数据网络中的排队论深入解析
"这篇资料是关于Queueing Theory(排队论)的高级教程,结合了概率论的基础知识,探讨在数据网络中的应用。"
在数据网络领域,排队论是一门非常重要的理论,它研究的是系统中等待服务的个体(如数据包、用户请求等)形成队列的规律和性能。这个理论在分析网络流量、优化资源分配以及预测系统性能等方面有着广泛的应用。本文将深入探讨排队论的一些核心概念,并基于概率论基础进行讲解。
首先,概率论是排队论的基石,其基本概念包括样本空间(Samplespace S)和事件(Event)。样本空间S是指实验所有可能结果的集合。例如,投掷一枚骰子,样本空间S就是{1,2,3,4,5,6};而灯泡的寿命,样本空间S可以是所有大于零的实数{x∈R|x>0}。
事件是样本空间的子集,通常用大写字母表示,如A或B。如果实验结果属于事件A,我们就说事件A发生了。例如,投掷骰子得到偶数,事件A就是{2,4,6};而灯泡寿命至少为3000小时,事件A则是{x∈R|x>3000}。
在概率论中,事件有多种组合方式:
1. 并集(Union)表示"A或B",即A∪B,包含了属于A或B的所有结果。
2. 交集(Intersection)表示"A和B",即A∩B,指同时满足A和B条件的结果。
3. 如果两个事件A和B的交集为空,即A∩B=φ,我们说它们互斥(Mutually Exclusive),表示这两个事件不会同时发生。
4. 补集(Complement)表示"非A",即¯A,代表不属于A的所有结果。
此外,一组事件构成样本空间的划分(Partition),当满足以下两个条件时:
1. 事件之间互斥,即任意两个事件的交集为空。
2. 所有事件的并集等于整个样本空间。
在数据网络的排队论中,这些概念用于分析和建模数据包在网络中的传输过程,包括它们到达的时间分布、等待时间、服务时间和队列长度等。通过这些分析,我们可以预测网络拥塞情况,设计更有效的调度策略,以提高网络的效率和服务质量。例如,通过理解服务时间的分布,可以优化服务器的资源配置,减少等待时间,从而改善用户体验。同时,也可以评估不同流量控制算法对整体网络性能的影响。
这篇教程深入浅出地介绍了排队论与概率论的结合,为理解和应用数据网络中的排队现象提供了理论基础。对于网络工程师和研究人员来说,掌握这些知识对于优化网络性能和设计高效系统至关重要。
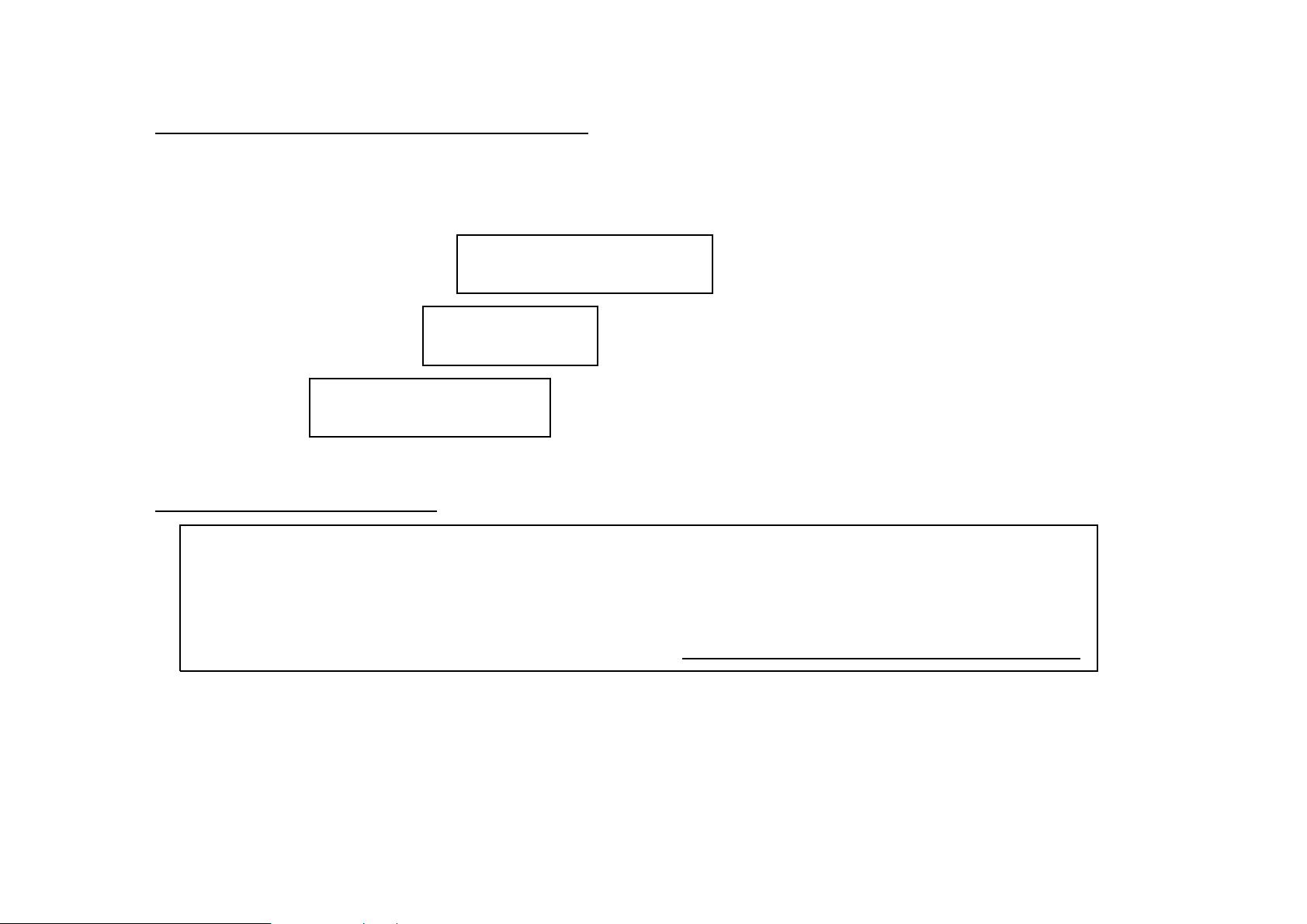
J. Virtamo 38.3143 Queueing Theory / Probability Theory 16
Parameters of dist ribut ions
Expectation
Denoted by E[X] =
¯
X
Continuous distribution:
E[X] =
Z
∞
−∞
x f(x) dx
Discrete distribution:
E[X] =
X
i
x
i
p
i
In general:
E[X] =
Z
∞
−∞
x dF(x)
dF (x) is the probability of the interval dx
Properties of expectation
E[cX] = cE[X] c constant
E[X
1
+ · · · X
n
] = E[X
1
] + · · · + E[X
n
] always
E[X · Y ] = E[X] · E[Y ] only when X and Y are independent




剩余267页未读,继续阅读
2013-06-04 上传
2023-04-07 上传
2023-08-26 上传
2023-10-19 上传
2024-06-16 上传
2024-03-28 上传
2023-08-26 上传
2023-05-25 上传

creasywu
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
