【Java I_O流与数据交换】:解析XML_JSON数据交换格式的秘诀
发布时间: 2024-09-24 20:12:05 阅读量: 30 订阅数: 26 
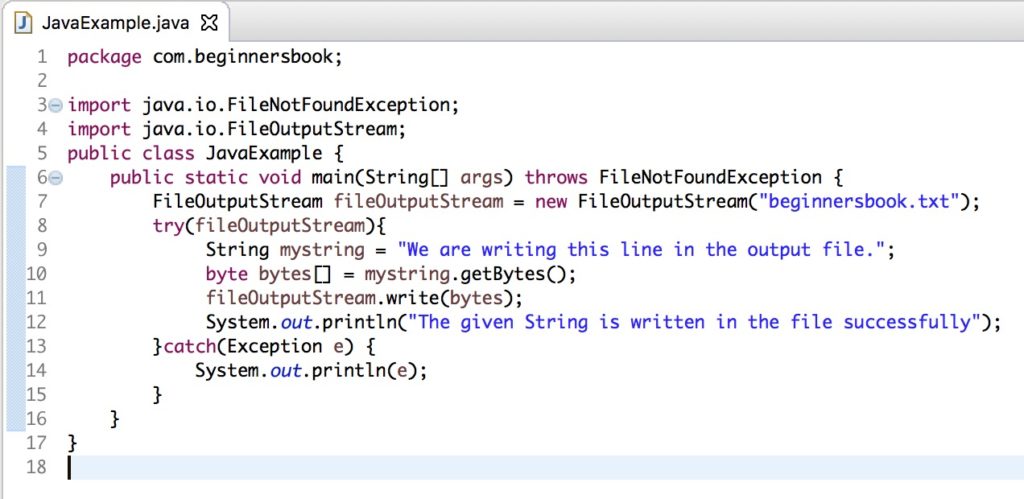
# 1. Java I/O流的基本概念与分类
## 1.1 I/O流的概念
I/O(Input/Output,输入/输出)流是Java中用于处理数据传输的一种抽象概念。在Java中,所有的数据传输都被看作是流的移动,无论是从文件读取数据、从网络接收数据还是向控制台打印信息。I/O流提供了一种标准的方法来处理不同的数据源和目标。
## 1.2 I/O流的分类
I/O流主要分为两大类:字节流和字符流。字节流用于处理二进制数据,如文件、图片等,其基础类为InputStream和OutputStream。字符流用于处理字符数据,主要操作的是字符和字符串,其基础类为Reader和Writer。除此之外,还有带有缓冲功能的BufferedInputStream、BufferedOutputStream、BufferedReader和BufferedWriter,以及装饰者模式下的FilterInputStream、FilterOutputStream、FilterReader和FilterWriter,这些都是为了在基本的输入输出功能上提供额外的处理能力。
通过本章的学习,读者将掌握Java I/O流的基本概念,并能够理解其主要分类和用途。接下来的章节将进一步深入探讨Java中对特定数据格式如XML和JSON的I/O流处理方式。
# 2. ```
# 第二章:深入理解XML与JSON数据格式
## 2.1 XML基础与结构解析
### 2.1.1 XML文档结构简介
XML(Extensible Markup Language)可扩展标记语言,是一种用于存储和传输数据的标记语言,其设计哲学强调数据的可读性和可扩展性。一个典型的XML文档由声明、元素、属性、文本和其他标记组成。XML的文档结构遵循严格的层级关系,其中每个元素都由一对开始标签和结束标签界定,标签内可以包含文本内容、子元素、属性等。
XML的声明通常位于文档的第一行,用于指明XML的版本和使用的字符编码,例如:
```xml
<?xml version="1.0" encoding="UTF-8"?>
```
### 2.1.2 XML元素、属性及命名空间
XML元素是构成XML文档的基本单位,可以包含其他元素、文本内容或属性。元素由一个开始标签和一个结束标签组成,例如:`<element>Content</element>`。XML属性提供关于元素的额外信息,它们必须出现在元素的开始标签内,并且不能包含嵌套的标签。命名空间是XML用来避免元素和属性名冲突的一种机制,通常与URI(统一资源标识符)配合使用。
例如,下面是一个包含属性和命名空间的XML元素:
```xml
<book xmlns:dc="***"
xmlns="***"
dc:title="XML Fundamentals">
<author>John Doe</author>
</book>
```
在上述例子中,`dc`是一个前缀,指向"dc"命名空间,该命名空间的URI为"***"。
## 2.2 JSON基础与结构解析
### 2.2.1 JSON数据格式特点
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它的主要特点包括:
- 独立于语言:JSON是基于文本的,其格式与编程语言无关,但通常与JavaScript紧密相关。
- 数据结构清晰:它只包括两种结构,对象(通常表现为JSON对象)和数组。
- 跨平台:由于其轻量级特性,JSON被广泛用于网络数据交换。
一个JSON对象是由键值对组成的集合,使用大括号{}括起来,每个键值对以逗号分隔。键和字符串值必须用双引号包围。数组则是用中括号[]表示,其中的元素也可以是对象或数组。
### 2.2.2 JSON对象、数组及值类型
JSON对象和数组是JSON数据结构的核心,对象表示为键值对的集合,而数组表示为值的有序列表。值类型可以是字符串、数字、布尔值、null、数组或对象。
```json
{
"firstName": "John",
"lastName": "Doe",
"age": 30,
"isStudent": false,
"address": {
"street": "100 Park Avenue",
"city": "New York"
},
"phoneNumbers": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "office",
"number": "646 555-4567"
