关联规则应用边界拓展:arules包与机器学习算法的结合策略
发布时间: 2024-11-04 14:53:43 阅读量: 8 订阅数: 12 
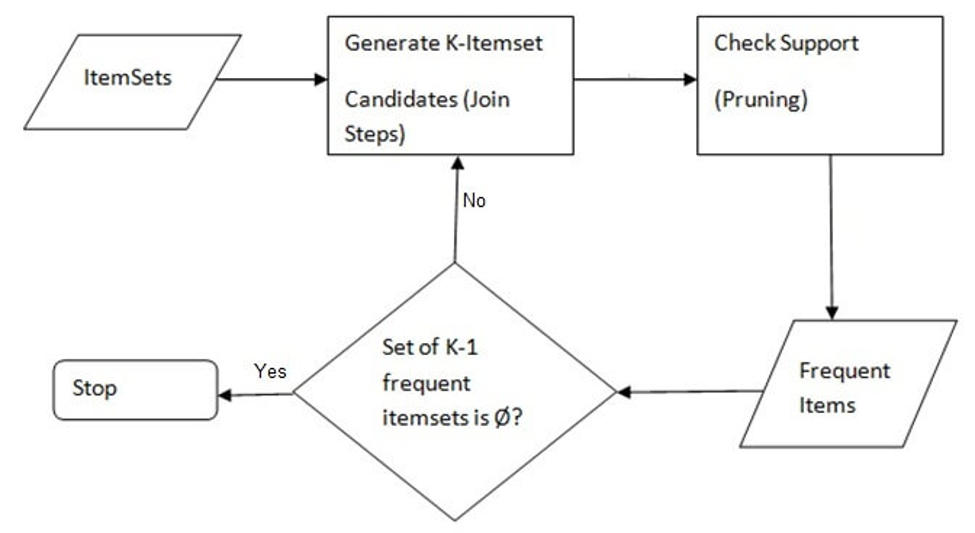
# 1. 关联规则分析基础和arules包概述
在现代数据挖掘领域中,关联规则分析是一种重要的技术,用于发现大规模数据集中变量之间的有趣关系。关联规则通过识别频繁项集和提取规则来捕捉数据中的模式和结构。一个典型的例子是购物篮分析,通过分析顾客在超市购买商品时的关联性,来制定销售策略或改善商店布局。
arules 是一个广泛使用的 R 语言包,专门为关联规则学习提供了各种工具。它不仅包括了经典算法如Apriori和Eclat,还有FP-Growth等算法来挖掘频繁项集,同时也支持规则的评估和可视化功能。本章将介绍关联规则的基本概念、算法原理以及arules包的结构和功能,为接下来的实践应用打下坚实的基础。
# 2. arules包的实践应用
## 2.1 arules包数据准备和转换
### 2.1.1 数据导入与格式化
在分析关联规则之前,首先需要准备合适的数据集。这通常意味着将数据从各种原始格式导入到R中,并确保它们以正确的格式表示事务数据。R的`arules`包能够处理多种数据格式,例如CSV、Excel或者直接从数据库中导入。
下面是一个示例代码,演示如何从CSV文件导入数据,并进行必要的格式化操作:
```r
# 安装和加载arules包
if (!require(arules)) install.packages("arules")
library(arules)
# 从CSV文件导入数据
data <- read.transactions("data.csv", format="basket", sep=",")
# 查看数据的基本信息
summary(data)
# 数据格式化
# 假设CSV文件中的每列代表一个商品,每行代表一个购物篮
# R中的transactions格式要求每个事务为一行,每个商品为一个列名
# 如果数据不满足这些要求,需要进行适当的转换
```
在执行上述代码之前,确保你的CSV文件格式符合要求。每条记录(即购物篮)包含一个或多个商品,商品之间用逗号或其他分隔符分隔。
### 2.1.2 事务数据集的创建与管理
一旦数据被正确导入,下一步就是创建事务数据集。事务数据集是关联规则分析的基础,它将数据集中的每个事务(例如,顾客的购物篮)封装成一个单独的对象。
在R中,可以使用`transactions`函数创建事务数据集:
```r
# 创建事务数据集
data <- read.transactions("data.csv", format="basket", sep=",")
# 查看事务数据集的结构
inspect(data[1:3])
# 简单的数据操作
# 例如,移除包含少于3个商品的事务
data <- subset(data, size(data) >= 3)
# 对事务数据集进行预处理,例如编码转换等
# 这里以将数据集中的商品名称转换为大写为例
itemLabels(data) <- toupper(itemLabels(data))
```
在上述代码中,`inspect`函数用于检查事务数据集中的前几条记录。`subset`函数用于过滤数据集,移除包含少于3个商品的事务,这对于提高关联规则分析的效率和准确性是有帮助的。此外,预处理步骤根据分析需要进行,确保数据的一致性和准确性。
## 2.2 arules包核心算法应用
### 2.2.1 Apriori算法实践
Apriori算法是关联规则学习中最著名和广泛使用的算法之一。它使用一种称作迭代的方法,先找出所有的频繁项集,这些项集出现的频率超过用户给定的最小支持度阈值,然后由这些频繁项集产生强关联规则。
下面的代码展示了如何使用`arules`包中的`apriori`函数来应用Apriori算法:
```r
# 设置最小支持度阈值
min_support <- 0.01
# 应用Apriori算法
rules <- apriori(data, parameter = list(supp = min_support, target = "rules"))
# 查看生成的规则
inspect(rules[1:5])
```
在上述代码中,`apriori`函数用于挖掘频繁项集,并生成关联规则。其中`parameter`参数用于设置最小支持度(`supp`)和其他可选参数。最后,`inspect`函数用于查看生成的关联规则。
### 2.2.2 Eclat和FP-growth算法比较
除了Apriori算法之外,Eclat和FP-growth是两种更高效的挖掘频繁项集的算法。Eclat算法使用深度优先搜索,并通过垂直数据格式提高效率。FP-growth算法则通过构建一个称为FP树的特殊数据结构来避免产生候选集。
