Web端自动化测试入门指南
发布时间: 2024-02-22 16:23:18 阅读量: 34 订阅数: 36 
# 1. 什么是Web端自动化测试
自动化测试是软件开发过程中的一项重要环节,它可以提高测试效率、减少人为错误,并确保软件质量。而Web端自动化测试作为自动化测试的一种形式,针对Web应用程序进行测试,可以模拟用户在浏览器中的操作行为,验证页面的功能和性能。
## 1.1 什么是自动化测试
自动化测试是通过编写脚本和工具来执行测试用例,从而实现对软件系统的自动验证和确认。相较于手动测试,自动化测试具有更高的执行速度、更好的复用性和更可靠的执行结果。
## 1.2 Web端自动化测试的概念和原理
Web端自动化测试是通过自动化工具模拟浏览器操作,对Web应用程序进行测试。其原理是利用浏览器驱动程序控制浏览器打开指定网页,根据预先设定的测试脚本进行元素定位、操作和断言,最终验证页面功能是否符合预期。
## 1.3 为什么需要Web端自动化测试
1. 提高测试效率:自动化测试可以快速执行大量测试用例,缩短测试周期。
2. 减少人为错误:自动化测试可以减少手工测试中的人为错误,提高测试准确性。
3. 提升软件质量:自动化测试能够持续监控和验证软件功能,确保代码质量和稳定性。
# 2. Web端自动化测试工具介绍
自动化测试工具对于Web端测试至关重要,它们可以帮助我们更高效地执行测试并提高测试覆盖率。在本章中,我们将介绍一些常用的Web端自动化测试工具,并探讨如何选择最适合您项目需求的工具以及如何正确安装和配置它们。让我们一起深入了解吧。
### 2.1 常用的Web端自动化测试工具
在Web端自动化测试领域,有许多开源和商业工具可供选择。以下是一些常用的Web端自动化测试工具:
- **Selenium**: Selenium是一种用于测试Web应用程序的工具,支持多种编程语言,并且可以模拟用户操作。
- **Protractor**: Protractor是一个基于Selenium的端到端测试框架,专门用于AngularJS应用程序的自动化测试。
- **Cypress**: Cypress是一个快速、简单且可靠的测试工具,具有实时重新加载和可见断言等特性。
- **Puppeteer**: Puppeteer是由Google开发的Node库,用于控制Chrome浏览器进行自动化测试。
- **TestCafe**: TestCafe是一个现代的自动化测试工具,它可以跨各种浏览器进行测试,并且不需要WebDriver。
### 2.2 选择最适合你的Web端自动化测试工具
在选择Web端自动化测试工具时,您需要考虑以下几点:
- **项目需求**: 不同的项目可能需要不同的工具,比如对Angular应用程序来说,Protractor可能更适合;而对于跨浏览器测试需求的项目,TestCafe可能是更好的选择。
- **技术栈**: 如果团队已经熟悉了某种编程语言,最好选择对应语言的测试工具,这样能够减少学习成本。
- **社区支持**: 选择一个有活跃社区支持的工具会更有帮助,您可以在社区中找到解决问题的答案和资源。
### 2.3 如何安装和配置Web端自动化测试工具
安装和配置Web端自动化测试工具通常是一个相对简单的过程,具体步骤取决于您选择的工具和编程语言。一般来说,您可以通过以下步骤来完成安装和配置:
1. **安装依赖**: 确保您的系统中已经安装了相关的依赖,比如浏览器驱动或Node.js环境。
2. **安装工具**: 使用包管理工具如npm或yarn安装您选择的自动化测试工具。
3. **配置工具**: 根据工具的文档,进行必要的配置,比如添加路径到系统环境变量等。
通过良好的安装和配置,您就可以开始使用选定的Web端自动化测试工具来编写和执行测试用例了。
在接下来的章节中,我们将深入探讨Web端自动化测试的基本概念和技术,帮助您更好地理解和应用自动化测试。
# 3. Web端自动化测试的基本概念
Web端自动化测试是一种通过编写脚本来模拟用户操作,以验证网站或Web应用程序是否按预期工作的方法。在本章中,我们将介绍Web端自动化测试中的一些基本概念,包括浏览器驱动和操作、元素定位和操作,以及断言和验证。
#### 3.1 浏览器驱动和操作
在进行Web端自动化测试时,需要通过浏览器驱动来控制浏览器进行操作。常用的浏览器驱动包括ChromeDriver、GeckoDriver(用于Firefox)、EdgeDriver等。通过选择相应的浏览器驱动,我们可以在自动化脚本中打开特定的浏览器,并模拟用户在浏览器中的操作,比如打开网页、点击链接、输入文字等。
下面是使用Python和Selenium WebDriver进行浏览器驱动和操作的示例代码:
```python
from selenium import webdriver
# 使用Chrome浏览器驱动
driver = webdriver.Chrome(executable_path='/path/to/chromedriver')
driver.get('http://www.example.com')
element = driver.find_element_by_id('elementID')
element.click()
```
#### 3.2 元素定位和操作
在Web端自动化测试中,元素定位是指定位页面中的元素,比如按钮、输入框、链接等,以便对其进行操作。常用的元素定位方式包括ID、class、name、tag name、link text、partial link text、xpath和css selector。
下面是使用Java和Selenium WebDriver进行元素定位和操作的示例代码:
```java
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
public class Example {
public static void main(String[] args) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.example.com");
WebElement element = driver.findElement(By.id("elementID"));
element.sendKeys("Hello, World!");
}
}
```
#### 3.3 断言和验证
在编写自动化测试脚本时,我们需要进行断言和验证,以确保页面上的元素和操作符合预期。断言是一种用于验证页面行为和状态的技术,比如判断元素是否存在、文本是否正确等。
下面是使用JavaScript和WebDriverIO进行断言和验证的示例代码:
```javascript
describe('Example Test', () => {
it('should have the right title', () => {
browser.url('http://www.example.com');
expect(browser).toHaveTitle('Example Domain');
});
});
```
通过掌握浏览器驱动和操作、元素定位和操作,以及断言和验证等基本概念,可以帮助我们更好地编写和理解Web端自动化测试脚本。
# 4. 构建可维护的自动化测试用例
在Web端自动化测试中,构建可维护的测试用例至关重要。良好的测试用例不仅能够提高测试效率,还能确保测试结果的准确性。本章将介绍如何构建可维护的自动化测试用例,并探讨一些实用的技巧和最佳实践。
#### 4.1 选择合适的测试场景
在编写自动化测试用例之前,首先需要明确测试的范围和目的。合理选择测试场景可以帮助我们聚焦于关键功能的测试,提高测试覆盖度和效率。
```python
# 示例代码:选择登录场景进行自动化测试
def test_login_success():
# 模拟用户输入正确的用户名和密码进行登录
username = "test_user"
password = "123456"
login(username, password)
# 验证登录成功后页面跳转,断言用户信息是否正确显示
assert get_current_url() == "https://www.example.com/dashboard"
assert get_element_text("user_info") == "Welcome, test_user!"
# 其他验证步骤...
def test_login_failure():
# 模拟用户输入错误的用户名和密码进行登录
username = "invalid_user"
password = "wrong_password"
login(username, password)
# 验证登录失败后的提示信息,断言错误提示是否正确显示
assert get_element_text("error_message") == "Invalid username or password"
# 其他验证步骤...
# 编写其他测试场景...
```
#### 4.2 编写可读性强的自动化测试代码
编写清晰易懂的测试代码可以提高代码的可维护性和可读性,让团队成员更容易理解和维护测试用例。
```java
// 示例代码:编写可读性强的登录测试用例
@Test
public void testLoginSuccess() {
// 模拟用户输入正确的用户名和密码进行登录
String username = "test_user";
String password = "123456";
login(username, password);
// 验证登录成功后页面跳转,断言用户信息是否正确显示
assertEquals("https://www.example.com/dashboard", getCurrentUrl());
assertEquals("Welcome, test_user!", getElementText("user_info"));
// 其他验证步骤...
}
@Test
public void testLoginFailure() {
// 模拟用户输入错误的用户名和密码进行登录
String username = "invalid_user";
String password = "wrong_password";
login(username, password);
// 验证登录失败后的提示信息,断言错误提示是否正确显示
assertEquals("Invalid username or password", getElementText("error_message"));
// 其他验证步骤...
}
// 编写其他测试场景...
```
#### 4.3 数据驱动和参数化测试
使用数据驱动和参数化测试可以帮助我们更全面地覆盖测试案例,减少重复代码的编写,提高代码的重用性。
```javascript
// 示例代码:数据驱动的搜索测试用例
const testData = [
{ keyword: "automation", expectedResults: 10 },
{ keyword: "testing", expectedResults: 20 },
{ keyword: "selenium", expectedResults: 5 }
];
for (const data of testData) {
test(`Search for "${data.keyword}" returns ${data.expectedResults} results`, () => {
search(data.keyword);
assert.equal(getSearchResultsCount(), data.expectedResults);
});
}
```
以上是第四章的部分内容,希望对您有所帮助。在接下来的章节中,我们将继续探讨Web端自动化测试的更多实践和技巧。
# 5. 运行和管理自动化测试
在进行Web端自动化测试后,如何有效地运行和管理测试是至关重要的。本章将介绍如何在不同环境中运行自动化测试,以及如何整合自动化测试到持续集成和持续交付流程中。
### 5.1 在不同环境中运行自动化测试
在实际项目中,往往需要在不同的环境中运行自动化测试,包括本地开发环境、测试环境和生产环境。为了保证测试的全面性和准确性,我们需要在这些不同的环境中执行自动化测试用例。
```python
import unittest
from selenium import webdriver
class TestWebAutomation(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
def test_login(self):
self.driver.get("http://www.example.com")
# Perform login actions
# Assertions
def tearDown(self):
self.driver.quit()
if __name__ == "__main__":
unittest.main()
```
### 5.2 整合自动化测试到持续集成和持续交付流程
将自动化测试整合到持续集成(CI)和持续交付(CD)流程中,可以帮助团队更快速、高效地构建、测试和交付代码。通过自动化测试,可以在每次代码提交后自动运行测试用例,及时发现问题并给出反馈。
```python
# Jenkinsfile
pipeline {
agent any
stages {
stage('Checkout') {
steps {
// Checkout code from version control
}
}
stage('Build') {
steps {
// Build project
}
}
stage('Test') {
steps {
// Run automated tests
}
}
stage('Deploy') {
steps {
// Deployment steps
}
}
}
}
```
### 5.3 测试报告和结果分析
生成详细的测试报告并进行结果分析是自动化测试的重要环节。测试报告应该包含测试用例执行情况、通过和失败的用例数量、失败原因等信息,同时也需要对结果进行分析,及时优化测试用例和代码。
```python
# 测试报告生成示例
def generate_test_report(results):
for result in results:
print(f"Test Case: {result['name']}, Result: {result['result']}")
if not result['result']:
print(f"Failure Reason: {result['failure_reason']}")
# 结果分析示例
def analyze_test_results(results):
total_tests = len(results)
passed_tests = sum(result['result'] for result in results)
failed_tests = total_tests - passed_tests
success_rate = (passed_tests / total_tests) * 100
print(f"Total Tests: {total_tests}, Passed: {passed_tests}, Failed: {failed_tests}")
print(f"Success Rate: {success_rate}%")
```
通过本章的介绍,希望您能更好地运行和管理Web端自动化测试,提升测试效率和质量。
# 6. Web端自动化测试的最佳实践
在进行Web端自动化测试时,遵循最佳实践可以提高测试效率和可靠性。本章将介绍一些Web端自动化测试的最佳实践,帮助您编写稳定、可靠且高效的自动化测试代码。
#### 6.1 编写稳定和可靠的自动化测试
稳定和可靠的自动化测试是保证测试准确性和持续集成成功的关键。以下是一些建议:
- **显式等待操作:** 在定位元素和执行操作时,使用显式等待确保元素加载完全再进行操作,避免因为页面未加载完成而导致的失败。
- **减少依赖:** 编写测试用例时尽量避免依赖外部因素,比如特定的数据状态、特定的网络环境等,确保测试用例的独立性。
- **管理测试数据:** 使用合适的数据驱动方式管理测试数据,以确保数据的准确性和一致性。
- **异常处理:** 在测试代码中添加合适的异常处理机制,捕获并处理可能出现的异常,以避免测试中断。
- **定期维护:** 定期检查和更新自动化测试代码,确保代码与应用程序的最新状态保持同步,以及修复可能出现的问题。
#### 6.2 避免常见的自动化测试陷阱
在编写自动化测试时,避免一些常见的陷阱可以提高测试代码的质量和可维护性:
- **避免硬编码:** 尽量避免在测试代码中使用硬编码的元素定位和测试数据,使用参数化和配置文件来管理需要的数据和元素定位信息。
- **避免过度依赖UI细节:** 测试案例应该专注于业务逻辑的验证,而不是被 UI 细节所干扰,避免过于依赖页面的布局和样式。
- **避免重复代码:** 提取重复的操作为独立的函数或方法,以避免代码冗余和提高代码复用性。
- **避免不必要的等待:** 避免使用过长或不必要的等待时间,以提高测试执行效率。
#### 6.3 提高自动化测试的效率和覆盖率
在编写自动化测试时,考虑一些策略和技术来提高测试的效率和覆盖率:
- **并行测试执行:** 使用并行测试执行技术可以显著降低测试执行时间,提高测试效率。
- **集成API测试:** 结合API测试和UI测试,对系统进行端到端的测试,提高测试覆盖范围。
- **使用Page Object模式:** 使用Page Object模式来管理页面对象和页面操作,提高测试代码的可维护性和可读性,减少重复代码。
上述最佳实践可以帮助您编写稳定、可靠且高效的Web端自动化测试代码,提高测试覆盖率和持续集成的成功率。
希望本章内容能够帮助您更好地进行Web端自动化测试的工作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《Web端自动化测试实战》将深入探讨自动化测试在Web开发中的实际应用。首先从入门指南开始,引导读者了解自动化测试的基本概念和流程。接着,详细介绍如何编写可维护的自动化测试脚本,以及使用Page Object模式进行测试代码重构。随后,我们将探索如何集成持续集成工具Jenkins实现自动化测试,并利用Selenium WebDriver实现数据驱动测试。同时,还将深入研究Headless浏览器自动化测试、基于元素属性的验证测试以及性能测试与负载测试实战。除此之外,我们还会讨论利用Selenium进行不同浏览器的兼容性测试、Web应用的前端UI自动化测试,以及复杂交互UI测试的实现。最后,我们将重点关注Web应用的API接口自动化测试、用户行为模拟测试,以及多语言及地区化的交互测试。无论你是初学者还是有一定经验的开发者,本专栏都将为你带来丰富的知识和实战经验。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【三菱PLC故障诊断技巧】:GX Works3中的故障诊断工具使用,快速定位问题

参考资源链接:[三菱GX Works3编程手册:安全操作与应用指南](https://wenku.csdn.net/doc/645da0e195996c03ac442695?spm=1055.2635.3001.10343)
# 1. 三菱PLC故障诊断概述
PLC(可编程逻辑控制器)作为工业自动化领域的重要设备,三菱PLC因其稳定性和高效性广泛应用于多个行业中。当三菱PLC发生故障时,系统可能会停止运行,导致生产停滞,因此故
【跨平台GBFF文件解析】:兼容性问题的终极解决方案

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. 跨平台文件解析的挑战与GBFF格式
跨平台应用在现代社会已经成为一种常态,这不仅仅表现在不同操作系统之间的兼容,还包括不同硬件平台以及网络环境。在文件解析这一层面,
【高级电路故障排除】:PIN_delay设置错误的诊断与修复,恢复系统稳定性
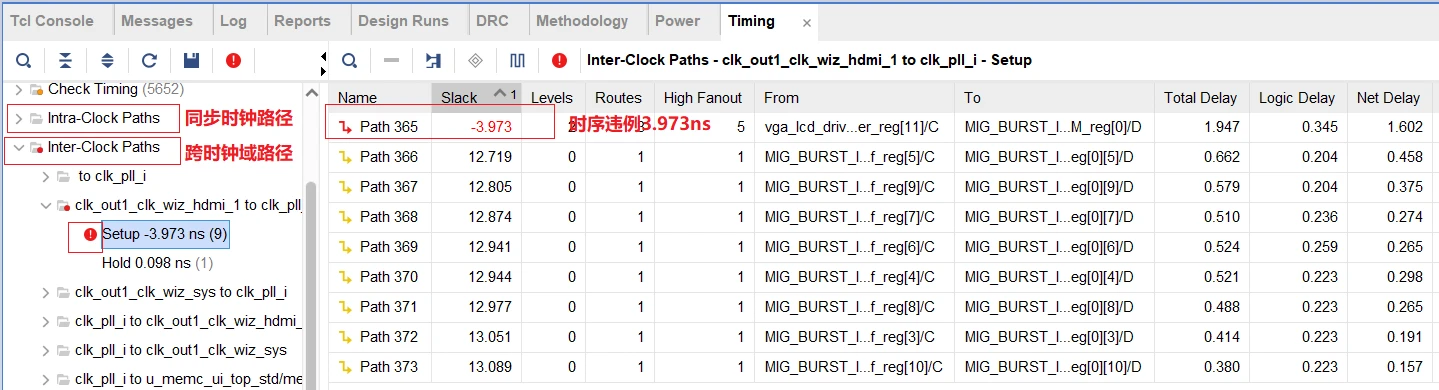
参考资源链接:[Allegro添加PIN_delay至高速信号的详细教程](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f6b?spm=1055.2635.3001.10343)
# 1. PIN_delay设置的重要性与影响
在当今的IT和电子工程领域,PIN_delay参数的设置对于确保系统稳定性和
STEP7 GSD文件安装:资源不足时的10个应对策略
参考资源链接:[解决STEP7中GSD安装失败问题:解除引用后重装](https://wenku.csdn.net/doc/6412b5fdbe7fbd1778d451c0?spm=1055.2635.3001.10343)
# 1. STEP7 GSD文件安装概述
【自定义宏故障处理】:发那科机器人灵活性与稳定性并存之道
参考资源链接:[发那科机器人SRVO-037(IMSTP)与PROF-017(从机断开)故障处理办法.docx](https://wenku.csdn.net/doc/6412b7a1be7fbd1778d4afd1?spm=1055.2635.3001.10343)
# 1. 发那科机器人自定义宏概述
自定义宏是发那科机器人编程中的一个强大工具,它允许用户通过参数化编程来简化重复性任务和复杂逻辑
【防止过拟合】机器学习中的正则化技术:专家级策略揭露

参考资源链接:[《机器学习(周志华)》学习笔记.pdf](https://wenku.csdn.net/doc/6412b753be7fbd1778d49
GNSS高程数据精度增强术:提升技巧与现场操作指南
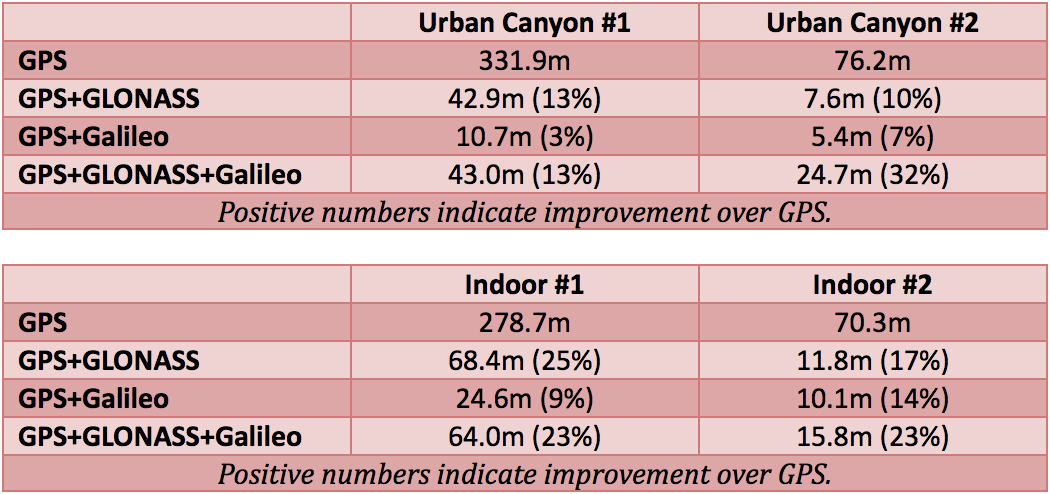
参考资源链接:[GnssLevelHight:高精度高程拟合工具](https://wenku.csdn.net/doc/6412b6bdbe7fbd1778d47cee?spm=1055.2635.3001.10343)
# 1. GNSS高程数据精度的重要性
精确的GNSS(全球导航卫星系统)高程数据对于测绘、地理信息系统(GIS)、灾害监测、地球科学等多个领域至关重要。误差很小的变化可能会影响到工
【PN532与物联网设备集成】:智能场景应用,一触即发
参考资源链接:[PN532固件V1.6详细教程:集成NFC通信模块指南](https://wenku.csdn.net/doc/6412b4cabe7fbd1778d40d3d?spm=1055.2635.3001.10343)
# 1. PN532概述及其在物联网中的作用
## 1.1 PN532简介
PN532是由恩智浦半导体开发的一款高度集成的NFC控制器,它能够执行多种无线通信功能,包括读取RFID标签、实现无线充电以及进行点对点通信等。PN5
SystemVerilog习题高级篇:深化理解与系统化学习方法

参考资源链接:[SystemVerilog验证:绿皮书第三版课后习题解答](https://wenku.csdn.net/doc/644b7ea5ea0840391e5597b3?spm=1055.2635.3001.10343)
# 1. SystemVerilog习题高级篇概述
SystemVerilog作为硬件描述语言的集大
台达PLC编程常见错误剖析:新手到专家的防错指南
参考资源链接:[台达PLC ST编程语言详解:从入门到精通](https://wenku.csdn.net/doc/6401ad1acce7214c316ee4d4?spm=1055.2635.3001.10343)
# 1. 台达PLC编程简介
台达PLC(Programmable Logic Controller)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )