GPU架构上高效reduce操作实现
196 浏览量
更新于2024-07-14
收藏 339KB PDF 举报
"这篇论文《Efficient Implementation of Reductions on GPU Architectures》是 Stephen W. Timcheck 在2017年春季于美国阿克伦大学完成的荣誉学院研究项目,探讨了在GPU架构上实现高效缩减操作的方法。该研究可能对优化GPU计算性能,特别是在大规模并行计算和数据处理中的应用具有重要意义。论文发表在阿克伦大学的IdeaExchange平台上,鼓励读者通过反馈调查来支持其进一步发展。"
在计算机科学领域,GPU(图形处理器)已经被广泛应用于高性能计算,尤其是在处理大数据集和执行并行计算任务时。GPU架构的并行处理能力使其成为科学计算、机器学习和数据分析的理想选择。然而,充分利用GPU的潜力需要优化算法,其中“缩减”操作是一种关键的计算模式。
缩减操作是将一组数值聚合到一个单一结果的过程,如求和、最大值或最小值。在GPU上高效地执行这种操作需要考虑内存访问模式、线程同步以及计算资源的利用。Timcheck的研究很可能深入分析了这些方面,提出优化策略,以减少通信开销、提高内存带宽利用率和减少计算时间。
可能涉及的知识点包括:
1. **GPU编程模型**:CUDA或OpenCL等编程框架,以及如何通过它们来编写针对GPU优化的代码。
2. **并行计算**:理解并行计算的基本原理,包括线程块、网格和线程同步。
3. **内存层次结构**:GPU的全局内存、共享内存和寄存器的使用,以及如何有效地管理这些内存以提升性能。
4. ** warp shuffle 操作**:在GPU内核中进行数据交换的一种高效机制,可用于优化缩减操作。
5. **负载均衡**:确保所有计算单元的工作量分配均匀,避免某些单元空闲。
6. **同步问题**:在并行环境中,如何正确同步线程以避免数据竞争和死锁。
7. **算法优化**:可能讨论了不同的缩减算法,如树形缩减、条带化缩减等,以及它们在不同情况下的效率。
8. **性能分析**:如何使用工具(如NVIDIA的nvprof)进行性能分析,识别瓶颈并进行改进。
9. **硬件限制与性能边界**:探讨GPU架构的限制,如最大线程数量和并发执行单元,以及如何在这些限制下最大化性能。
10. **实验设计与结果**:可能包含了针对不同数据集和工作负载的实验,比较优化前后性能的提升。
Timcheck的研究为GPU上的高效缩减操作提供了理论基础和实践指导,对于理解GPU编程和优化,并行算法设计具有实际价值。
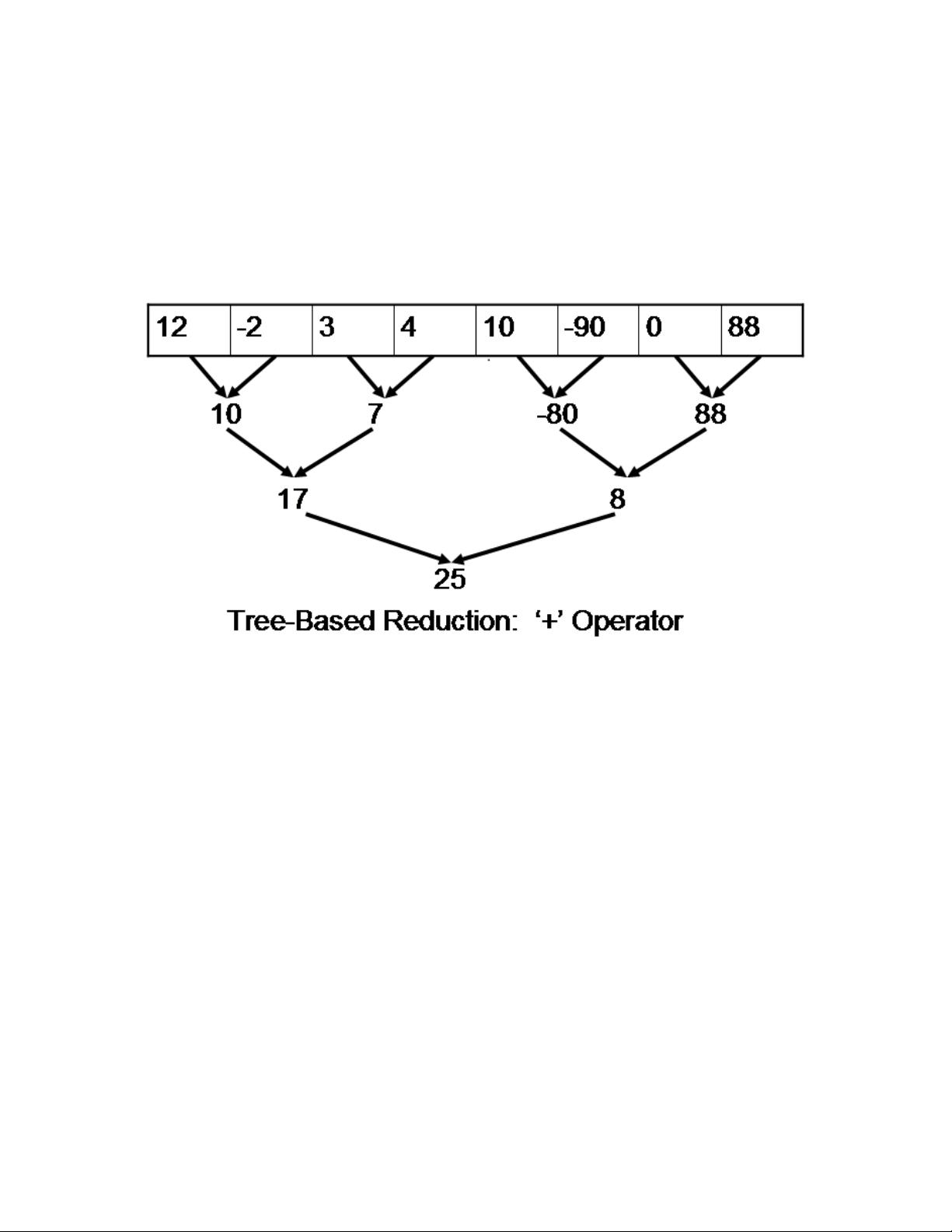
3
that is a single instruction is run on multiple points of data at once. To add two arrays of integers
element-wise on a GPU, one instruction can be run to add the elements where every thread adds
the two elements that it is assigned to. This provides a result not requiring a sequential "for"
loop iterating over all elements like on most CPUs.
For example, an array of integers is produced from some source and the user would like
to have the summation of these results, such as the problem described in the introduction. The
summation of the elements would be a reduction using the '+' operator on the array. A tree based
SIMD execution of the reduction would be similar to the following figure:
The GPU conceptually runs one SIMD operation per level of the tree. This reduces the
number of operations to the height of the tree, O(log(n)), rather than the total number of elements,
O(n). For example, the sequential method in the introduction takes 8 operations to complete
whereas the tree based SIMD reduction needs only 3 operations. However, CUDA systems have
many other considerations determining how well these reductions perform which we will explore
in Chapter 2.
Background - MERCATOR
In addition to making reductions efficient, we also wanted our implementations to be
accessible to users without extensive parallel programming backgrounds. To do this, we targeted
the MERCATOR (Mapping EnumeRATOR for CUDA) system for implementation of our
reductions.
MERCATOR, developed by Stephen Cole and Dr. Jeremy Buhler, is a library which aims
to make data-flow applications easier to implement on NVIDIA GPUs [4]. MERCATOR
supports a modular approach for implementing CUDA kernels that allows for dynamically
varying numbers of inputs and outputs per module. With MERCATOR one can easily construct
various applications through the use of its modular design. MERCATOR handles all of the
memory management and module scheduling for every module in the pipeline of the application.
The following figure shows a schematic of a simple MERCATOR application pipeline [4]:
剩余22页未读,继续阅读
2022-03-03 上传
2020-01-10 上传
2023-06-11 上传
2023-05-19 上传
2023-05-27 上传
2023-05-22 上传
2023-07-14 上传
2023-05-20 上传
2023-06-08 上传

weixin_38526979
- 粉丝: 6
- 资源: 964
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
