有赞搜索系统:架构演进与挑战
194 浏览量
更新于2024-08-28
收藏 268KB PDF 举报
有赞搜索系统的架构演进是一个逐步优化的过程,从早期的挑战到后来的解决方案,体现了技术团队对高效、稳定和可扩展性的追求。最初的架构1.0主要依赖于Elasticsearch集群,该集群由几台高性能虚拟机组成,用于商品和粉丝索引的数据同步。数据通过Canal从数据库实时推送至Elasticsearch,这种架构在业务规模较小的情况下易于部署,但存在明显的局限性。
首先,单体同步应用与业务库紧密耦合,不适应快速变化的数据库结构调整,如库迁移或分库分表,这可能导致性能瓶颈和维护困难。其次,未做物理隔离的Elasticsearch集群在面对大规模数据时,如粉丝促销期间,容易因内存溢出导致服务中断。
为了解决这些问题,有赞搜索团队引入了架构2.0。这一版本的核心改进是引入了数据总线,通过消息队列MQ将数据变更通知给同步应用,实现了与业务数据库的解耦。这样不仅降低了对数据库性能的影响,还避免了多实例监听同一个表的资源浪费。数据总线的设计使得系统更加灵活,能够适应不断变化的业务需求。
随着业务的扩展和复杂性提升,有赞搜索平台引入了高级搜索功能(AdvancedSearch),以满足对搜索结果进行精细化控制的需求。这涉及到对用户行为、产品属性等多维度信息的处理,使得搜索结果更具针对性,提升了用户体验。
此外,有赞搜索团队还专注于平台的性能优化、可扩展性和可靠性,致力于降低运维成本和业务开发成本,确保系统的长期稳定运行。他们在选择基础引擎时,考虑到了Elasticsearch的技术成熟度和活跃的社区支持,但在实际应用中,根据业务需求不断调整和优化架构,以应对不断增长的数据量和多样化检索需求。
有赞搜索系统的架构演进是一个不断迭代、学习和适应的过程,它反映了技术团队对于解决实际业务挑战和提升整体搜索服务效能的深入思考。通过不断的技术革新和实践经验,有赞搜索平台得以支持上百个检索业务,服务着近百亿的数据量,为公司的各项内部搜索应用提供了强大且灵活的支持。
有赞搜索系统的架构演进有赞搜索系统的架构演进
有赞搜索平台是一个面向公司内部各项搜索应用以及部分 NoSQL 存储应用的 PaaS 产品,帮助应用合理高效的支持检索和多
维过滤功能,有赞搜索平台目前支持了大大小小一百多个检索业务,服务于近百亿数据。
在为传统的搜索应用提供高级检索和大数据交互能力的同时,有赞搜索平台还需要为其他比如商品管理、订单检索、粉丝筛选
等海量数据过滤提供支持,从工程的角度看,如何扩展平台以支持多样的检索需求是一个巨大的挑战。
我是有赞搜索团队的第一位员工,也有幸负责设计开发了有赞搜索平台到目前为止的大部分功能特性,我们搜索团队目前主要
负责平台的性能、可扩展性和可靠性方面的问题,并尽可能降低平台的运维成本以及业务的开发成本。
Elasticsearch
Elasticsearch 是一个高可用分布式搜索引擎,一方面技术相对成熟稳定,另一方面社区也比较活跃,因此我们在搭建搜索系
统过程中也是选择了 Elasticsearch 作为我们的基础引擎。
架构1.0
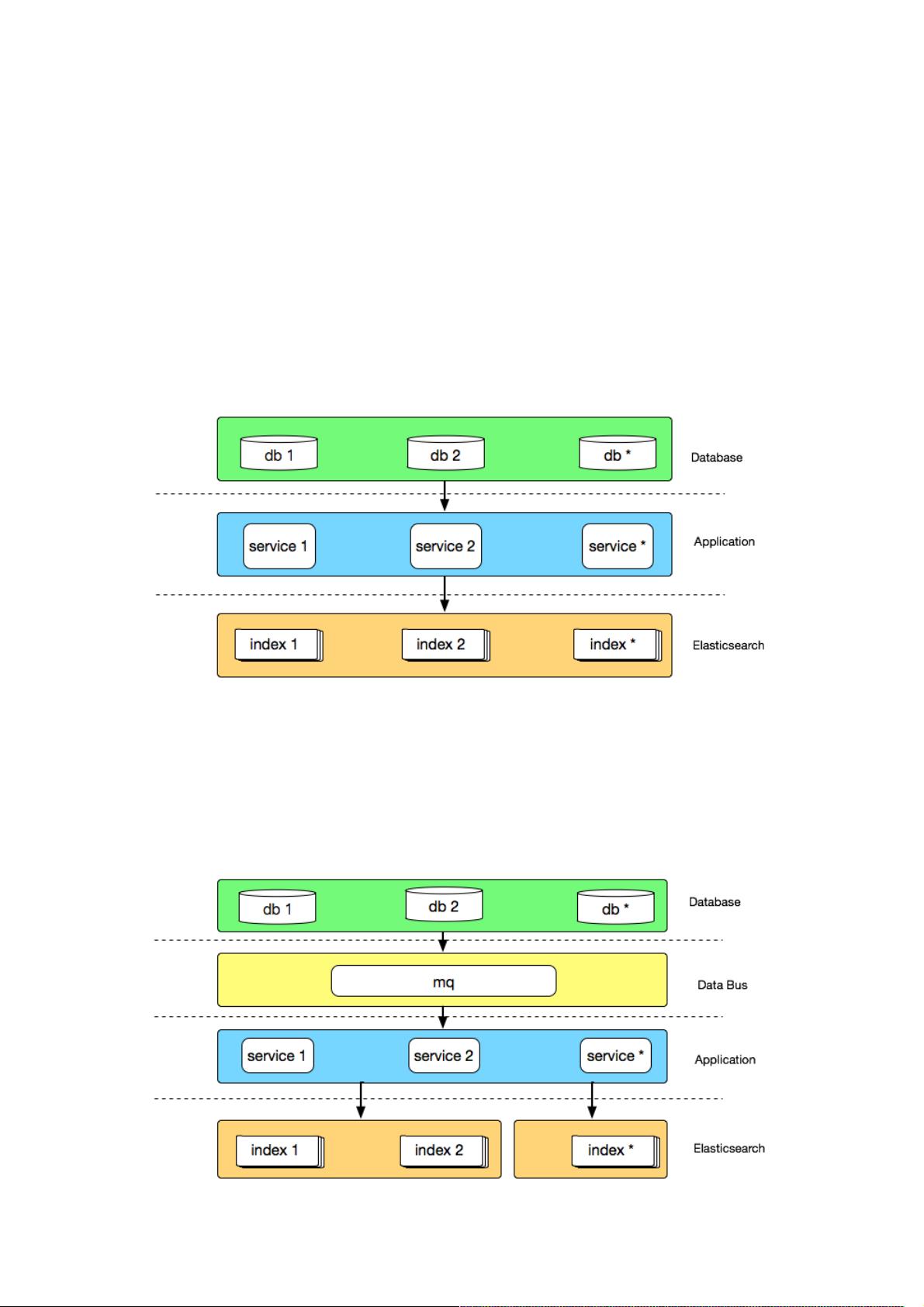
时间回到 2015 年,彼时运行在生产环境的有赞搜索系统是一个由几台高配虚拟机组成的 Elasticsearch 集群,主要运行商品
和粉丝索引,数据通过 Canal 从 DB 同步到 Elasticsearch,大致架构如下:
通过这种方式,在业务量较小时,可以低成本的快速为不同业务索引创建同步应用,适合业务快速发展时期,但相对的每个同
步程序都是单体应用,不仅与业务库地址耦合,需要适应业务库快速的变化,如迁库、分库分表等,而且多个 canal 同时订阅
同一个库,也会造成数据库性能的下降。
另外 Elasticsearch 集群也没有做物理隔离,有一次促销活动就因为粉丝数据量过于庞大导致 Elasticsearch 进程 heap 内存耗
尽而 OOM,使得集群内全部索引都无法正常工作,这给我上了深深的一课。
架构 2.0
我们在解决以上问题的过程中,也自然的沉淀出了有赞搜索的 2.0 版架构,大致架构如下:
首先数据总线将数据变更消息同步到 mq,同步应用通过消费 mq 消息来同步业务库数据,借数据总线实现与业务库的解耦,
引入数据总线也可以避免多个 canal 监听消费同一张表 binlog 的虚耗。
高级搜索(Advanced Search)
下载后可阅读完整内容,剩余3页未读,立即下载
2018-09-30 上传
2018-11-19 上传
2023-12-04 上传
2023-08-02 上传
2023-06-09 上传
2024-01-25 上传
2023-05-15 上传
2023-10-26 上传
2023-09-06 上传

weixin_38688550
- 粉丝: 7
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