}
]
}
```
在上述JSON文档中,定义了一个人的基本信息,包括姓名、年龄、是否为学生以及包含一个地址对象和一个电话号码数组。
## 2.3 XML与JSON的比较
### 2.3.1 两者在数据交换中的优缺点
XML与JSON作为数据交换格式各有其优点和局限性。在选择使用哪一种格式时,需要根据实际需求进行权衡。
XML的主要优点包括:
- 结构化和可扩展性:XML支持复杂的结构,可以通过定义新的标签和属性进行扩展。
- 强制性模式验证:XML可以使用DTD或XML Schema来验证数据的有效性。
- 完整性和自描述性:每个元素都是自我描述的,增加了数据的可读性。
然而,XML也有其缺点:
- 过于冗长:XML标签通常比较长,导致文档体积大,处理效率较低。
- 解析复杂性:XML的解析器通常比JSON解析器复杂。
- 编码和维护成本:由于其复杂性,编写和维护XML文档往往需要更多的时间和资源。
JSON的主要优点在于:
- 简洁性:JSON的结构紧凑,适合Web传输。
- 易于解析:对于开发者来说,JSON格式的数据结构清晰,并且容易通过编程语言解析。
- 性能优势:由于其简洁性,JSON在解析和序列化时通常比XML更快,更节省内存。
但JSON也有局限:
- 数据类型限制:JSON原生不支持复杂的数据类型和模式验证。
- 缺乏自我描述性:与XML相比,JSON的自描述性较差,缺乏模式信息。
### 2.3.2 场景选择XML与JSON的考量因素
选择XML还是JSON作为数据交换格式应考虑以下因素:
- 数据的复杂性:对于简单或中等复杂度的数据,JSON往往是更好的选择。对于需要高度结构化和可扩展性的复杂数据,XML更为合适。
- 系统与平台兼容性:如果系统已经广泛使用XML,并且与XML集成良好,那么切换到JSON可能需要较大的投入。反之亦然。
- 性能要求:在需要高效传输和处理的场景下,JSON通常表现更佳。
- 语言和工具支持:不同的编程语言和开发工具可能对XML和JSON的支持程度不同,这可能影响到选择。
在实际应用中,需要针对项目的特定需求和约束条件,综合考虑上述因素,做出最合理的选择。
```
# 3. Java中的XML数据处理
## 3.1 使用DOM解析XML数据
### 3.1.1 DOM解析器的工作原理
文档对象模型(Document Object Model,简称DOM)解析器是一种将XML文档以树状结构加载到内存中的解析方式。这种方式允许用户遍历和操作整个XML文档的结构。当DOM解析器解析XML文档时,它会将每个XML元素、属性和文本节点表示为树状结构的节点,然后我们可以使用DOM API来查询、修改、删除或者添加节点。
DOM解析器的优点是操作直观,它提供了一种直观的方式来处理XML数据,非常适合需要频繁读写操作的小文件处理。不过,它的缺点在于内存消耗大,尤其是处理大型XML文件时,可能对性能产生影响。
### 3.1.2 实际操作:解析XML并提取数据
下面是一个使用Java DOM解析XML数据并提取信息的实例。此示例包含以下步骤:
1. 创建DocumentBuilderFactory实例。
2. 使用DocumentBuilderFactory创建DocumentBuilder实例。
3. 使用DocumentBuilder解析XML文件到Document对象。
4. 遍历XML树结构,提取需要的数据。
```java
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
public class DomParserExample {
public static void main(String[] args) {
try {
// 1. 创建DocumentBuilderFactory实例
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// 2. 使用DocumentBuilderFactory创建DocumentBuilder实例
DocumentBuilder builder = factory.newDocumentBuilder();
// 3. 解析XML文件到Document对象
Document document = builder.parse("example.xml");
// 4. 获取根节点
Node root = document.getDocumentElement();
// 获取并打印所有的<book>节点
NodeList bookNodes = root.getChildNodes();
for (int i = 0; i < bookNodes.getLength(); i++) {
Node bookNode = bookNodes.item(i);
