
T. Fischer, C. Krauss / European Journal of Operational Research 270 (2018) 654–669 657
Fig. 1. Construction of input sequences for LSTM networks (both, feature vector and sequences, are shown transposed).
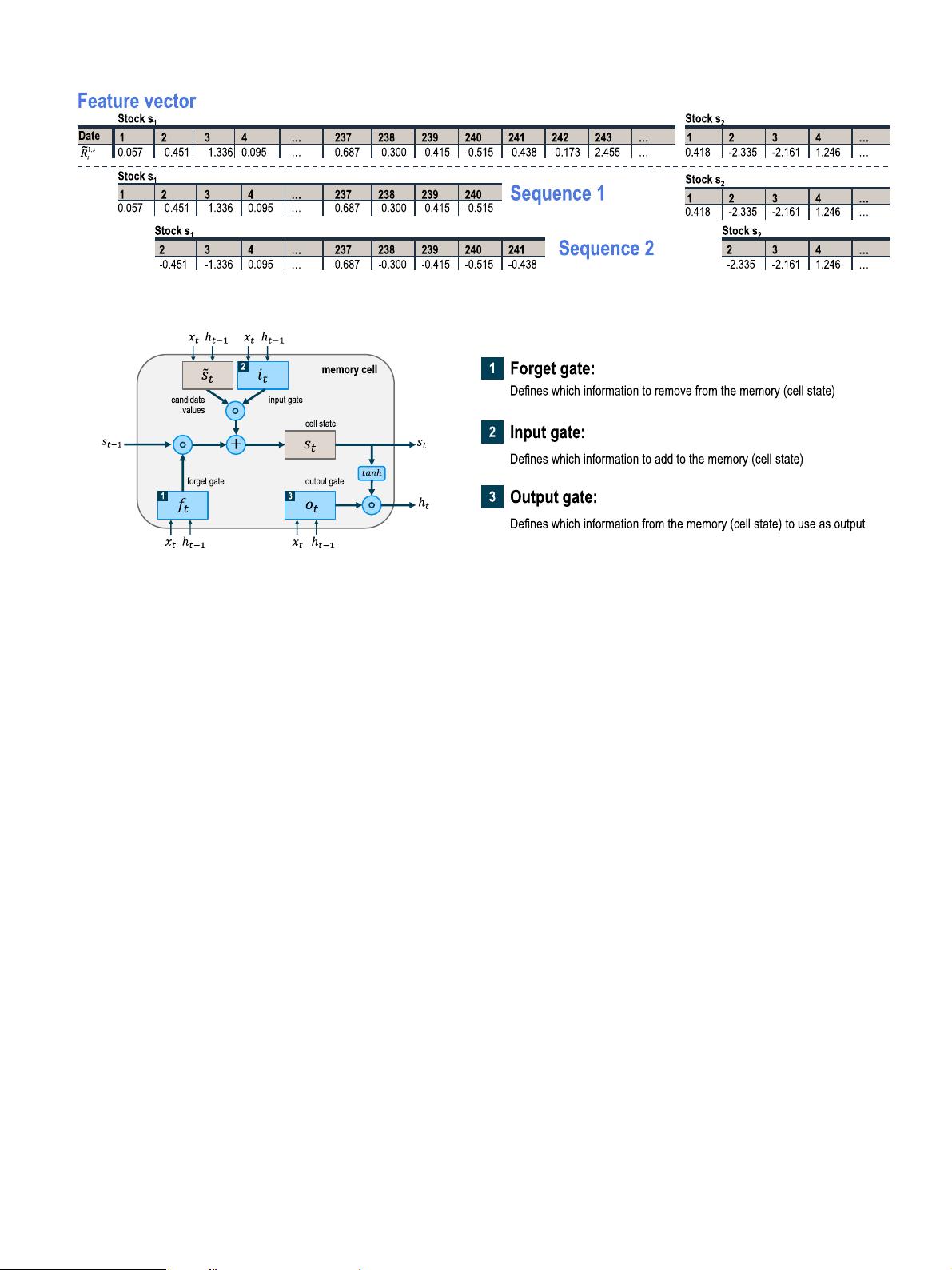
Fig. 2. Structure of LSTM memory cell following Graves (2013) and Olah (2015) .
consisting of so called memory cells. Each of the memory cells has
three gates maintaining and adjusting its cell state s
t
: a forget gate
( f
t
), an input gate ( i
t
), and an output gate ( o
t
). The structure of a
memory cell is illustrated in Fig. 2 .
At every timestep t , each of the three gates is presented with
the input x
t
(one element of the input sequence) as well as the
output h
t−1
of the memory cells at the previous timestep t −1 .
Hereby, the gates act as filters, each fulfilling a different purpose:
•
The forget gate defines which information is removed from the
cell state.
•
The input gate specifies which information is added to the cell
state.
•
The output gate specifies which information from the cell state
is used as output.
The equations below are vectorized and describe the update of the
memory cells in the LSTM layer at every timestep t . Hereby, the
following notation is used:
•
x
t
is the input vector at timestep t .
•
W
f , x
, W
f , h
, W
˜
s ,x
, W
˜
s
,h
, W
i , x
, W
i , h
, W
o , x
, and W
o , h
are weight ma-
trices.
•
b
f
, b
˜
s
, b
i
, and b
o
are bias vectors.
•
f
t
, i
t
, and o
t
are vectors for the activation values of the respec-
tive gates.
•
s
t
and
˜
s
t
are vectors for the cell states and candidate values.
•
h
t
is a vector for the output of the LSTM layer.
During a forward pass, the cell states s
t
and outputs h
t
of the LSTM
layer at timestep t are calculated as follows:
In the first step, the LSTM layer determines which information
should be removed from its previous cell states s
t−1
. Therefore, the
activation values f
t
of the forget gates at timestep t are computed
based on the current input x
t
, the outputs h
t−1
of the memory cells
at the previous timestep ( t − 1 ), and the bias terms b
f
of the for-
get gates. The sigmoid function finally scales all activation values
into the range between 0 (completely forget) and 1 (completely
remember):
f
t
= sigmoid(W
f,x
x
t
+ W
f,h
h
t−1
+ b
f
) . (3)
In the second step, the LSTM layer determines which information
should be added to the network’s cell states ( s
t
). This procedure
comprises two operations: first, candidate values
˜
s
t
, that could po-
tentially be added to the cell states, are computed. Second, the ac-
tivation values i
t
of the input gates are calculated:
˜
s
t
= tanh (W
˜
s
,x
x
t
+ W
˜
s
,h
h
t−1
+ b
˜
s
) , (4)
i
t
= sigmoid(W
i,x
x
t
+ W
i,h
h
t−1
+ b
i
) . (5)
In the third step, the new cell states s
t
are calculated based on the
results of the previous two steps with ◦ denoting the Hadamard
(elementwise) product:
s
t
= f
t
◦ s
t−1
+ i
t
◦
˜
s
t
. (6)
In the last step, the output h
t
of the memory cells is derived as
denoted in the following two equations:
o
t
= sigmoid(W
o,x
x
t
+ W
o,h
h
t−1
+ b
o
) , (7)
h
t
= o
t
◦ tanh (s
t
) . (8)
When processing an input sequence, its features are presented
timestep by timestep to the LSTM network. Hereby, the input at
each timestep t (in our case, one single standardized return) is pro-
cessed by the network as denoted in the equations above. Once the
last element of the sequence has been processed, the final output
for the whole sequence is returned.
During training, and similar to traditional feed-forward net-
works, the weights and bias terms are adjusted in such a way that
they minimize the loss of the specified objective function across
剩余15页未读,继续阅读

Quant0xff
- 粉丝: 1w+
- 资源: 459
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


