Web并发模型:提升吞吐量的关键分析
需积分: 7 21 浏览量
更新于2024-07-26
收藏 609KB PPTX 举报
"本文主要探讨了Web并发模型中的核心概念,包括并发性、并行性和吞吐量,并分析了它们在Web服务中的重要性。同时,文中提到了IO密集型请求对系统性能的影响以及如何通过并发提高吞吐量。"
在Web服务中,理解和优化并发模型对于提升系统性能至关重要。并发(concurrency)是指在同一时间段内,系统能够处理多个任务的能力,而不是这些任务必须连续执行。这种能力通常通过CPU时间片轮转实现,使得多个请求可以在单个CPU核心上交替运行。例如,当一个服务器接收到四个请求时,即使只有一个CPU核心,它也可以通过快速切换请求的状态,使得每个请求看似几乎同时进行。
并行性(parallelism)则更进一步,它是在多核或多个处理器环境中,真正地同时执行多个任务。每个CPU核心独立处理一个任务,从而实现真正的并行执行。例如,如果一个服务器有四个CPU核心,它可以同时处理四个请求,显著提高了处理速度。
吞吐量(throughput)是衡量系统性能的关键指标,表示单位时间内服务器处理的请求量,通常以请求每秒(requests per second, rps)来衡量。更高的吞吐量意味着服务器能够处理更多的用户请求。
除了这些基本概念,文中还提到了影响吞吐量的其他因素,如每个请求的处理时间(latency)、服务器可处理并发请求数量(并发workers)以及垃圾回收(Garbage Collection, GC)等。例如,一个请求的延迟时间越短,服务器的吞吐量理论上就越高;而垃圾回收过程会占用CPU资源,可能降低吞吐量。
对于IO密集型的Web应用,例如涉及到数据库查询、文件读写或者网络通信的任务,大部分时间CPU都在等待IO操作完成。在这种情况下,增加并发可以有效利用CPU的空闲时间,提高系统吞吐量。文中通过例子说明,即使是顺序执行的10个IO密集型请求,通过并发处理,也能显著减少总执行时间,从而提高吞吐量。
理解并发模型和并行性对于优化Web服务性能至关重要,尤其是在处理IO密集型请求时。通过合理设计和调整并发策略,可以有效地提升服务器处理请求的能力,满足更多用户的访问需求。
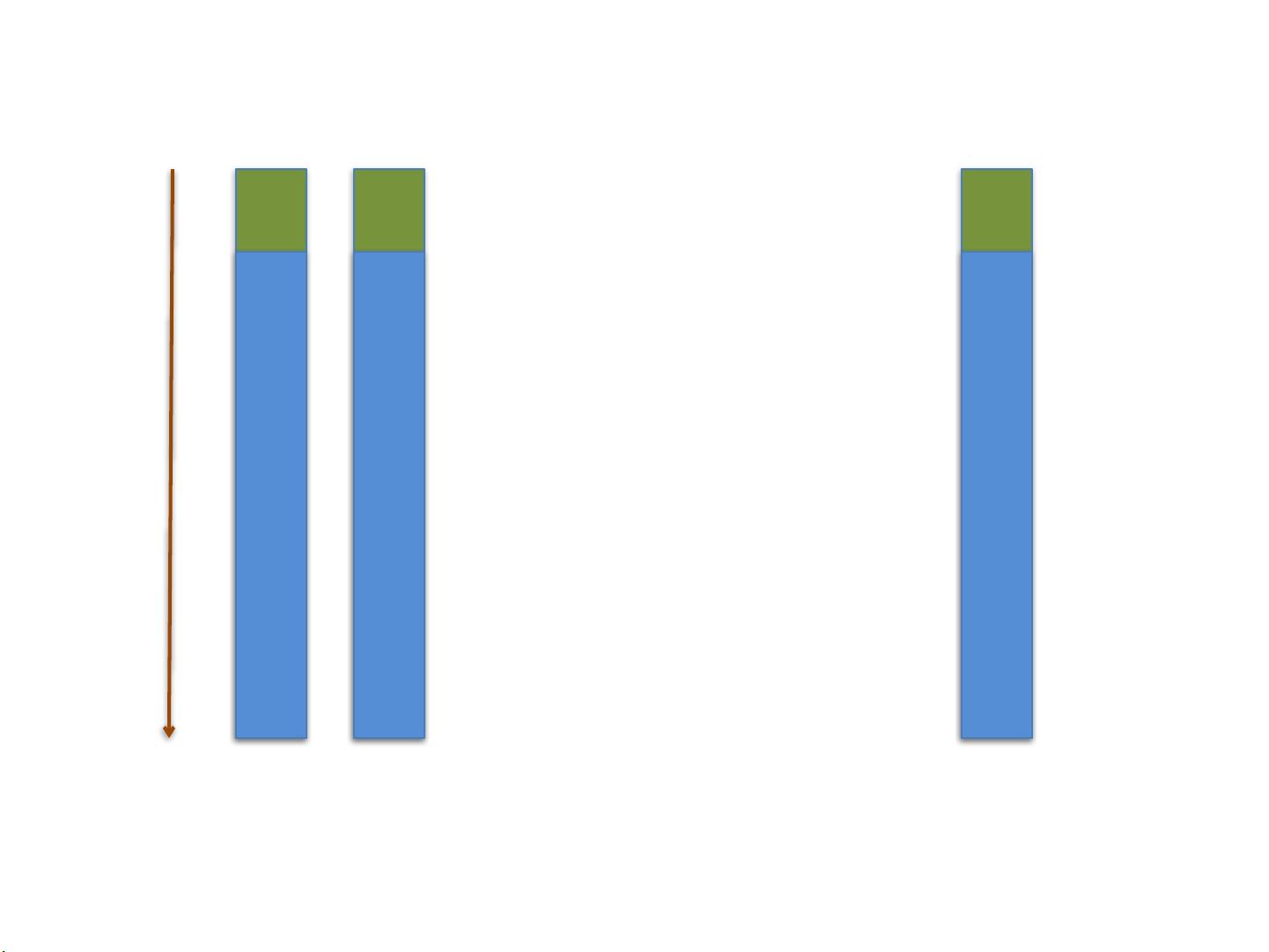
555555
!
顺序执行 ! 个请求,每个请求 !! ,总共 执行完毕
并发执行 ! 个请求,每个请求分配 ! 的时间片
!! 之后 处于空闲状态, 7! 到 9! 请求全部执行完毕
吞吐量得到极大提高
./ ./ ./


剩余59页未读,继续阅读
点击了解资源详情
点击了解资源详情
105 浏览量
点击了解资源详情
597 浏览量
509 浏览量
点击了解资源详情
692 浏览量

苍_狼
- 粉丝: 3
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- SBR Student ViewPager.rar
- NUMUNIQUE:返回数组中的唯一元素以及重复值的所有索引。-matlab开发
- mmm-systemtemperature:在Magic Mirror上显示Raspberry Pi的温度
- 地产营销策划成功案例
- pyhpc-benchmarks:一套基准测试,可测试Python最流行的高性能库的顺序CPU和GPU性能
- michaeldong1024.github.io
- Red-Social-Recetas:Red social de recetas hecho con Laravel 7和VueJS,mi入门proyecto FullStack con el框架Laravel
- GetExtension:获取文件的扩展名。-matlab开发
- bst_d3:D3中的BST
- conversator-dart
- 酒店修图
- 实现单选按钮效果源码下载
- 千万富翁的思维方式
- UltraHardcoreAssistent
- 人工智能期末考题库(18级保研师兄整理)
- jquery手指滑动刻度尺效果
