使用`json.loads()`方法可以将JSON格式的字符串解析为Python的数据结构:
```python
import json
json_string = '{"name": "John", "age": 30, "city": "New York"}'
python_object = json.loads(json_string)
print(python_object)
```
该代码会输出一个Python字典:
```python
{'name': 'John', 'age': 30, 'city': 'New York'}
```
其次,使用`json.dumps()`方法可以将Python对象转换回JSON格式的字符串:
```python
json_string = json.dumps(python_object)
print(json_string)
```
输出:
```python
{"name": "John", "age": 30, "city": "New York"}
```
### 2.1.2 解析JSON数据为Python对象
解析JSON数据通常涉及读取JSON格式的字符串,并将其转换为Python的内建数据类型,比如字典或列表。`json.loads()`方法非常适合处理存储在字符串或文件中的小型JSON数据。对于大型JSON文件,可能需要一种不同的方法。
下面是一个将JSON字符串解析为Python对象的示例代码:
```python
import json
json_data = '{"name": "Alice", "hobbies": ["reading", "swimming", "cycling"]}'
python_data = json.loads(json_data)
print(python_data['name']) # Alice
print(python_data['hobbies']) # ['reading', 'swimming', 'cycling']
```
在上述代码中,JSON数据被转换为一个Python字典,我们可以通过字典的键来访问数据项。这种方式非常适用于小型数据集,但在处理大型文件时,应考虑性能和内存使用效率。
## 2.2 JSON与Python数据结构的转换
### 2.2.1 将Python对象转换为JSON字符串
将Python数据结构转换为JSON字符串时,通常使用`json.dumps()`方法。此方法能够处理Python的字典、列表、元组、字符串、整数、浮点数等数据类型,并将它们转换为JSON格式的字符串。
这是一个将Python字典转换为JSON字符串的示例:
```python
import json
python_data = {
"name": "Bob",
"age": 25,
"city": "Los Angeles"
}
json_string = json.dumps(python_data)
print(json_string)
```
输出:
```json
{"name": "Bob", "age": 25, "city": "Los Angeles"}
```
### 2.2.2 理解编码和解码过程中的注意事项
在编码(转换为JSON字符串)和解码(将JSON字符串转换为Python对象)的过程中,需要注意几个重要方面:
- **字符编码**:默认情况下,`json.dumps()`和`json.loads()`会以UTF-8编码进行转换。如果处理的JSON数据中包含非ASCII字符,应确保编码一致,避免数据损坏。
- **浮点数精度**:在将浮点数编码为JSON时,可能会有精度上的损失。JSON格式的浮点数精度通常小于Python浮点数的精度。
- **对象序列化**:`json.dumps()`方法不能直接处理包含自定义对象的Python字典,因为JSON格式仅支持基本数据类型。要序列化自定义对象,需要实现一个方法来将对象转换为字典或JSON兼容的格式。
- **日期和时间**:JSON标准没有定义日期和时间格式,因此需要将日期和时间转换为字符串或ISO格式的字符串,才能被正确编码为JSON。
## 2.3 高级JSON解析技术
### 2.3.1 处理大型JSON文件的策略
处理大型JSON文件时,可以采用一些策略来提高性能和效率:
- **逐行解析**:对于非常大的文件,可以使用`json.JSONDecoder`来逐行解析JSON数据。这种方法可以避免将整个文件加载到内存中。
- **使用生成器**:通过定义生成器函数来逐步处理数据,例如,逐个处理JSON文件中的对象,可以显著降低内存使用量。
- **文件流处理**:在读取文件时,可以使用文件流来逐个读取数据块,配合`json.JSONDecoder`的`raw_decode`方法来逐块解析,避免一次性读取整个文件。
这里提供一个使用生成器来逐个处理JSON对象的示例:
```python
import json
def process_json_large_file(file_path):
with open(file_path, 'r', encoding='utf-8') as ***
***
***
*** 读取4KB大小的数据块
if not chunk:
break
result, index = decoder.raw_decode(chunk)
yield result
for json_obj in process_json_large_file('large_file.json'):
# 处理每个json对象
print(json_obj)
```