// 确保当前节点是一个元素节点
if (bookNode.getNodeType() == Node.ELEMENT_NODE) {
Element bookElement = (Element) bookNode;
// 提取并打印书名
String title = bookElement.getElementsByTagName("title").item(0).getTextContent();
System.out.println("Book Title: " + title);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
在上面的代码中,首先使用`DocumentBuilderFactory`实例化`DocumentBuilder`,然后解析指定的XML文件。通过访问`getElementsByTagName`方法获取所有`<title>`元素的列表,并遍历打印它们的文本内容。
**代码逻辑解读分析:**
- `DocumentBuilderFactory.newInstance()`: 创建一个`DocumentBuilderFactory`实例。
- `factory.newDocumentBuilder()`: 通过工厂创建一个`DocumentBuilder`实例,用于解析XML文档。
- `builder.parse("example.xml")`: 将XML文件解析为`Document`对象。
- `document.getDocumentElement()`: 获取XML文档的根节点。
- `bookNodes.item(i)`: 遍历根节点下的所有子节点。
- `bookNode.getNodeType() == Node.ELEMENT_NODE`: 判断节点类型是否为元素节点。
- `bookElement.getElementsByTagName("title").item(0).getTextContent()`: 获取`<title>`标签的文本内容并输出。
## 3.2 使用SAX解析XML数据
### 3.2.1 SAX解析器的工作原理
SAX(Simple API for XML)解析器是一种事件驱动的XML解析方法。与DOM不同,SAX不需要将整个XML文档加载到内存中,而是逐步读取XML文档,并在遇到特定的XML结构(如开始标签、结束标签和文本)时触发事件。通过实现事件处理器接口,我们可以响应这些事件,并进行必要的处理。
SAX解析器适合处理大型文件,因为它不需要将整个文档加载到内存。其缺点是对XML文档的只读访问,且无法随机访问XML文档的内容。
### 3.2.2 实际操作:事件驱动处理XML
下面是一个使用Java SAX解析XML数据的实例。示例包含以下步骤:
1. 创建一个`DefaultHandler`实例并重写相关的处理方法。
2. 创建`SAXParser`实例,并通过它解析XML文件。
3. 处理XML文档中的事件。
```java
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
public class SaxParserExample extends DefaultHandler {
public static void main(String[] args) {
try {
// 1. 创建SAX解析器
XMLReader saxParser = XMLReaderFactory.createXMLReader();
// 设置内容处理器
saxParser.setContentHandler(new SaxParserExample());
// 2. 解析XML文件
saxParser.parse("example.xml");
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
// 开始元素事件发生时调用
if (localName.equals("book")) {
System.out.println("Book Information:");
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
// 结束元素事件发生时调用
if (localName.equals("book")) {
System.out.println("End of book elemen
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java并发编程实践:设计线程安全类的10个技巧

# 1. Java并发编程概述
Java并发编程是构建可扩展和响应性高的应用程序的关键技术之一。随着多核处理器的普及,利用并发能够显著提升应用性能和吞吐量。在现代应用开发中,合理运用并发机制,不仅能够提高效率,还能处理异步事件和长时间运行的任务,保证用户界面的流畅性。
在本章中,我们将探索并发编程的基础概念,了解Java如何支持并发执行,以及多线程编程中的关键问题,如线程的创建和管
【并发编程案例精讲】:java.util.concurrent库的场景应用(实战技巧分享)

# 1. 并发编程概述
## 1.1 并发编程的重要性
在当今多核处理器普及的环境下,应用软件性能的提升在很大程度上依赖于并发编程技术。并发编程可以充分利用多核处理器资源,通过并发执行任务来提高程序的执行效率。在高性能服务器、大数据处理和云计算等领域,高并发场景尤为常见,掌握并发编程成为了软件开发者的必备技能。
## 1.2 并发编程的挑战
尽管并发编程有其明显的
Java消息服务(JMS):构建可靠消息系统的秘密武器

# 1. JMS的基本概念与架构
在现代企业应用架构中,消息服务是实现异步通信、解耦和提高系统可靠性的关键组件。Java消息服务(Java Message Service,简称JMS)是Java平台中关于面向消息中间件(Message-Oriented Middleware,简称M
【Java I_O流与数据交换】:解析XML_JSON数据交换格式的秘诀

# 1. Java I/O流的基本概念与分类
## 1.1 I/O流的概念
I/O(Input/Output,输入/输出)流是Java中用于处理数据传输的一种抽象概念。在Java中,所有的数据传输都被看作是流的移动,无论是从文件读取数据、从网络接收数据还是向控制台打印信息。I/O流提供了一种标准的方法来处理不同的数据源和目标。
## 1.2 I
Java设计模式实践指南:5大场景下优雅运用,提升架构能力!
# 1. 设计模式概述与Java实现基础
设计模式是软件工程中一套被广泛认可的解决特定问题的最佳实践。它们是通用的模板,为软件开发人员提供了一种解决方案的骨架,使代码更加灵活、可维护和可重用。了解设计模式,对于任何期望在软件开发行业取得成功的人来说都是至关重要的。
## Java实现基础
Java作为面向对象的编程语言,其语法和特性为实现设计模式
【Effective Java原则】:提升代码优雅性的编程指南

# 1. Effective Java原则概述
在现代Java开发中,遵循一些核心原则不仅能提升代码质量,还能增强系统的可维护性和性能。《Effective Java》是Java编程领域的一本经典指南,它提供了许多实用的最佳实践和技巧。本书不仅适合初学者,对于经验丰富的开发者来说,也有许多值得学习和复习的内容。在深入探讨诸如创建和销毁对象、类和接
【分布式系统类应用】:类(Class)在分布式架构中的作用与挑战应对策略
# 1. 分布式系统类应用概述
## 1.1 分布式系统的基础概念
在IT行业中,分布式系统是由多个互联的组件构成,这些组件在不同的硬件或软件平台上运行,协同处理任务。分布式系统类应用就是在这个环境下,利用面向对象编程中的类概念来开发软件应用。这类应用可以跨越多个服务器,实现系
【Java网络编程新视角】:HTTP客户端与服务器端构建实战
# 1. Java网络编程基础概述
Java网络编程是构建分布式应用的基础,允许应用程序之间通过网络进行通信。随着互联网的普及,网络编程已经成为开发者必备的技能之一。在本章节中,我们将探讨Java网络编程的基本概念,包括Java中的网络编程模型、套接字(Socket)的使用,以及网络地址和端口的相关知识。
从java.util到java.util.concurrent:并发集合设计与优化全解析
# 1. Java并发集合概述
在多线程编程的世界里,数据结构的线程安全是开发者始终绕不开的话题。Java 并发集合作为 Java 标准库中支持多线程环境的集合类,不仅提供了必要的线程安全保证,还针对并发操作进行了优化,以实现更高的性能和效率。本章将带领读者概览 Java 并发集合的全貌,了解其设计理念、核心特性和应用场景,为深入学习后续章节打下坚实的基础。
## 1.1 Java 并发集合的分类
Java 并发集合大致可以分为同步集合和并发集合两
Java.lang调试与诊断:深入使用ThreadMXBean与StackWalking
# 1. Java.lang调试与诊断概述
## 1.1 Java.lang调试与诊断的重要性
Java语言作为一种广泛使用的编程语言,其稳定性和性能对于任何基于Java的应用程序都至关重要。在开发和维护过程中,Java开发者经常需要对应用程序进行调试与诊断,以确保软件质
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )