理解正则表达式:入门指南
"Introducing Regular Expressions - Michael Fitzgerald"
在IT领域,正则表达式(Regular Expressions)是一种强大的文本处理工具,广泛应用于数据验证、搜索、替换和提取等多种任务。本书"Introducing Regular Expressions"由Michael Fitzgerald撰写,旨在帮助读者以简单易懂的方式入门正则表达式。
正则表达式是一种特殊的字符序列,能够描述一系列的字符串模式。通过使用元字符和量词,我们可以构建复杂的匹配规则,以高效地处理大量文本数据。例如,简单的正则表达式".at"可以用来匹配任何包含".at"子串的字符串,无论它出现在字符串的哪个位置。
书中的内容可能涵盖了以下几个关键概念:
1. **基础符号**:包括"."(匹配任意字符,除了换行符)、"*"(匹配前面的元素零次或多次)、"+"(匹配前面的元素一次或多次)和"?"(匹配前面的元素零次或一次)。
2. **字符类**:如"[abc]"用于匹配括号内的任意一个字符,"[^abc]"则匹配非括号内的任何字符。
3. **重复**:"{n}"表示匹配前面的元素n次,"{n,}"表示至少n次,"{n,m}"表示n到m次。
4. **分组**:使用"( )"来创建一个分组,可以对一组字符应用重复或其他操作。
5. **选择**:使用"|"(竖线)表示或操作,如"a|b"将匹配'a'或'b'。
6. **锚点**:"^"表示字符串的开始,"$"表示字符串的结束,确保匹配整个字符串的特定部分。
7. **量词修饰符**:"?"、"*"、"+"也可以用作非贪婪模式,如"?*"、"*?"、"+?",它们会尽可能少地匹配字符。
8. **反向引用**:在分组中,"\n"可以引用第n个分组匹配的文本。
9. **预定义字符类**:如`\d`代表数字,`\D`代表非数字,`\s`代表空白字符,`\S`代表非空白字符等。
此外,书中可能还会涉及正则表达式在各种编程语言中的实现差异,如JavaScript、Python、Perl等,并提供实际案例来加深理解。读者可能还会学习如何在命令行工具(如grep、sed和awk)中使用正则表达式,以及如何在开发环境中调试和测试正则表达式。
"Introducing Regular Expressions"是一本适合初学者的指南,它通过清晰的解释和实例,帮助读者掌握这一强大工具,从而提升他们在处理文本数据时的效率和准确性。

Chapter 10 shows you a slightly more sophisticated regular expression
for a phone number, but the one above is sufficient for the purposes of
this chapter.
If you don’t get how that all works yet, don’t worry: I’ll explain the whole expression
a little at a time in this chapter. If you will just follow the examples (and those through-
out the book, for that matter), writing regular expressions will soon become second
nature to you. Ready to find out for yourself?
I at times represent Unicode characters in this book using their code point—a four-
digit, hexadecimal (base 16) number. These code points are shown in the form
U+0000. U+002E, for example, represents the code point for a full stop or period (.).
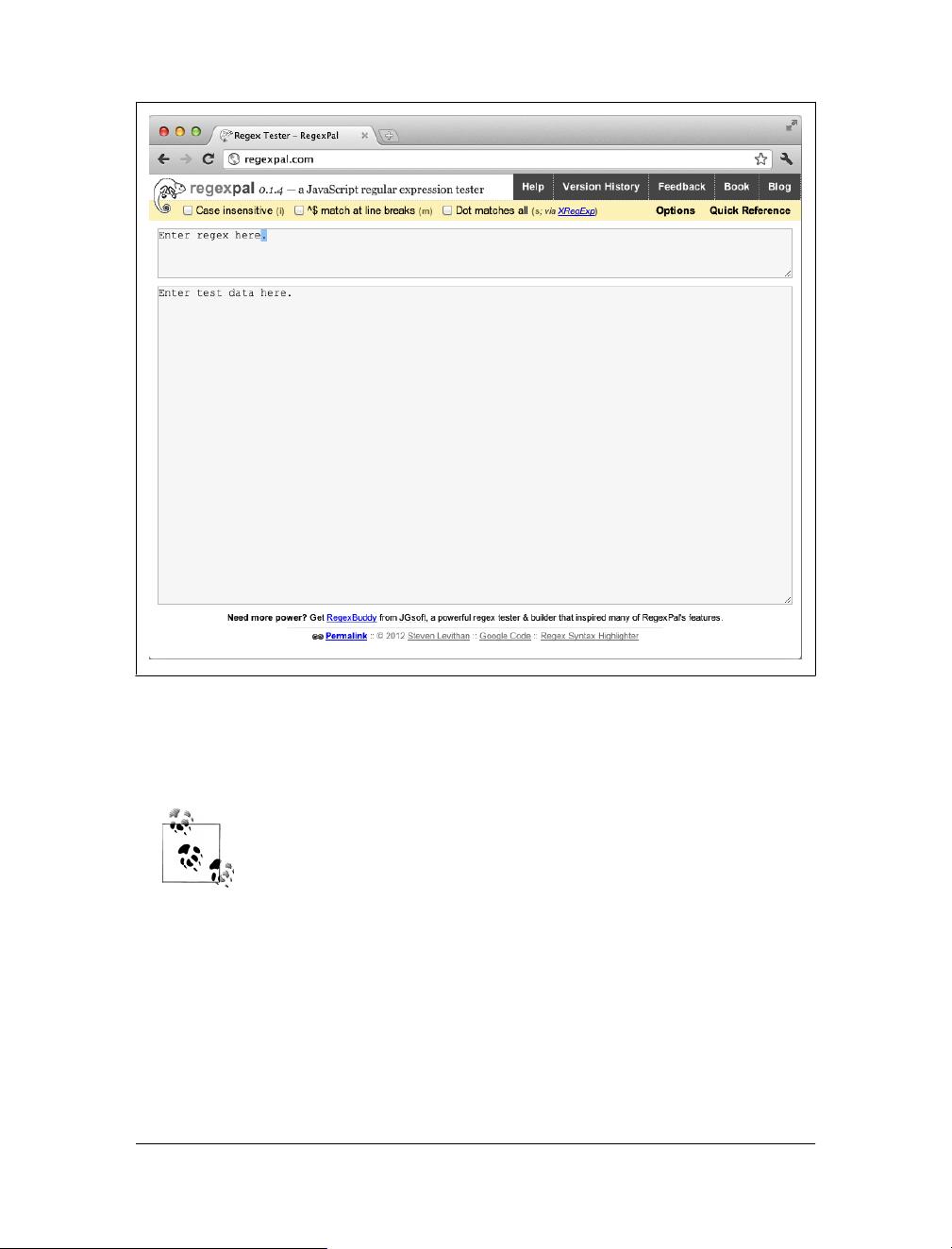
Getting Started with Regexpal
First let me introduce you to the Regexpal website at http://www.regexpal.com. Open
the site up in a browser, such as Google Chrome or Mozilla Firefox. You can see what
the site looks like in Figure 1-1.
You can see that there is a text area near the top, and a larger text area below that. The
top text box is for entering regular expressions, and the bottom one holds the subject
or target text. The target text is the text or set of strings that you want to match.
At the end of this chapter and each following chapter, you’ll find a
“Technical Notes” section. These notes provide additional information
about the technology discussed in the chapter and tell you where to get
more information about that technology. Placing these notes at the end
of the chapters helps keep the flow of the main text moving forward
rather than stopping to discuss each detail along the way.
Matching a North American Phone Number
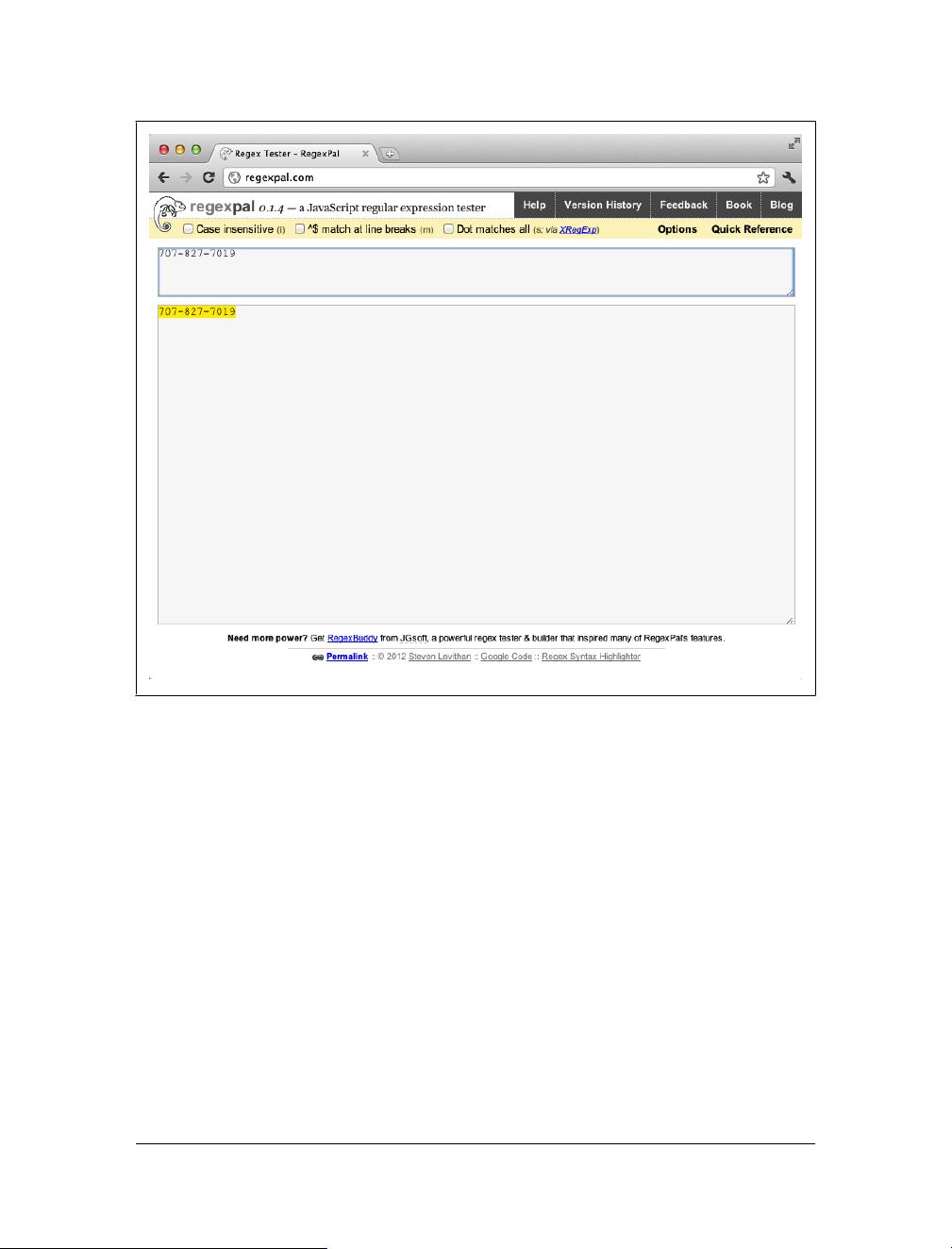
Now we’ll match a North American phone number with a regular expression. Type the
phone number shown here into the lower section of Regexpal:
707-827-7019
Do you recognize it? It’s the number for O’Reilly Media.
Let’s match that number with a regular expression. There are lots of ways to do this,
but to start out, simply enter the number itself in the upper section, exactly as it is
written in the lower section (hold on now, don’t sigh):
707-827-7019
2 | Chapter 1: What Is a Regular Expression?


剩余151页未读,继续阅读
相关推荐



maybepossible
- 粉丝: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- H Toolkit Library:全面的开源C++应用开发框架
- Android AlarmManager和PendingIntent的实战应用
- 微信支付宝支付监听器:免签个人收款解决方案
- 基于OpenCV的光流法运动目标自动识别代码
- 使用QCustomPlot进行高效绘图的实践指南
- 实现UICollectionView纯代码布局与头部尾部视图添加
- Ruby应用程序部署与运行全解
- 创新教学辅助工具:挂图展示装置设计文档
- Cocos2d-x实现坦克大战游戏教程
- MSP430F249单片机在Proteus中的仿真教程
- Go语言Web框架深度对比分析
- 易语言实现非阻塞URL下载源码分享
- 博士论文回购:多矩阵集体场论有效潜能最小化
- 芝麻Python项目深度解析与实战应用
- 小米Note动态四核性能提升与第三方rec刷机教程
- C#中UDT数据通信实现教程及API使用说明
