海量数据分组排序新算法:无指针快速排序
需积分: 10 128 浏览量
更新于2024-08-12
收藏 215KB PDF 举报
"一种适宜于海量数据的快速分组排序算法(2010年)",作者胡继宽和汪维清,发表于《西南大学学报(自然科学版)》2010年第6期,文章探讨了一种适用于大规模数据的高效无指针分组排序算法,分析了算法的时间复杂度和空间复杂度。
正文:
分组排序是数据处理中的一个重要课题,尤其是在处理大量数据时,高效的排序算法能够显著提高系统性能。传统的排序算法如冒泡排序、快速排序、选择排序、堆排序、希尔排序和归并排序各有优缺点,适应不同的数据特性和环境。本文介绍的无指针分组排序算法是一种针对海量数据优化的排序方法,旨在解决大规模数据集的排序问题。
无指针分组排序的基本思想是通过分治策略来实现。首先,将待排序的数据序列分为若干组,每组内的数据具有一定的相似性,例如,根据数据的范围将其均匀分配到各个组中。假设输入序列a[p1...pn],最大值为max,最小值为min,那么可以将数据分为j组,其中j=int((a[pi]-min)*m/(max-min)),且n>m。这种分组方式可以确保每个组内的数据在一定程度上是有序的,从而降低了整体排序的难度。
该算法的时间复杂度分析如下:在最坏情况下,时间复杂度为θ(mn),这是因为可能需要对每个元素进行m次操作;在最好情况和平均情况下,时间复杂度降为θ(nlog(n/mk)),这是因为算法的效率提高了,数据分布更均匀,减少了操作次数。空间复杂度方面,最坏情况下为O(mn-m^2+m),这是由于在极端情况下需要额外存储的空间;而最好情况和平均情况下,空间复杂度为O(n),表明算法在大多数情况下能保持较低的内存需求。
无指针分组排序的优势在于它减少了传统排序算法在处理大数据量时可能出现的性能瓶颈。例如,冒泡排序在逆序数据中效率低下,快速排序在某些情况下可以降低逆序操作,但仍有改进空间,而归并排序虽然时间复杂度稳定,但需要额外的内存空间。相比之下,无指针分组排序通过合理的数据分组,能够在保证排序效率的同时,尽可能地减少额外的内存开销,尤其适合处理无法一次性加载到内存的海量数据。
通过实验验证,该算法在实际应用中表现出较高的性能,对于大规模数据排序场景具有较好的适用性。作者胡继宽和汪维清的研究为大数据处理提供了新的排序思路,对于提升大规模数据处理效率具有积极的意义。
无指针分组排序算法是一种针对海量数据的创新排序方法,其独特的分组策略和良好的时间、空间复杂度使得它在处理大数据集时表现出优越的性能。在数据科学、计算机科学以及需要大量数据处理的领域,该算法的理论和实践价值不容忽视。
第 32 卷第 6 期 西 南 大 学 学 报 (自然科学版) 2010 年 6 月
Vol畅32 No畅6 Journal of Southw est University (Natural Science Edition) Jun畅 2010
文章编号 :1673 9868(2010)06 0173 04
一 种 适 宜 于 海 量 数 据 的 快 速 分 组 排 序 算 法
①
胡继宽 , 汪维清
西南大学 荣昌校区信息管理系 ,重庆 402460
摘要 : 提出了一种高效的适宜于海量数据的无指针分组排序算法 ,分析了该算法的原理及其时间复杂度和空间复
杂度 .
在最坏情况下的时间复杂度是
θ
(mn) ,最好情况和平均情况下的时间复杂度均是
θ
(n log (n/m
k
)) ;在最坏情
况下的空间复杂度是 O(mn
-
m
2
+
m) ,最好情况和平均情况下的空间复杂度均是 O(n)) .
关 键 词 :分组排序 ;无指针分组排序 ;快速排序 ;复杂度
中图分类号 : TP301畅6 文献标识码 : A
排序在数据处理 、程序设计 、统计计算中经常使用
[1 3]
.常用排序算法有冒泡排序 、 快速排序 、直接选
择排序 、堆排序 、希尔排序 、归并排序等
[4 8]
.冒泡排序算法不适宜于逆序 ;快速排序算法能减少逆序时所
消耗的扫描和数据交换次数 ;堆排序对数据的有序性不敏感 ,适宜于较大的序列排序 ;直接插入法算法对
数据的有序性非常敏感 ,在最优情况只需要经过 n
-
1 次比较 ,而最坏情况需要 n(n
-
1)/2 次比较 ;希尔排
序也是一种基于插入排序的算法 ,但能够改善整个排序性能 ;归并排序需要与待排序序列一样多的辅助空
间 ,其时间复杂度固定为 O(n log n) .
本文提出一种适宜于海量数据排序的无指针分组排序算法 ,通过实验证明该算法具有较高的性能 .
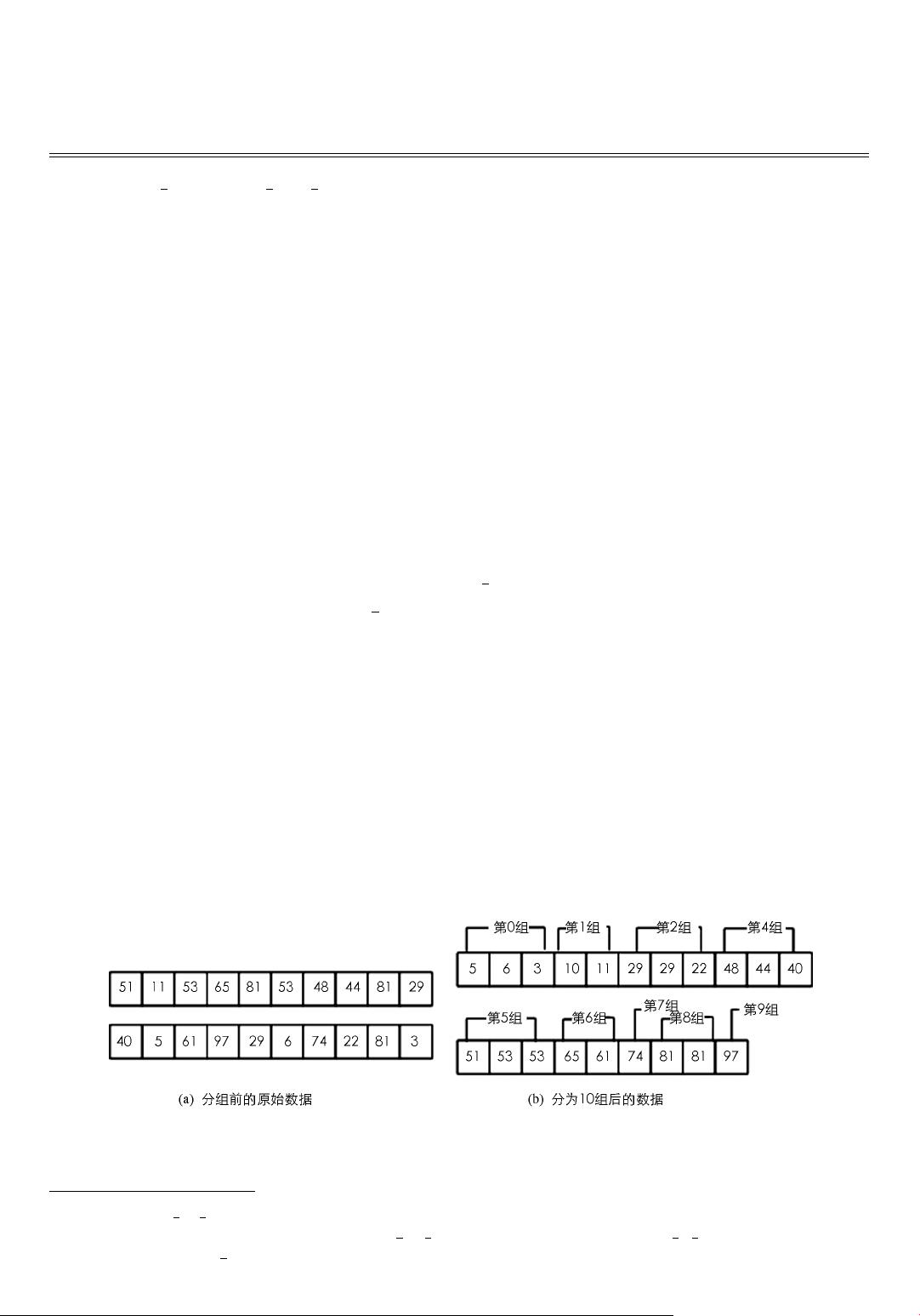
1 无指针分组排序基本思想
无指针分组排序算法的关键就是分组 .设输入序列 a[
p
1
…
p
n
] ,以数组的形式表示 ,max 为数组元素的
上限 ,min 为下限 ,a[
p
i
](i
=
1 ,2 ,… ,n) ,可分为
j
组 ,其中
j
=
int (a[
p
i
] 倡 m/(max
-
min)) ,n
>
m .如
图 1 所示 .
图 1 数据的分组
分组思想基于分治策略 ,先将序列 a[
p
1
…
p
n
] 分成 a1[
p
1
…
p
k1
] 、 a2[
p
k1
+
1 …
p
k2
] … 和 am[
p
km
-
1
+
①
收稿日期 : 2009 06 18
基金项目 : 重庆市教育科学“十一五”规划资助项目 (08 GJ 044) ;重庆市高等教育研究资助项目(09 3 181) .
作者简介 : 胡继宽 (1971 ) ,男 ,四川阆中人 ,硕士 ,讲师 ,主要从事计算机网络和信息管理研究 .
下载后可阅读完整内容,剩余3页未读,立即下载
2021-11-24 上传
2022-06-18 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38689055
- 粉丝: 8
- 资源: 908
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
