有赞搜索系统:从架构1.0到2.0的演进之路
44 浏览量
更新于2024-08-27
收藏 268KB PDF 举报
"有赞搜索系统的架构演进"
有赞搜索系统是针对公司内部搜索应用及NoSQL存储应用的平台,旨在高效支持检索和多维过滤功能。它服务于大量的检索业务和近百亿的数据量,涵盖了商品管理、订单检索、粉丝筛选等场景。面对多样化的需求和大数据的挑战,该平台的架构经历了从初期的简单部署到复杂演进的过程。
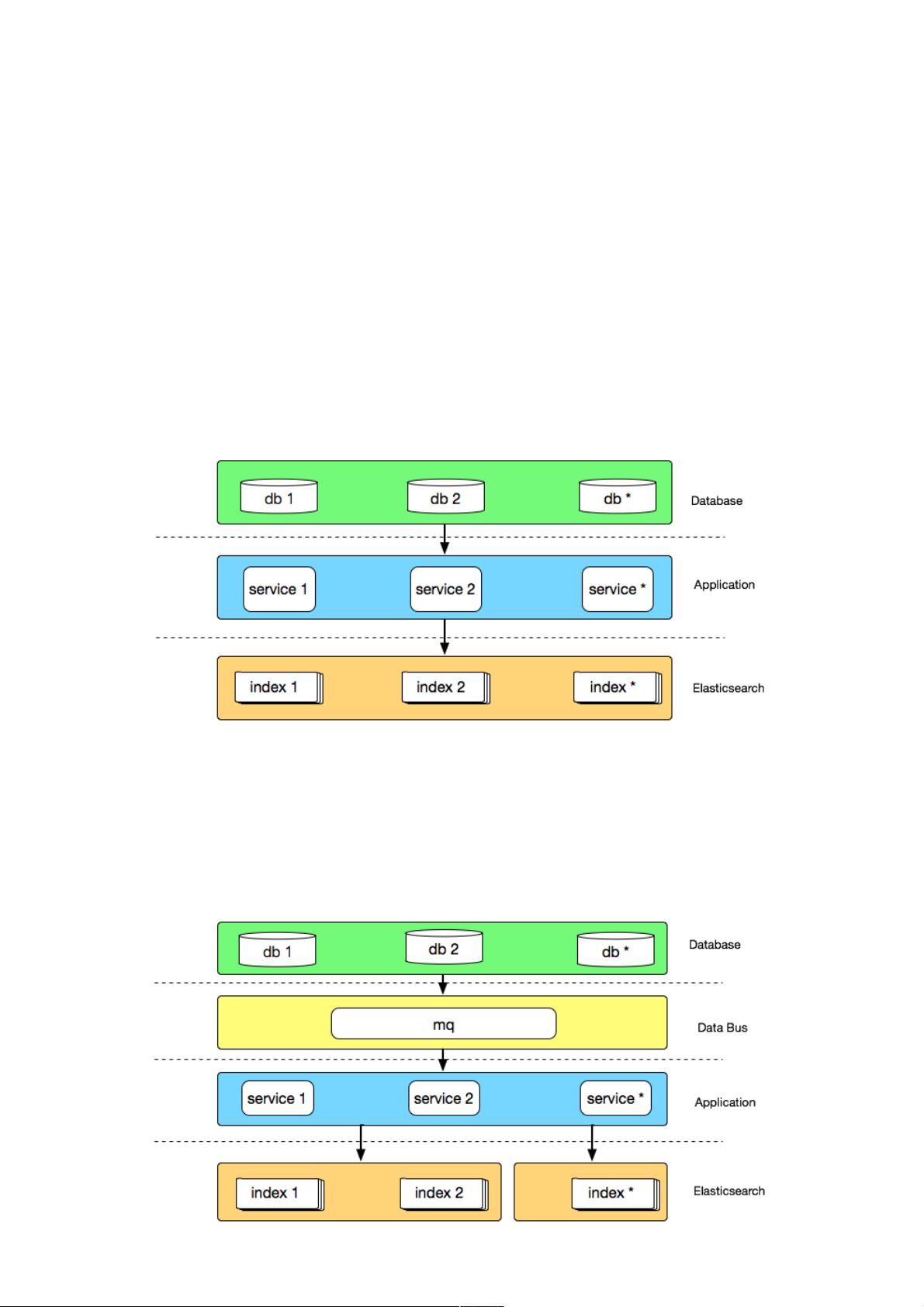
早期的架构,即架构1.0,基于Elasticsearch构建,采用几台高配虚拟机组成集群。数据通过Canal从数据库同步到Elasticsearch。尽管这种模式在初期能够快速响应业务增长,但存在明显问题:同步程序与业务库紧密耦合,数据库性能可能因多Canal订阅而下降,且未进行物理隔离,导致了稳定性问题,例如在大促期间的内存溢出故障。
为了解决这些问题,演进至架构2.0。在这个阶段,引入了数据总线将数据变更同步到消息队列(MQ),同步应用通过消费MQ消息来异步处理数据,降低了与业务库的耦合,并减少了对数据库的影响。同时,这也解决了多个Canal订阅同一数据库表的问题,提升了效率。此外,通过物理隔离,增强了Elasticsearch集群的稳定性,防止单个索引的问题影响全局。
随着业务的进一步发展,有赞搜索平台引入了"高级搜索"(AdvancedSearch)功能,以应对更复杂的查询需求。普通的布尔查询不足以满足某些中心化流量入口的需求,因此,平台可能采用了更先进的查询语法和过滤策略,例如使用自定义脚本、评分函数或者更复杂的聚合分析,以提供更精准和定制化的搜索结果。
为了保证性能、可扩展性和可靠性,有赞搜索团队持续优化平台,降低运维成本并简化业务开发流程。这可能涉及到集群的水平扩展、索引分片策略调整、热温冷数据分离、自动负载均衡、故障恢复机制以及监控报警系统的完善。
在未来的架构演进中,可能会继续探索和应用新的技术,如使用Kubernetes进行容器化管理,提升资源利用率;引入机器学习算法进行智能推荐和个性化搜索;或者采用更先进的数据同步工具,如Kafka或Debezium,提高数据实时性;以及可能的云原生转型,利用云服务弹性伸缩和自动化运维能力。
总结来说,有赞搜索系统的架构演进是一个不断应对挑战、创新优化的过程,它反映了企业在应对大数据和复杂业务需求时,如何通过技术升级和架构改进来提升搜索服务的效率、稳定性和用户体验。
有赞搜索系统的架构演进有赞搜索系统的架构演进
有赞搜索平台是一个面向公司内部各项搜索应用以及部分 NoSQL 存储应用的 PaaS 产品,帮助应用合理高效的支持检索和多
维过滤功能,有赞搜索平台目前支持了大大小小一百多个检索业务,服务于近百亿数据。
在为传统的搜索应用提供高级检索和大数据交互能力的同时,有赞搜索平台还需要为其他比如商品管理、订单检索、粉丝筛选
等海量数据过滤提供支持,从工程的角度看,如何扩展平台以支持多样的检索需求是一个巨大的挑战。
我是有赞搜索团队的第一位员工,也有幸负责设计开发了有赞搜索平台到目前为止的大部分功能特性,我们搜索团队目前主要
负责平台的性能、可扩展性和可靠性方面的问题,并尽可能降低平台的运维成本以及业务的开发成本。
Elasticsearch
Elasticsearch 是一个高可用分布式搜索引擎,一方面技术相对成熟稳定,另一方面社区也比较活跃,因此我们在搭建搜索系
统过程中也是选择了 Elasticsearch 作为我们的基础引擎。
架构1.0
时间回到 2015 年,彼时运行在生产环境的有赞搜索系统是一个由几台高配虚拟机组成的 Elasticsearch 集群,主要运行商品
和粉丝索引,数据通过 Canal 从 DB 同步到 Elasticsearch,大致架构如下:
通过这种方式,在业务量较小时,可以低成本的快速为不同业务索引创建同步应用,适合业务快速发展时期,但相对的每个同
步程序都是单体应用,不仅与业务库地址耦合,需要适应业务库快速的变化,如迁库、分库分表等,而且多个 canal 同时订阅
同一个库,也会造成数据库性能的下降。
另外 Elasticsearch 集群也没有做物理隔离,有一次促销活动就因为粉丝数据量过于庞大导致 Elasticsearch 进程 heap 内存耗
尽而 OOM,使得集群内全部索引都无法正常工作,这给我上了深深的一课。
架构 2.0
我们在解决以上问题的过程中,也自然的沉淀出了有赞搜索的 2.0 版架构,大致架构如下:
首先数据总线将数据变更消息同步到 mq,同步应用通过消费 mq 消息来同步业务库数据,借数据总线实现与业务库的解耦,
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-11-19 上传
点击了解资源详情
2018-09-30 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38691742
- 粉丝: 4
- 资源: 903
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
