R语言实战:聚类分析与无监督机器学习指南
需积分: 48 124 浏览量
更新于2024-07-18
收藏 5MB PDF 举报
"这是一份关于R语言聚类分析在机器学习中应用的实践指南,由Alboukadel Kassambara编写。该资料详细介绍了如何在R语言环境中进行无监督机器学习的聚类分析。"
正文:
聚类分析是机器学习中的一个关键组成部分,尤其在数据挖掘和模式识别领域中有着广泛的应用。R语言因其强大的统计计算能力和丰富的数据分析包,成为进行聚类分析的理想工具。这份"Practical Guide to Cluster Analysis in R"详细阐述了如何使用R语言进行有效的聚类分析。
1. **聚类分析基本概念**
- 聚类分析是一种无监督学习方法,目标是将数据集中的观测值分成不同的组或簇,使得同一组内的观测值相似性较高,而不同组间的观测值相似性较低。
- 常见的聚类算法包括层次聚类(如单链接、全链接和平均链接)、K-means聚类、DBSCAN(基于密度的聚类)等。
2. **R语言环境下的聚类分析**
- 在R中,可以使用`cluster`包、` klaR`包和`ggplot2`包进行聚类分析和结果可视化。例如,`kmeans()`函数用于实现K-means算法,`hclust()`用于执行层次聚类。
- 还有其他专门用于聚类的包,如`flexclust`、`dbscan`和`clusterSim`,它们提供了更多的聚类方法和评估工具。
3. **选择合适的聚类方法**
- 选择聚类方法时,需要考虑数据的特性和目标。例如,如果数据分布不均匀,可能适合使用DBSCAN;如果知道预先想要的群组数量,K-means可能是好的选择。
4. **预处理步骤**
- 数据标准化:聚类通常要求特征在同一尺度上,因此通常需要对数据进行标准化或归一化处理。
- 缺失值处理:处理缺失值是聚类前的重要步骤,可以使用删除、插值或其他方法。
5. **距离和相似度度量**
- 聚类依赖于距离或相似度度量,如欧氏距离、曼哈顿距离、余弦相似度等。选择合适的度量对聚类结果有很大影响。
6. **聚类有效性评估**
- 为了验证聚类结果的质量,需要使用内部或外部评价指标,如轮廓系数、Davies-Bouldin指数、Calinski-Harabasz指数等。
7. **结果可视化**
- 使用`ggplot2`和其他可视化工具,可以将聚类结果以散点图、树状图或热力图等形式展示,帮助理解数据结构和聚类效果。
8. **实例和实战**
- 书中应包含实际案例,指导读者通过R代码一步步完成聚类分析,从数据加载到模型构建、结果解释,提供了一套完整的实践流程。
这份"Practical Guide to Cluster Analysis in R"涵盖了R语言中进行聚类分析的全过程,对于希望深入理解和应用聚类分析的学者和从业者来说,是一份宝贵的资源。
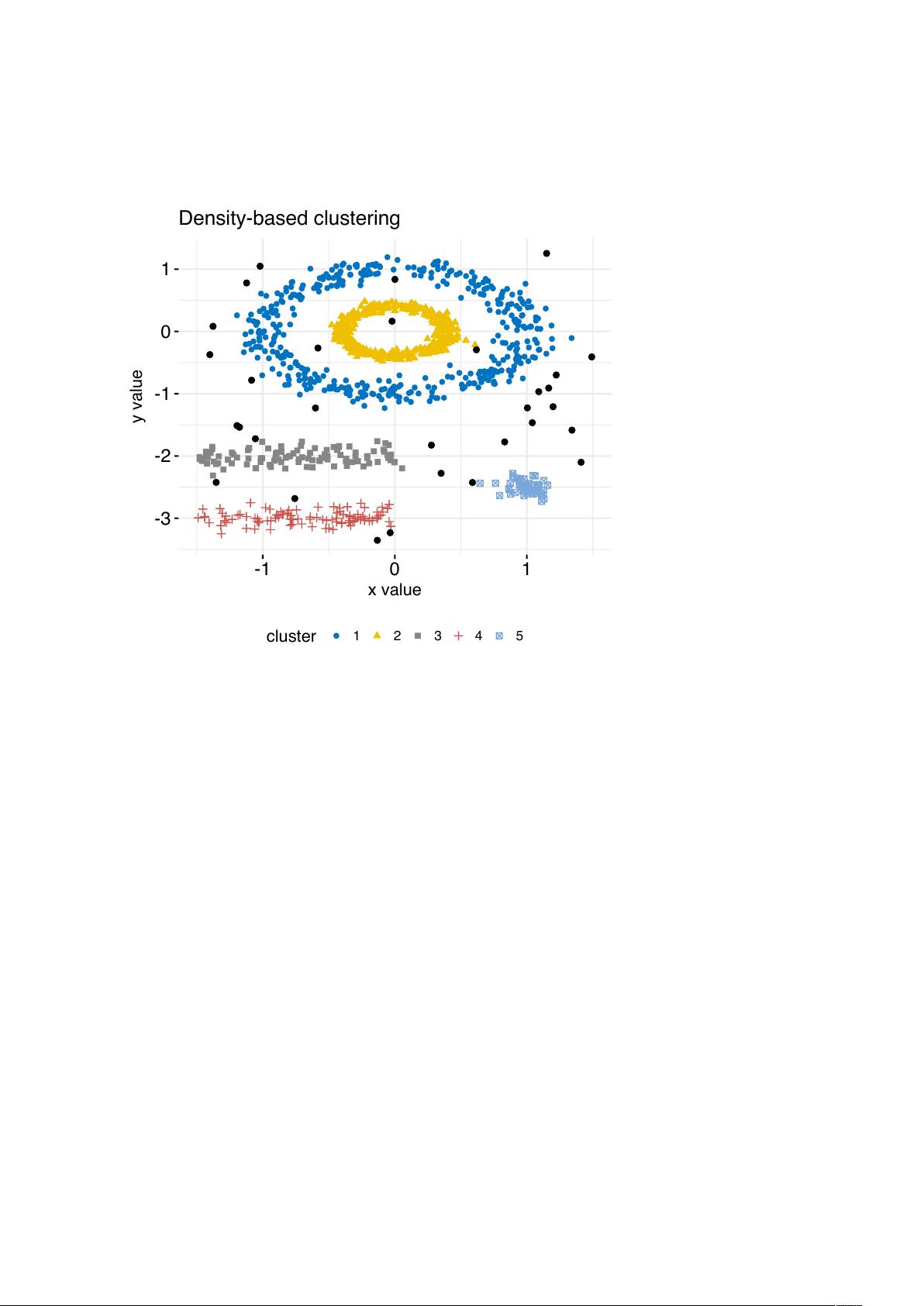
16 CONTENTS
-3
-2
-1
0
1
-1 0 1
x value
y value
cluster
12345
Density-based clustering
0.5 Book website
The website for this book is located at : http://www.sthda.com/english/. It contains
number of ressources.
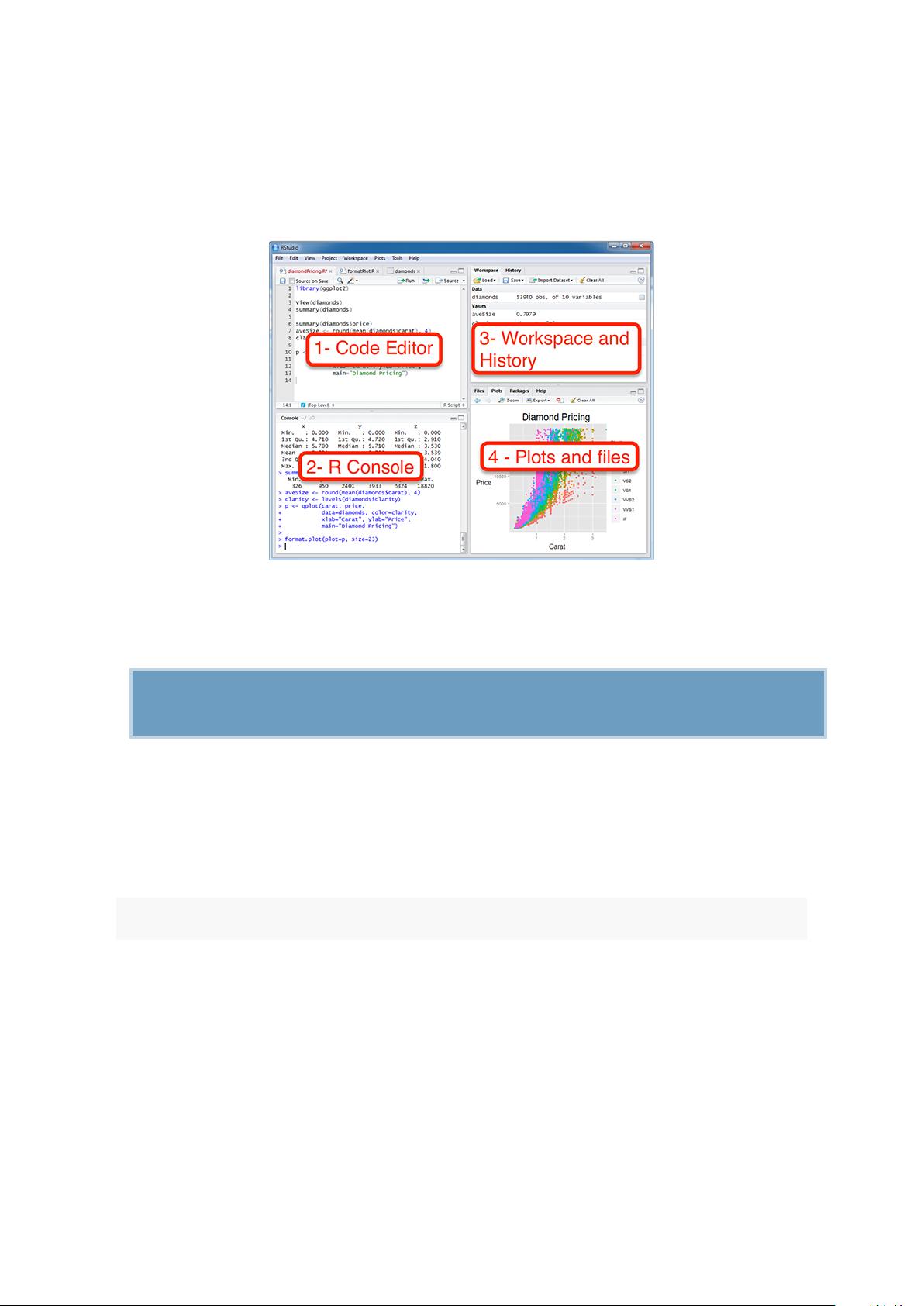
0.6 Executing the R codes from the PDF
For a single line R code, you can just copy the code from the PDF to the R console.
For a multiple-line R codes, an error is generated, sometimes, when you copy and
paste directly the R code from the PDF to the R console. If this happens, a solution
is to:
• Paste firstly the code in your R code editor or in your text editor
• Copy the code from your text/code editor to the R console

剩余186页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-03-09 上传
点击了解资源详情

诺嘿嘿
- 粉丝: 11
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