### 2.3.2 使用json模块进行异步解析
在某些应用中,尤其是在需要处理多个并发任务的场景下,异步处理可以显著提高性能。Python的`aiojson`是一个用于异步IO操作的JSON处理库,它提供了与`json`模块相似的接口,但可以与异步框架(如`asyncio`)配合使用。
下面是一个简单的使用`aiojson`进行异步JSON解析的示例:
```python
import asyncio
import aiojson
async def load_json_data(data):
# 异步加载数据
json_data = await aiojson.loads(data)
return json_data
async def main():
json_str = '{"name": "Charlie", "age": 45}'
json_obj = await load_json_data(json_str)
print(json_obj)
# 启动事件循环并执行
asyncio.run(main())
```
需要注意的是,使用异步库时,代码的执行方式和传统同步代码不同,因此需要对异步编程有一定了解,才能有效利用其性能优势。
在本章节中,我们讨论了Python中如何使用`json`模块来解析和生成JSON数据。首先了解了`json`模块的基本使用方法,包括将JSON字符串转换为Python对象,以及将Python对象转换为JSON字符串。接着,我们探讨了如何在编码和解码过程中注意编码和解码的注意事项,包括字符编码、浮点数精度以及处理自定义对象时的方法。最后,我们讨论了处理大型JSON文件的策略和使用异步解析技术。在下一章节中,我们将深入探讨Python中JSON数据的高级操作,如数据验证、美化打印以及构建自动化工具。
# 3. Python中JSON数据的高级操作
## 3.1 JSON数据的有效性验证
在处理JSON数据时,验证其结构和内容的有效性是关键步骤。这有助于确保数据的准确性和完整性,并可以防止错误或不一致的数据对应用程序造成影响。
### 3.1.1 JSON模式验证
JSON模式(JSON Schema)是一种描述JSON数据结构的语言,它允许你定义JSON数据应遵循的规则。通过使用模式验证,开发者可以确保接收到的数据符合预期格式。
为了在Python中实现JSON模式验证,可以使用`jsonschema`库。以下是一个如何定义和使用JSON模式的例子:
```python
from jsonschema import validate
from jsonschema.exceptions import ValidationError
# 定义一个JSON模式
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "number"},
"email": {"type": "string", "format": "email"}
},
"required": ["name", "age"]
}
# 待验证的JSON数据
data = {
"name": "John Doe",
"age": 30,
"email": "john.***"
}
# 执行验证
try:
validate(instance=data, schema=schema)
print("数据验证通过")
except ValidationError as e:
print("数据验证失败:", e)
```
### 3.1.2 使用第三方库进行数据校验
`jsonschema`库提供了灵活的方式来验证JSON数据是否符合特定的模式。此过程对于数据输入处理非常关键,它能够帮助开发者确保数据格式的正确性,并提供友好的错误信息反馈。
验证流程可以分为以下步骤:
1. 定义JSON模式,该模式描述了期望的数据结构和类型。
2. 使用`validate`函数将实际的数据实例与模式对比。
3. 捕获并处理可能出现的`ValidationError`,以确保程序能够正确响应验证失败的情况。
这个过程不仅有助于提前发现数据问题,还能提高应用的稳定性和可靠性。使用第三方库的好处在于,它减少了手动编写验证逻辑的复杂性,同时提供了丰富的错误处理能力。
## 3.2 JSON数据的美化与压缩
### 3.2.1 JSON数据的美化打印
为了提高JSON数据的可读性,通常需要对其进行美化打印。Python提供了多种方式来格式化JSON数据,以便于查看和调试。
使用Python内置的`json`模块可以轻松实现JSON的美化打印:
```python
import json
# 原始JSON数据
data = '{"name": "John Doe", "age": 30, "email": "john.***"}'
# 美化打印
formatted_data = json.dumps(json.loads(data), indent=4)
print(formatted_data)
```
输出结果将会是一个缩进为4个空格的格式化JSON字符串,使得数据结构一目了然。
### 3.2.2 JSON数据的压缩方法
虽然美化打印有助于阅读和调试,但在网络传输或存储时,通常需要将JSON数据压缩以节省空间和带宽。压缩后的数据可以使用各种算法,如gzip,进行压缩和解压缩。
以下是如何在Python中使用`gzip`模块对JSON数据进行压缩和解压缩的例子:
```python
import gzip
import json
# 原始JSON数据
data = '{"name": "John Doe", "age": 30, "email": "john.***"}'
# 将数据压缩
with gzip.open('data.json.gz', 'wt', encoding='utf-8') as f:
f.write(data)
# 从压缩文件中解压数据
with gzip.open('data.json.gz', 'rt', encoding='utf-8') as f:
decompressed_data = f.read()
```
通过压缩,JSON文件大小将显著减少,从而提高数据处理和传输的效率。需要注意的是,在网络传输压缩数据时,接收端需要具备相应的解压缩能力。
## 3.3 构建与JSON相关的自动化工具
### 3.3.1 一个简单的数据导出工具
在数据处理和分析中,将数据从一种格式导出为JSON格式是一种常见的需求。通过编写自动化工具,可以简化数据导出过程,提高效率。
以下是一个简单的Python脚本,它将CSV数据导出为JSON格式:
```python
import csv
import json
# 从CSV读取数据
with open('data.csv', 'r') as csv_***
***
***
* 将数据转换为JSON格式
with open('data.json', 'w') as json_***
***
```
### 3.3.2 一个简单的数据导入工具
导入JSON数据到数据库或应用中也是数据处理的重要环节。实现一个简单的数据导入工具,可以自动化这一过程。
以下是如何将JSON数据导入到SQLite数据库的例子:
```python
import sqlite3
import json
# 连接到SQLite数据库
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''CREATE TABLE IF NOT EXISTS users
(name TEXT, age INTEGER, email TEXT)''')
# 读取JSON文件
with open('data.json', 'r') as json_***
***
* 将数据导入到数据库中
for item in data:
cursor.execute('INSERT INTO users VALUES (?, ?, ?)',
(item['name'], item['age'], item['email']))
# 提交事务并关闭连接
***mit()
conn.close()
```
这两个自动化工具的例子展示了如何通过Python脚本处理JSON数据的导出和导入操作,提高了数据处理的效率和准确性。
# 4. Python中JSON的实践应用案例
在IT行业,特别是在Web开发和网络服务中,JSON数据格式广泛用于数据交换。Python作为一种多用途的编程语言,凭借其简洁的语法和强大的标准库,在处理JSON数据方面表现得尤为出色。本章节将深入探讨如何将JSON与Python结合,通过具体的实践应用案例来展示其在现实世界问题解决中的应用。
## 4.1 构建一个RESTful API客户端
### 4.1.1 从JSON数据源获取信息
RESTful API是现代Web开发中广泛采用的一种架构风格,而JSON是这类API最常见的数据交换格式。在本小节中,我们将介绍如何使用Python构建一个简单的RESTful API客户端,演示如何从一个JSON数据源获取信息。
首先,我们需要使用`requests`库来发送HTTP请求并接收JSON格式的响应数据。这是一个示例代码块,展示如何获取远程API的数据:
```python
import requests
import json
def get_api_data(url):
try:
response = requests.get(url)
response.raise_for_status() # 确保我们注意到任何错误
return response.json() # 直接转换为Python对象
except requests.HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'Other error occurred: {err}')
api_url = '***'
data = get_api_data(api_url)
print(json.dumps(data, indent=4)) # 美化打印JSON数据
```
在上述代码中,我们定义了一个`get_api_data`函数,它接受一个URL参数,并返回从该URL获取的JSON数据。我们使用`requests.get`发送一个GET请求,并在请求中包含了一个异常处理块,以处理可能发生的HTTP错误和其他异常。
### 4.1.2 使用JSON数据进行应用逻辑处理
获取JSON数据后,通常需要执行一些应用逻辑。在这一小节,我们将讨论如何处理这些数据,并演示如何将其应用到业务逻辑中。
```python
def process_data(data):
# 假设响应数据是一个包含字典的列表
if isinstance(data, list):
for item in data:
process_item(item) # 处理每一项数据
else:
print("Received data is not in list form.")
def process_item(item):
# 进行一些数据处理
if 'key' in item and item['key'] == 'value':
print("Item with specific key found.")
else:
print("Processing item...")
