大数据集群实战:Hadoop-HBase-Spark-Hive搭建步骤
需积分: 0 161 浏览量
更新于2024-07-01
6
收藏 547KB PDF 举报
"该资源是一个关于大数据处理技术的教程,主要涵盖了Hadoop、HBase、Spark和Hive的集群搭建过程。由七月在线提供,旨在帮助用户了解和实践大数据环境的构建。"
在这个教程中,你将学习如何一步步构建一个高效运行大数据应用的集群。以下是各个部分的详细说明:
1. **系统准备**: 首先,你需要准备一个基于Ubuntu的Linux环境,因为Hadoop等大数据框架通常在Linux上运行更稳定。这一步可能涉及到安装和配置不同节点的操作系统。
2. **Java安装**: 所有这些大数据组件都依赖于Java运行环境(JRE)和Java开发工具包(JDK)。因此,你需要确保所有服务器都安装了最新版本的Java。
3. **Hadoop安装**: Hadoop是Apache软件基金会的一个开源项目,提供了分布式文件系统(HDFS)和MapReduce计算模型。你将学习如何下载Hadoop的相应版本,配置环境变量,以及设置Hadoop集群的主节点和工作节点。
4. **Hadoop集群配置**: 这一部分将涉及设置`hosts`文件以确保节点间的通信,配置SSH无密码登录以简化管理,以及启动和检查Hadoop服务的运行状态。
5. **HBase安装与配置**: HBase是一个基于Hadoop的数据存储系统,适合大规模、非结构化数据的实时访问。你将学习如何安装HBase,以及配置HBase以适应你的Hadoop集群。
6. **Spark安装与配置**: Spark是用于大规模数据处理的快速、通用和可扩展的计算框架。它支持批处理、交互式查询、流处理和机器学习。教程会指导你安装Spark,设置Master和Worker节点,并进行必要的配置。
7. **Hive安装与配置**: Hive提供了一个SQL-like接口来查询和管理大数据,它建立在Hadoop之上。你将学习如何安装Hive,连接到MySQL作为元数据存储,以及配置Hive服务器。
8. **集群测试与优化**: 最后,你会进行集群的功能测试,确保所有组件都能正常协同工作。可能还会涉及到性能调优,以确保集群在处理大数据时达到最佳状态。
这个教程适合对大数据有兴趣,想要深入理解和实践Hadoop生态系统的人群。通过这个教程,你将能够构建一个功能齐全的大数据处理环境,为实际业务分析和数据挖掘打下坚实的基础。
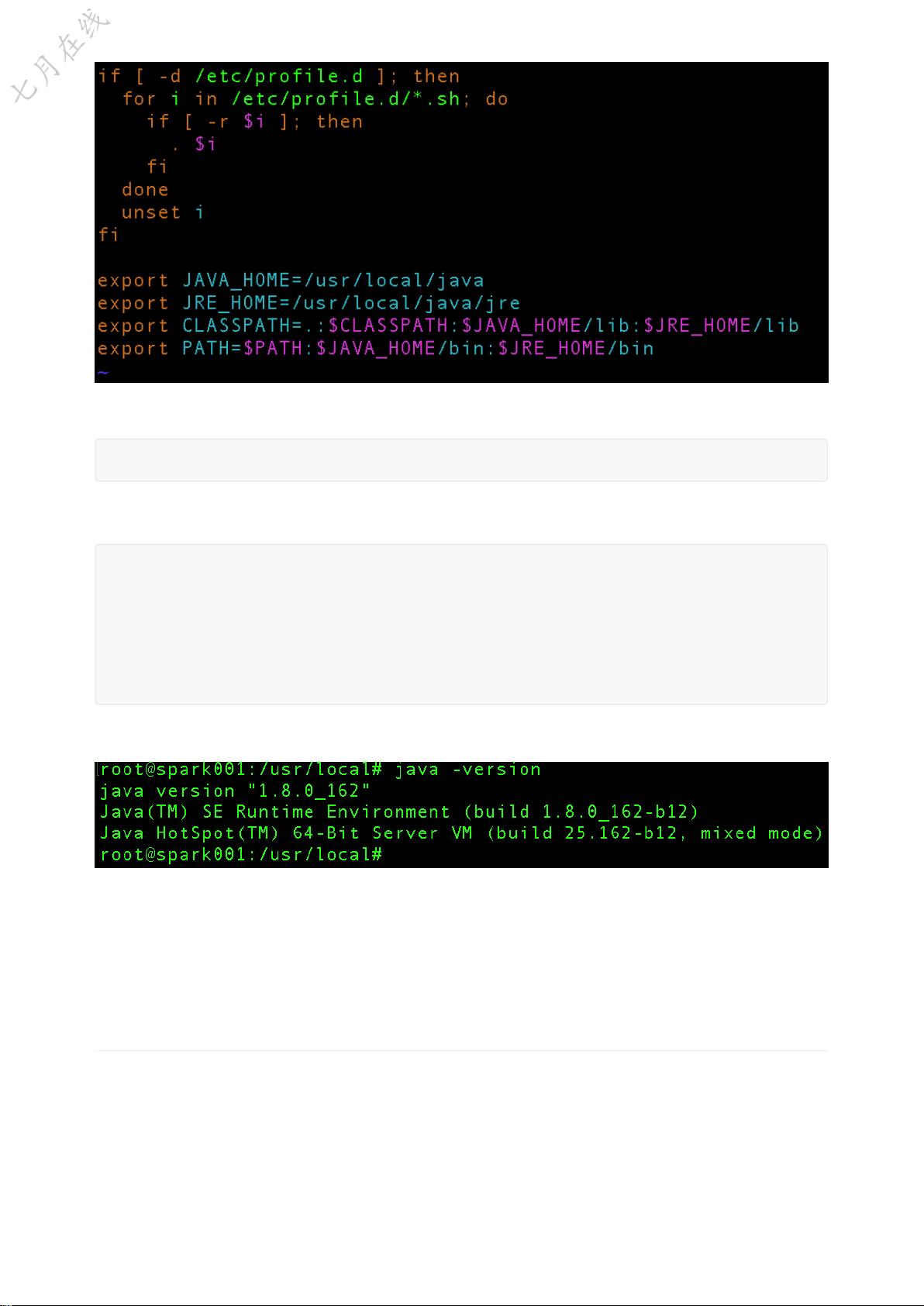
7.
root@spark001:/usr/local# source /etc/profile
8. JAVA
#java -version java java javac
root@spark001:/usr/local# echo $JAVA_HOME #
root@spark001:/usr/local# java -version
root@spark001:/usr/local# java
root@spark001:/usr/local# javac
java -version java java javac
9. JAVA
5Hadoop
JDK
JDkmaster
spark001
1.
七月在线
剩余21页未读,继续阅读
2018-03-05 上传
2021-05-23 上传
2021-03-02 上传
128 浏览量
点击了解资源详情
2019-07-31 上传
2024-04-02 上传
2024-03-04 上传
点击了解资源详情









