Lucene全文检索原理与代码深度剖析
需积分: 34 44 浏览量
更新于2024-07-19
收藏 5.16MB PDF 举报
"Lucene原理与代码分析完整版"是一份深入讲解Lucene搜索引擎核心原理及其实现的教程。Lucene是一款开源的全文搜索引擎库,被广泛应用于各种应用程序中,尤其在Java环境中,它的高效性和灵活性备受开发者青睐。本文档主要分为两大部分:原理篇和代码分析篇。
在原理篇中,首先介绍了全文检索的基本原理,包括总论部分,阐述了索引在搜索引擎中的核心作用。索引存储着文档中的词元(Token),通过Tokenizer进行分词,LinguisticProcessor进行语言处理,然后由Indexer构建倒排索引,将文档中的词与它们在文档中的位置信息关联起来。用户搜索时,会先对查询语句进行词法分析、语法分析和语言处理,形成语法树,接着在索引中查找匹配的文档,并通过计算 Termweight 和 VSM(向量空间模型)评估文档的相关性,最终按相关性排序返回结果。
Lucene的总体架构部分详细剖析了搜索引擎的各个组件之间的协作,如查询处理器、索引器、搜索器等,以及它们在整个搜索过程中的职责和交互方式。
代码分析篇则具体涉及Lucene的索引文件格式,包括基本概念、基本类型和规则。索引文件由多种数据结构组成,如文档存储、段(Segment)、字段(Field)等,其中规则如前缀后缀匹配(Prefix+Suffix)、差分编码(Delta)等技术用于优化存储和查询效率。此外,还可能涉及倒排列表(PostingList)、位图(Bitmaps)等高级数据结构的解析。
学习者可以通过这篇教程深入了解Lucene的工作机制,从而在实际开发中更好地利用它构建高效的搜索引擎。作者觉先(forfuture1978)在多个博客平台分享了这些内容,提供了丰富的学习资源和联系方式,对于希望深入研究或实践Lucene的开发者来说,这是一份非常宝贵的参考资料。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
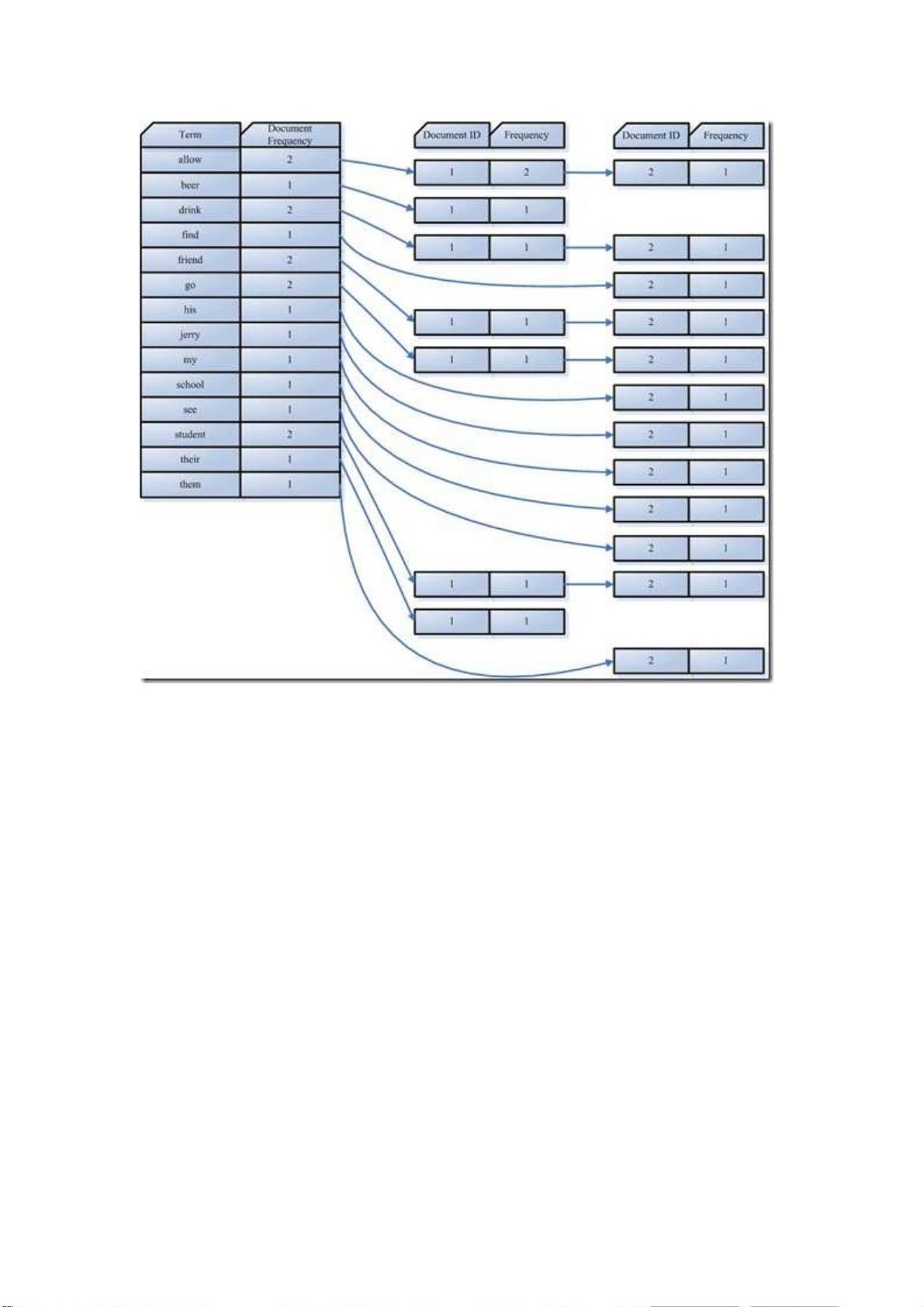
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
2023-07-12 上传
2023-06-01 上传
2023-12-21 上传
2023-09-05 上传
2023-07-12 上传
2023-12-31 上传

guoyuanhua300
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多模态联合稀疏表示在视频目标跟踪中的应用
- Kubernetes资源管控与Gardener开源软件实践解析
- MPI集群监控与负载平衡策略
- 自动化PHP安全漏洞检测:静态代码分析与数据流方法
- 青苔数据CEO程永:技术生态与阿里云开放创新
- 制造业转型: HyperX引领企业上云策略
- 赵维五分享:航空工业电子采购上云实战与运维策略
- 单片机控制的LED点阵显示屏设计及其实现
- 驻云科技李俊涛:AI驱动的云上服务新趋势与挑战
- 6LoWPAN物联网边界路由器:设计与实现
- 猩便利工程师仲小玉:Terraform云资源管理最佳实践与团队协作
- 类差分度改进的互信息特征选择提升文本分类性能
- VERITAS与阿里云合作的混合云转型与数据保护方案
- 云制造中的生产线仿真模型设计与虚拟化研究
- 汪洋在PostgresChina2018分享:高可用 PostgreSQL 工具与架构设计
- 2018 PostgresChina大会:阿里云时空引擎Ganos在PostgreSQL中的创新应用与多模型存储