# 假设我们已经得到了JSON数据
data = get_api_data(api_url)
if data:
process_data(data)
```
在上述代码中,`process_data`函数检查获取的JSON数据是否是列表格式,如果是,它会遍历列表中的每个元素并调用`process_item`函数进行处理。`process_item`函数进一步检查数据项中的键值对,根据特定的条件执行相应的逻辑。
## 4.2 创建一个Web应用的数据处理器
### 4.2.1 接收客户端JSON数据
在Web应用中,经常需要处理客户端通过POST请求发送的JSON数据。以下是如何在Flask框架中接收和解析JSON数据的示例:
```python
from flask import Flask, request, jsonify
app = Flask(__name__)
@app.route('/submit', methods=['POST'])
def submit():
data = request.json # 直接获取JSON数据
print(data)
# 进行数据处理...
return jsonify({'status': 'success', 'message': 'Data received'})
if __name__ == '__main__':
app.run(debug=True)
```
在上述代码中,我们定义了一个名为`submit`的路由,它接受POST请求。通过`request.json`属性,我们能够直接获取并解析JSON格式的请求体数据。处理完数据后,我们返回一个包含状态和消息的JSON响应。
### 4.2.2 在Web应用中处理JSON数据
一旦客户端的数据被成功接收,就可以在Web应用中进行处理。这可能涉及到与数据库的交互、执行业务逻辑等操作。以下代码展示了如何在Flask应用中处理接收到的数据并存储到数据库:
```python
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///site.db'
db = SQLAlchemy(app)
class MyModel(db.Model):
id = db.Column(db.Integer, primary_key=True)
data = db.Column(db.String(100))
@app.route('/submit', methods=['POST'])
def submit():
data = request.json
my_data = MyModel(data=json.dumps(data)) # 将JSON数据存储为字符串
db.session.add(my_data)
***mit()
return jsonify({'status': 'success', 'message': 'Data saved to database'})
if __name__ == '__main__':
app.run(debug=True)
```
在这个扩展示例中,我们创建了一个`MyModel`类,它映射到一个数据库表。当接收到JSON数据时,我们创建了一个该模型的实例,将数据保存为JSON字符串,然后将实例添加到数据库中并提交更改。
## 4.3 实现一个JSON数据报告生成器
### 4.3.1 从复杂数据中提取关键信息
在某些应用场景中,我们可能需要将复杂的JSON数据解析并提取关键信息,生成可读的报告。以下是如何实现这一过程的代码示例:
```python
import json
from xml.etree.ElementTree import fromstring, Element, SubElement, tostring
def extract_data_from_json(json_data):
# 假设JSON数据是一个复杂结构
# 我们需要提取某些特定的字段
extracted_data = {
'name': json_data['name'],
'age': json_data['age'],
'email': json_data['email']
}
return extracted_data
def generate_report(data):
# 生成报告的XML结构
root = Element('report')
person = SubElement(root, 'person')
for key, value in data.items():
element = SubElement(person, key)
element.text = str(value)
# 将XML转换为字符串
return tostring(root, encoding='unicode')
json_data = '{"name": "John Doe", "age": 30, "email": "***"}'
data = extract_data_from_json(json.loads(json_data))
report_xml = generate_report(data)
print(report_xml)
```
### 4.3.2 利用JSON生成可读报告
在这个小节中,我们将演示如何利用提取的数据生成一个可读的报告。这个例子中使用了XML来构建报告的格式,当然也可以选择其他格式,如HTML、Markdown等。
在上面的代码中,`extract_data_from_json`函数从JSON数据中提取了特定的字段,并返回了一个字典。`generate_report`函数接收这个字典,创建了一个XML树结构,并将每个键值对转换为XML元素。最后,函数返回了一个格式化好的XML字符串。
通过本章内容,我们已经学习了如何将Python与JSON结合,进行了实践应用案例的探讨,包括从RESTful API获取JSON数据、处理Web应用中的JSON数据以及生成JSON数据报告。在下一章中,我们将深入探讨如何优化Python中的JSON处理流程,包括性能优化、错误处理和安全性考量。
# 5. 优化Python中的JSON处理
在现代软件开发中,JSON处理的性能和安全性是关键因素。本章深入探讨如何优化Python中的JSON处理流程,包括性能优化、错误处理、调试以及安全性考虑。
## 5.1 性能优化技巧
当涉及到大规模数据处理时,JSON的性能优化显得尤为重要。优化数据加载和处理流程,识别并解决性能瓶颈,可以大幅提高应用程序的响应速度和效率。
### 5.1.1 优化数据加载和处理流程
加载和处理大量JSON数据时,优化代码可以带来显著的性能提升。以下是一些常见的优化策略:
- **使用`ujson`库**: 标准库中的`json`模块已经非常高效,但在需要极致性能的场景下,可以考虑使用`ujson`。这是一个C语言扩展,它的速度比Python原生的`json`模块要快很多。
```python
import ujson
# 解析JSON字符串
data = ujson.loads(json_string)
# 将Python对象转换为JSON字符串
json_string = ujson.dumps(obj)
```
`ujson`的使用方法与Python原生的`json`模块类似,但需要注意的是,`ujson`不支持`object_pairs_hook`参数。
- **并行处理**: 当处理多个大型JSON文件时,可以使用`concurrent.futures`模块或`multiprocessing`库来并行加载和处理数据。
```python
import concurrent.futures
def process_json(file_path):
with open(file_path, 'r') as ***
***
* 使用线程池来并行处理文件
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(process_json, file) for file in json_files]
results = [future.result() for future in concurrent.futures.as_completed(futures)]
```
并行处理可以显著减少总体处理时间,尤其是在多核CPU上运行时效果明显。
### 5.1.2 识别并解决性能瓶颈
性能瓶颈可能来自多个方面,包括但不限于磁盘I/O、内存使用以及CPU处理能力。识别瓶颈的方法包括:
- **使用性能分析工具**: `cProfile`是一个Python自带的性能分析工具,可以用来诊断代码中的性能瓶颈。
```python
import cProfile
def function_to_profile():
# 假设这是一个处理大量JSON数据的函数
pass
cProfile.run('function_to_profile()')
```
使用`cProfile`的输出可以帮助我们了解代码执行的耗时,进而定位和优化瓶颈。
- **内存分析**: 对于内存消耗较大的应用,可以使用`memory_profiler`来监测内存使用情况。
```python
from memory_profiler import memory_usage
mem_usage = memory_usage((function_to_profile, ()))
print(mem_usage)
```
通过检查内存使用情况,可以发现是否有不合理的内存消耗,并据此优化代码。
## 5.2 错误处理和调试
在进行JSON处理时,错误处理是不可忽视的一部分。了解常见的错误类型,并学会使用日志记录和调试技巧是提高代码健壮性的关键。
### 5.2.1 理解和处理常见错误
在使用Python处理JSON时,可能会遇到的常见错误包括但不限于:
- `JSONDecodeError`: 当尝试解析无效的JSON字符串时会抛出此错误。
- `TypeError`: 当尝试将不兼容类型转换为JSON时会发生此错误。
以下是处理这些常见错误的示例代码:
```python
import json
try:
data = json.loads(invalid_json)
except json.JSONDecodeError as e:
print("解析错误: ", e.msg)
except TypeError as e:
print("类型错误: ", e)
```
在实际应用中,除了捕获这些异常外,还应该有详细的日志记录,以便于后续分析和调试。
### 5.2.2 使用日志记录和调试技巧
日志记录是故障排查时不可或缺的工具。Python的`logging`模块提供了一个灵活的日志系统,可以根据需要进行配置。
```python
import logging
logging.basicConfig(level=***, format='%(asctime)s - %(levelname)s - %(message)s')
try:
data = json.loads(invalid_json)
except json.JSONDecodeError as e:
logging.error(f"JSON解码失败: {e}")
```
在上述代码中,我们将日志级别设置为`INFO`,并且为日志消息设置了一个格式,这样在发生错误时,可以通过查看日志文件找到错误的具体信息。
## 5.3 安全性考虑
安全性是软件开发中不可忽视的一环。在处理JSON数据时,需要特别注意防止JSON注入攻击以及确保数据的加密和安全传输。
### 5.3.1 防止JSON注入攻击
JSON注入攻击,通常指攻击者在输入中嵌入恶意JSON片段,导致应用程序执行未授权的命令或者暴露敏感信息。为了防止这种攻击,应采取以下措施:
- **验证输入数据**: 在将用户输入的数据转换为JSON之前,应进行严格的验证。
- **使用安全的JSON解析器**: 在使用第三方库进行JSON解析时,确保它们能够抵御注入攻击。
```python
# 例子:使用json模块的安全特性来防止注入
import json
safe_json_string = json.dumps({'user_input': user_input}, separators=(',', ':'))
```
在上述示例中,`separators`参数确保了JSON字符串中不包含额外的空格,这有助于减少潜在的注入风险。
### 5.3.2 数据加密与安全传输
为了保证数据在传输过程中的安全性,加密是必要的手段。一个常见的做法是使用HTTPS来确保数据传输的安全。在处理敏感数据时,还应该考虑使用加密库对数据进行加密。
```python
from cryptography.fernet import Fernet
# 生成密钥
key = Fernet.generate_key()
cipher_suite = Fernet(key)
# 加密数据
encrypted_data = cipher_suite.encrypt(data.encode())
```
在上述代码中,我们使用了`cryptography`库中的`Fernet`对数据进行加密。加密后的数据可以安全地传输,只有拥有对应密钥的接收方才能解密。
以上各节详细探讨了优化Python中JSON处理的方法,包括性能优化、错误处理和调试以及安全性的考虑。通过这些方法,开发者可以创建出更加高效、健壮且安全的JSON处理程序。
# 6. Python JSON技术的未来展望
## 6.1 新兴JSON标准和格式
随着数据处理需求的不断扩大,JSON本身也在不断发展,以适应更广泛的场景。JSON的新变体如JSON5和JSON-LD为处理更复杂的数据结构提供了可能。
### 6.1.1 JSON的新变体:JSON5和JSON-LD
JSON5是在JSON基础上的扩展,它增加了对更灵活的语法的支持,例如允许使用单引号、注释、尾随逗号等。这样做的好处是可以提高数据的可读性和可编辑性,尤其在配置文件中非常有用。
JSON-LD(Linked Data)则是一种将JSON数据与链接数据相结合的方法。它通过添加上下文信息到JSON对象中,使得数据可以被关联和链接。这对于数据的语义化和结构化特别重要,特别是在构建知识图谱和进行语义网应用开发中。
### 6.1.2 选择合适的JSON格式
在实际应用中,选择合适的JSON格式对于项目的成功至关重要。JSON5和JSON-LD各有千秋,应该根据项目需求进行选择。对于简单的数据交换,标准的JSON足以胜任。而对于需要额外注释、更宽松语法或者数据语义化的场景,则可以考虑使用JSON5和JSON-LD。
## 6.2 Python社区的新发展
### 6.2.1 最新JSON处理库的介绍
Python社区在JSON处理库方面持续进步,出现了像`orjson`、`ujson`这样的库,它们提供了更快的JSON序列化和反序列化能力。
`ujson`是基于C的实现,它比标准库`json`模块要快得多,尤其是在反序列化时。这个库特别适合于I/O密集型应用,需要处理大量JSON数据的场景。
`orjson`也是一个性能优越的选择,它支持Python 3,并且在处理大数据时表现尤为出色。它还包括了对JSON5的支持,为开发者提供了更多的灵活性。
### 6.2.2 社区贡献和未来发展方向
社区贡献是Python发展的重要组成部分。众多开发者通过GitHub等平台提交问题报告、提供代码补丁、编写文档,共同推动Python JSON库的进步。未来,我们可以期待更多的JSON相关的库被开发出来,以满足各种新出现的数据处理需求。
社区对于性能优化、新标准的支持、以及安全性方面的改进持续关注。开发者们也在不断地提供和测试新的特性,为Python JSON处理带来新的可能性。此外,随着AI和大数据的发展,对于能高效处理大规模数据的JSON库的需求将会进一步增长。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 simplejson 专栏!本专栏深入探讨了 simplejson 库,它是 Python 中高效处理 JSON 数据的利器。从入门到专家级别,我们将全面了解 simplejson 的功能和工作原理,并掌握优化 Python 程序的性能秘诀。此外,专栏还涵盖了 simplejson 在 Web 开发、数据序列化、RESTful 实践、数据分析和机器学习等领域的广泛应用。通过深入剖析 simplejson 的源码、比较它与其他 JSON 库的优势,以及提供高级技巧和最佳实践,本专栏旨在帮助您成为一名 simplejson 专家,并构建高性能、可扩展的 JSON 处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
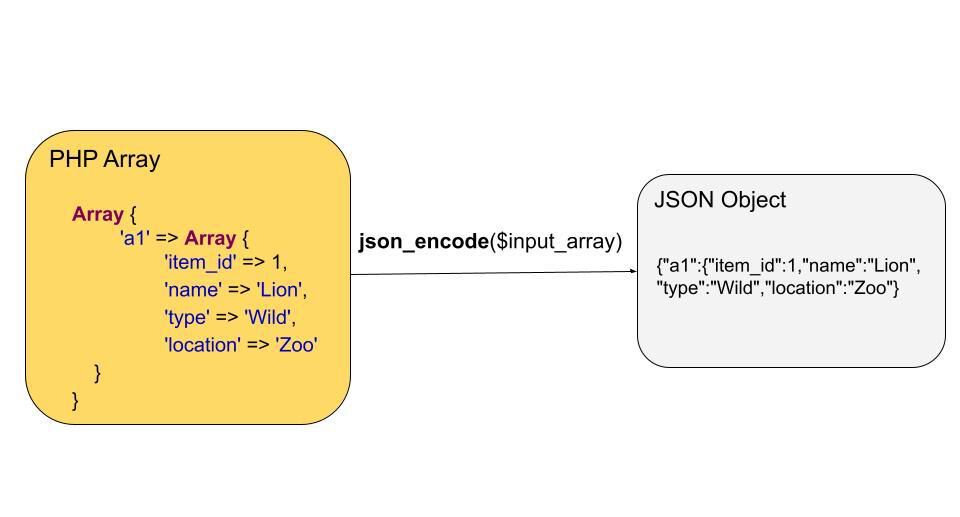
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
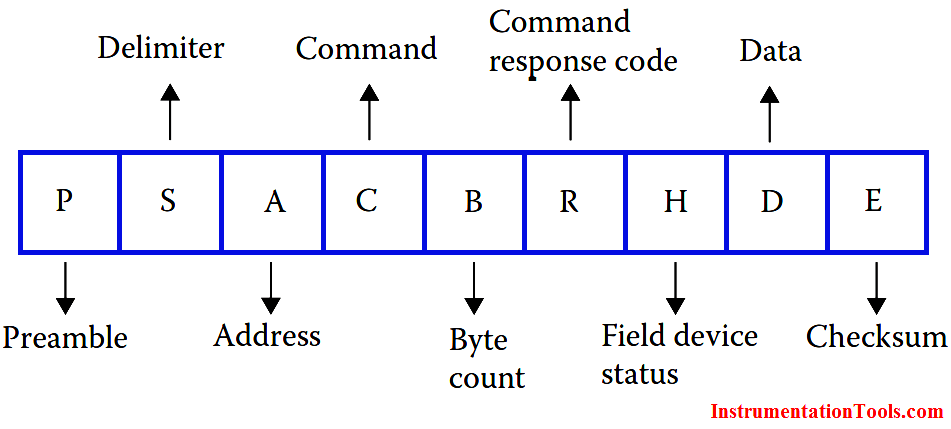
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )