Ubuntu环境下大数据环境搭建及配置详解
需积分: 1 10 浏览量
更新于2024-04-12
收藏 6.07MB PDF 举报
大数据环境的搭建是一个复杂而重要的过程,其中涉及到多个关键组件和步骤。在搭建大数据环境时,首先需要下载所需的软件,包括Virtualbox和MobaXterm等工具。通过创建虚拟机和安装openssh-server来准备好运行环境,同时配置网络设置确保各个节点之间可以互相通信。使用MobaXterm创建SSH会话,并复制创建从节点来扩展环境,同时修改主机名和配置密钥以确保安全性。
一旦准备好了基本环境,就可以开始安装Java等关键组件。在搭建大数据环境的过程中,Java是必不可少的一环,因为许多大数据工具和框架都是基于Java开发的。通过在虚拟机中安装Java,为后续安装Hadoop、HBase、Spark等工具打下基础。
接下来,可以搭建Hadoop环境。Hadoop是大数据处理的核心工具之一,具有高可靠性和高扩展性。在搭建Hadoop环境时,需要下载Hadoop安装包,并配置相关环境变量以便系统识别Hadoop的安装路径。同时,需要配置Hadoop的核心文件和进行一些必要的调整,以确保Hadoop能够正常运行。
另外,搭建HBase环境也是大数据环境搭建过程中的一个重要环节。HBase是一个分布式的、面向列的数据库,常用于存储大规模数据。在安装HBase时,需要先下载HBase安装包,并配置HBase的相关参数,例如ZooKeeper的地址等。重要的是要确保HBase和Hadoop之间的集成,以便HBase可以与Hadoop无缝通信。
此外,安装Spark也是搭建大数据环境的关键一步。Spark是一个快速、通用的大数据处理引擎,支持多种类型的工作负载,包括批处理、交互式查询和实时流处理。在安装Spark时,需要下载Spark安装包,并配置Spark的环境变量,以便系统能够正确识别Spark的安装路径。此外,还需要配置Spark的相关参数,以确保Spark可以与Hadoop和其他组件协同工作。