以下是使用`arules`包实现Eclat和FP-growth算法的示例代码:
```r
# 使用Eclat算法
rules_eclat <- eclat(data, parameter = list(supp = min_support, target = "rules"))
# 使用FP-growth算法
rules_fpgrowth <- fpgrowth(data, parameter = list(supp = min_support, target = "rules"))
# 比较不同算法生成的规则
compare <- data.frame(
Algorithm = c("Apriori", "Eclat", "FP-growth"),
RuleCount = c(length(rules), length(rules_eclat), length(rules_fpgrowth))
)
print(compare)
```
在上述代码中,我们对每种算法使用了相同的支持度阈值,并计算了每种算法挖掘出的规则数量。这可以帮助我们对比不同算法的性能和效率。
### 2.2.3 关联规则的评估指标
生成关联规则后,需要使用各种评估指标来评价规则的品质。主要的评估指标包括支持度、置信度和提升度。
- 支持度(Support): 规则中所有项集在所有事务中出现的频率。
- 置信度(Confidence): 一个规则的可信度,即在前项发生的条件下,后项也发生的概率。
- 提升度(Lift): 表示规则的有趣程度,提升度大于1表示规则的前项和后项正相关。
下面是计算规则评估指标的示例代码:
```r
# 计算并添加规则的评估指标
rules <- sort(rules, by="confidence", decreasing=TRUE)
rules <- interestMeasure(rules, measure = c("support", "confidence", "lift"), data = data)
# 查看规则的评估指标
inspect(rules[1:3])
```
在上述代码中,首先通过`sort`函数按照置信度降序排列规则,然后使用`interestMeasure`函数计算每条规则的支持度、置信度和提升度,并将其添加到规则对象中。最后,通过`inspect`函数查看规则的评估指标。
## 2.3 关联规则的可视化展示
### 2.3.1 规则的图形化呈现
为了更直观地理解关联规则,`arulesViz`包提供了多种可视化方法。它可以帮助我们以图形方式展示频繁项集和关联规则。
下面是使用`arulesViz`包绘制关联规则图形的示例代码:
```r
# 安装和加载arulesViz包
if (!require(arulesViz)) install.packages("arulesViz")
library(arulesViz)
# 绘制关联规则图形
plot(rules, method="graph", control=list(type="itemsets"))
```
在上述代码中,`plot`函数使用`graph`方法绘制关联规则图形。`control`参数中的`type`参数设置为`itemsets`,意味着将关联规则中的项集以图形的方式展示。
### 2.3.2 多规则集的交互式探索
有时候我们需要对大量规则进行探索性分析,交互式探索工具可以帮助我们更好地理解数据。`arulesViz`包也支持交互式可视化。
下面是启动交互式可视化会话的示例代码:
```r
# 启动交互式可视化会话
interactive <- subset(rules, subset=lift > 1)
plot(interactive, method="grouped")
```
在上述代码中,`subset`函数用于筛选出提升度大于1的规则,这些规则被认为是有趣的。然后使用`plot`函数并设置`method`为`grouped`来启动交互式探索,这允许用户通过图形界面直观地分析规则。
接下来,我们将继续探讨`arules`包的更多应用,并介绍机器学习与关联规则分析的结合策略。
# 3. 机器学习与关联规则的结合策略
## 3.1 从关联规则到分类模型的转换
### 3.1.1 规则提取与特征工程
在机器学习和数据挖掘领域,分类模型是预测因变量类别的一种常用方法。然而,往往需要通过适当的特征选择和提取过程来改进模型的性能。关联规则可以在这个过程中发挥关键作用,通过从数据集中提取有用的模式来创建新的特征。
例如,在信用卡欺诈检测中,关联规则可以揭示出哪些交易特征经常一起出现,从而可能指示异常行为。因此,我们可以将这些特征组合起来,为分类模型提供更为丰富的输入信息。以下

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【R语言极端值处理】:extRemes包进阶技术,成为数据分析高手

# 1. R语言在极端值处理中的应用概述
## 1.1 R语言简介
R语言是一种在统计分析领域广泛应用的编程语言。它不仅拥有强大的数据处理和分析能力,而且由于其开源的特性,社区支持丰富,不断有新的包和功能推出,满足不同研究和工作场景的需求。R语言在极端值处理中的应用尤为突出,因其提供了许多专门用于
【R语言统计推断】:ismev包在假设检验中的高级应用技巧

# 1. R语言与统计推断基础
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。由于其强大的数据处理能力、灵活的图形系统以及开源性质,R语言被广泛应用于学术研究、数据分析和机器学习等领域。
## 1.2 统计推断基础
统计推断是统计学中根据样本数据推断总体特征的过程。它包括参数估计和假设检验两大主要分支。参数估计涉及对总体参数(如均值、方差等)的点估计或区间估计。而
R语言高级技巧大公开:定制化数据包操作流程速成

# 1. R语言基础回顾与高级数据结构
在这一章节,我们将对R语言的基础知识进行快速回顾,并深入探讨其高级数据结构。R语言以其强大的数据处理能力和灵活的统计分析功能,在数据科学领域获得了广泛的应用。我们将从基本的数据类型讲起,逐步深入到向量、矩阵、列表、数据框(DataFrame)以及R中的S3和S4对象系统。通过学习本章,读者将掌握如何使用这些高级数据结构来存储和管理复杂的数据集,
【R语言parma包案例分析】:经济学数据处理与分析,把握经济脉动

# 1. 经济学数据处理与分析的重要性
经济数据是现代经济学研究和实践的基石。准确和高效的数据处理不仅关系到经济模型的构建质量,而且直接影响到经济预测和决策的准确性。本章将概述为什么在经济学领域中,数据处理与分析至关重要,以及它们是如何帮助我们更好地理解复杂经济现象和趋势。
经济学数据处理涉及数据的采集、清洗、转换、整合和分析等一系列步骤,这不仅是为了保证数据质量,也是为了准备适合于特
【R语言时间序列预测大师】:利用evdbayes包制胜未来

# 1. R语言与时间序列分析基础
在数据分析的广阔天地中,时间序列分析是一个重要的分支,尤其是在经济学、金融学和气象学等领域中占据
【R语言编程实践手册】:evir包解决实际问题的有效策略

# 1. R语言与evir包概述
在现代数据分析领域,R语言作为一种高级统计和图形编程语言,广泛应用于各类数据挖掘和科学计算场景中。本章节旨在为读者提供R语言及其生态中一个专门用于极端值分析的包——evir——的基础知识。我们从R语言的简介开始,逐步深入到evir包的核心功能,并展望它在统计分析中的重要地位和应用潜力。
首先,我们将探讨R语言作为一种开源工具的优势,以及它如何在金融
【自定义数据包】:R语言创建自定义函数满足特定需求的终极指南
# 1. R语言基础与自定义函数简介
## 1.1 R语言概述
R语言是一种用于统计计算和图形表示的编程语言,它在数据挖掘和数据分析领域广受欢迎。作为一种开源工具,R具有庞大的社区支持和丰富的扩展包,使其能够轻松应对各种统计和机器学习任务。
## 1.2 自定义函数的重要性
在R语言中,函数是代码重用和模块化的基石。通过定义自定义函数,我们可以将重复的任务封装成可调用的代码
【R语言极值事件预测】:评估和预测极端事件的影响,evd包的全面指南

# 1. R语言极值事件预测概览
R语言,作为一门功能强大的统计分析语言,在极值事件预测领域展现出了其独特的魅力。极值事件,即那些在统计学上出现概率极低,但影响巨大的事件,是许多行业风险评估的核心。本章节,我们将对R语言在极值事件预测中的应用进行一个全面的概览。
首先,我们将探究极值事
TTR数据包在R中的实证分析:金融指标计算与解读的艺术

# 1. TTR数据包的介绍与安装
## 1.1 TTR数据包概述
TTR(Technical Trading Rules)是R语言中的一个强大的金融技术分析包,它提供了许多函数和方法用于分析金融市场数据。它主要包含对金融时间序列的处理和分析,可以用来计算各种技术指标,如移动平均、相对强弱指数(RSI)、布林带(Bollinger
R语言YieldCurve包优化教程:债券投资组合策略与风险管理
# 1. R语言YieldCurve包概览
## 1.1 R语言与YieldCurve包简介
R语言作为数据分析和统计计算的首选工具,以其强大的社区支持和丰富的包资源,为金融分析提供了强大的后盾。YieldCurve包专注于债券市场分析,它提供了一套丰富的工具来构建和分析收益率曲线,这对于投资者和分析师来说是不可或缺的。
## 1.2 YieldCurve包的安装与加载
在开始使用YieldCurve包之前,首先确保R环境已经配置好,接着使用`install.packages("YieldCurve")`命令安装包,安装完成后,使用`library(YieldCurve)`加载它。
``
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )