
Flink完美搭档:数据存储层上的完美搭档:数据存储层上的Pravega
本文将从大数据架构变迁历史,Pravega 简介,Pravega 进阶特性以及车联网使用场景这四个方面介绍 Pravega,重点介绍
DellEMC 为何要研发 Pravega,Pravega 解决了大数据处理平台的哪些痛点以及与 Flink 结合会碰撞出怎样的火花。
大数据架构变迁
Lambda 架构之痛
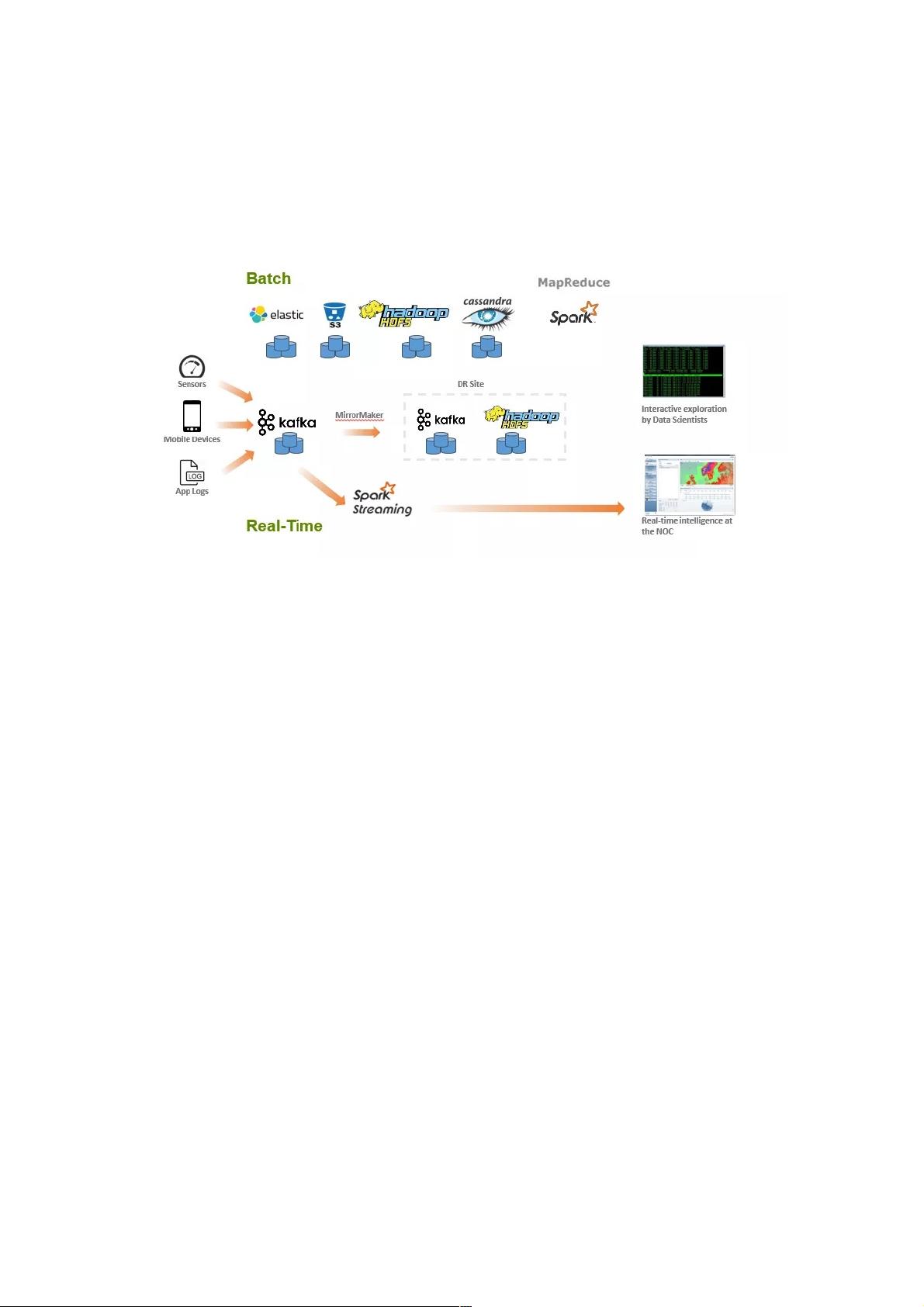
如何有效地提取和提供数据,是大数据处理应用架构是否成功的关键之处。由于处理速度和频率的不同,数据的摄取需要通过
两种策略来进行。上图就是典型的 Lambda架构:把大数据处理架构分为批处理和实时流处理两套独立的计算基础架构。
对于实时处理来说,来自传感器,移动设备或者应用日志的数据通常写入消息队列系统(如 Kafka), 消息队列负责为流处理应
用提供数据的临时缓冲。然后再使用 Spark Streaming 从 Kafka 中读取数据做实时的流计算。但由于 Kafka 不会一直保存历
史数据,因此如果用户的商业逻辑是结合历史数据和实时数据同时做分析,那么这条流水线实际上是没有办法完成的。因此为
了补偿,需要额外开辟一条批处理的流水线,即图中" Batch "部分。
对于批处理这条流水线来说,集合了非常多的的开源大数据组件如 ElasticSearch, Amazon S3, HDFS, Cassandra 以及 Spark
等。主要计算逻辑是是通过 Spark 来实现大规模的 Map-Reduce 操作,优点在于结果比较精确,因为可以结合所有历史数据
来进行计算分析,缺点在于延迟会比较大。
这套经典的大数据处理架构可以总结出三个问题:
两条流水线处理的延迟相差较大,无法同时结合两条流水线进行迅速的聚合操作,同时结合历史数据和实时数据的处理性能低
下。
数据存储成本大。而在上图的架构中,相同的数据会在多个存储组件中都存在一份或多份拷贝,数据的冗余无疑会大大增加企
业客户的成本。并且开源存储的数据容错和持久化可靠性一直也是值得商榷的地方,对于数据安全敏感的企业用户来说,需要
严格保证数据的不丢失。
重复开发。同样的处理流程被两条流水线进行了两次,相同的数据仅仅因为处理时间不同而要在不同的框架内分别计算一次,
无疑会增加数据开发者重复开发的负担。
流式存储的特点
在正式介绍 Pravega 之前,首先简单谈谈流式数据存储的一些特点。
如果我们想要统一流批处理的大数据处理架构,其实对存储有混合的要求。
下载后可阅读完整内容,剩余8页未读,立即下载

weixin_38593380
- 粉丝: 4
- 资源: 964
 我的内容管理
展开
我的内容管理
展开







最新资源
- 十种常见电感线圈电感量计算公式详解
- 军用车辆:CAN总线的集成与优势
- CAN总线在汽车智能换档系统中的作用与实现
- CAN总线数据超载问题及解决策略
- 汽车车身系统CAN总线设计与应用
- SAP企业需求深度剖析:财务会计与供应链的关键流程与改进策略
- CAN总线在发动机电控系统中的通信设计实践
- Spring与iBATIS整合:快速开发与比较分析
- CAN总线驱动的整车管理系统硬件设计详解
- CAN总线通讯智能节点设计与实现
- DSP实现电动汽车CAN总线通讯技术
- CAN协议网关设计:自动位速率检测与互连
- Xcode免证书调试iPad程序开发指南
- 分布式数据库查询优化算法探讨
- Win7安装VC++6.0完全指南:解决兼容性与Office冲突
- MFC实现学生信息管理系统:登录与数据库操作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