最后,安装Miniconda和Jupyter等工具可以为数据分析和机器学习提供支持。Miniconda是一个Python的包管理器,可以帮助用户更轻松地安装和管理Python库和环境。而Jupyter是一个交互式笔记本工具,支持多种编程语言,包括Python、R和Scala等。通过安装Miniconda和Jupyter,用户可以方便地进行数据分析和机器学习任务。
通过以上步骤,我们可以在Ubuntu中成功搭建大数据环境,包括Java、Hadoop、HBase、Spark、Miniconda和Jupyter等关键组件。这些工具将为我们提供强大的数据处理和分析能力,帮助我们更好地应对大数据时代的挑战。同时,通过环境中的环境变量保存在bigdata.sh中,可以确保整个环境的稳定运行和便捷管理。
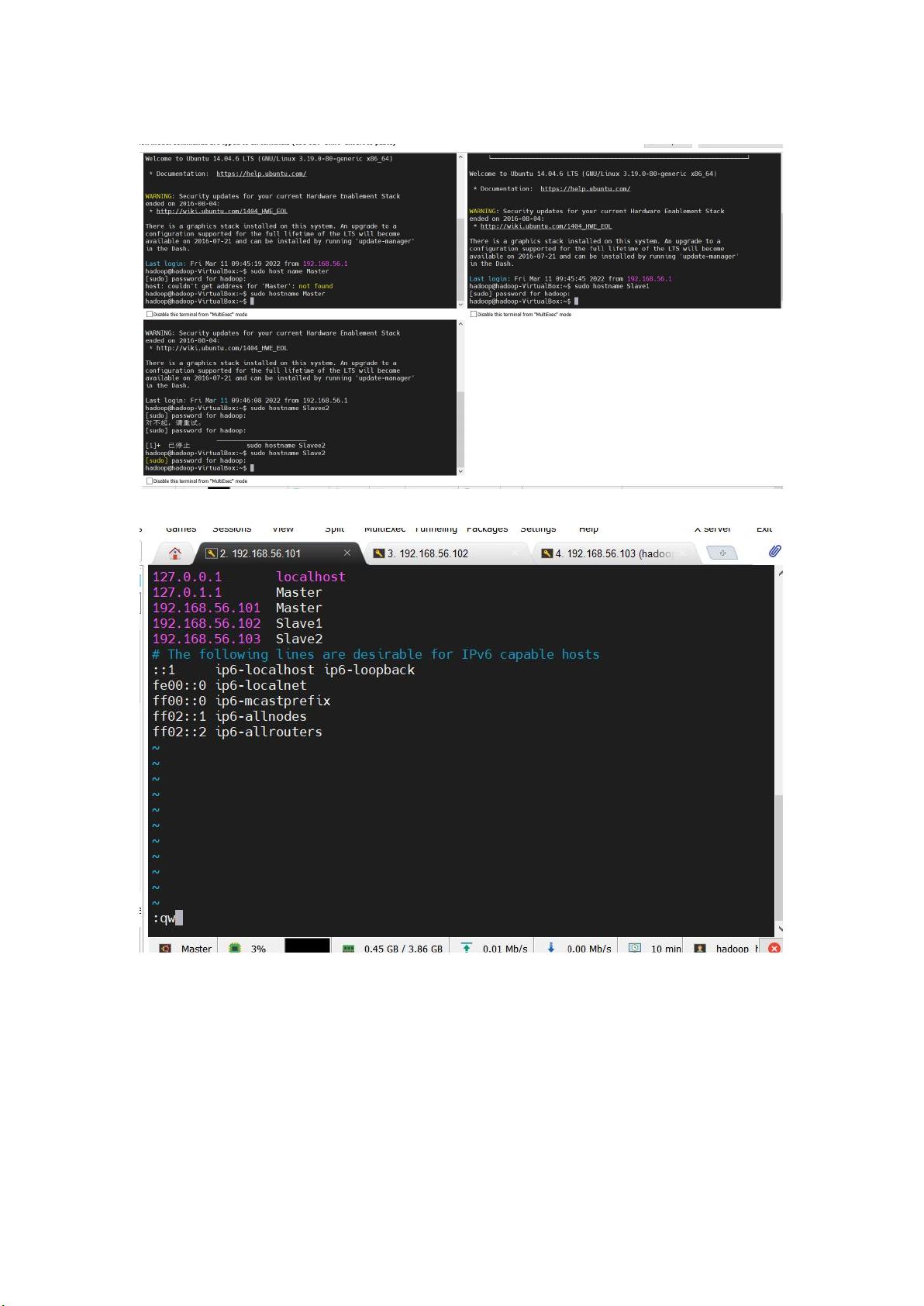
6. 修改主机名
图 9 修改主机名图
图 10 修改 hosts 文件图
修改主机名,并重启,重启后看到所有主机名修改成功。
剩余25页未读,继续阅读
232 浏览量
476 浏览量
124 浏览量
2001 浏览量
2022-07-13 上传
675 浏览量
点击了解资源详情
186 浏览量
1867 浏览量

☆年青新☆
- 粉丝: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- CAS Java客户端注释配置支持库发布
- SnappMarket V2前端工具箱:hooks、ui组件及图标
- Android下拉刷新技术详解及源码分析
- bash-my-aws:Bash工具简化AWS资源管理
- C8051单片机PCB封装库及原理图设计
- Win10下Cena软件安装调试与使用指南
- OK6410开发板实现cgi控制LED灯的详细过程
- 实现JS中的deflate压缩与inflate解压算法
- ESP8266 Arduino库实现WiFi自动重连功能
- Jboss漏洞利用工具的发现与安全分析
- 《算法 第4版》中英文扫描、代码及资料全集
- Linux 5.x内核中Realtek 8821cu网卡驱动安装指南
- 网页小游戏存档工具:saveflash.exe
- 实现在线投票系统的JSP部署与数据库整合
- jQuery打造3D动画Flash效果的图片滚动展示
- 掌握PostCSS新插件:使用4/8位十六进制颜色值
