搭建Hadoop集群与Zookeeper,含SSH配置详解
需积分: 9 48 浏览量
更新于2024-07-18
收藏 2.19MB DOCX 举报
本文档主要介绍了如何搭建一个Hadoop集群,并涉及Zookeeper的集成,同时包括SSH的配置。整个过程分为两个主要部分:创建必要的目录结构和安装及配置相关的软件。
首先,我们从创建目录开始。在操作系统的`/opt`目录下,创建了四个关键目录:
1. `datas`: 用于存放测试数据,这对于Hadoop集群的运行至关重要,因为Hadoop处理大量数据。
2. `modules`: 安装所有软件的目录,确保软件整洁且易于管理。
3. `softwares`: 存放安装包,这通常是软件的原始版本,便于后续升级或替换。
4. `tools`: 放置如Eclipse这样的开发工具,方便开发人员进行Hadoop项目的开发工作。
接下来是软件的安装:
- **安装JDK**: 首先检查已安装的JDK版本,通过`rpm -qa | grep java`来实现。如果有多个版本,需要强制删除并选择一个特定版本(如`jdk-8u66`),使用`Rpm -e --nodeps jdk1.6 jdk1.7 ...`命令。然后将选定的JDK解压到`/opt/modules`,并通过`rpm -i --badreloc --relocate /usr/java=/opt/modules/jdk-8u66-linux-x64.rpm`命令指定安装路径。最后,设置环境变量`JAVA_HOME`和`PATH`,使得系统能够识别和调用新安装的JDK。
- **安装Hadoop**: 使用`tar`命令解压Hadoop-2.5.0-cdh5.3.6版本的安装包到`/opt/modules`。这里提到的分布式规划意味着需要对Hadoop的配置文件进行调整,特别是以下关键配置:
- HDFS相关文件:
- `hadoop-env.sh`: 配置Hadoop使用JDK。
- `core-site.xml`: 用于NameNode的配置,可能需要添加临时数据存储路径。
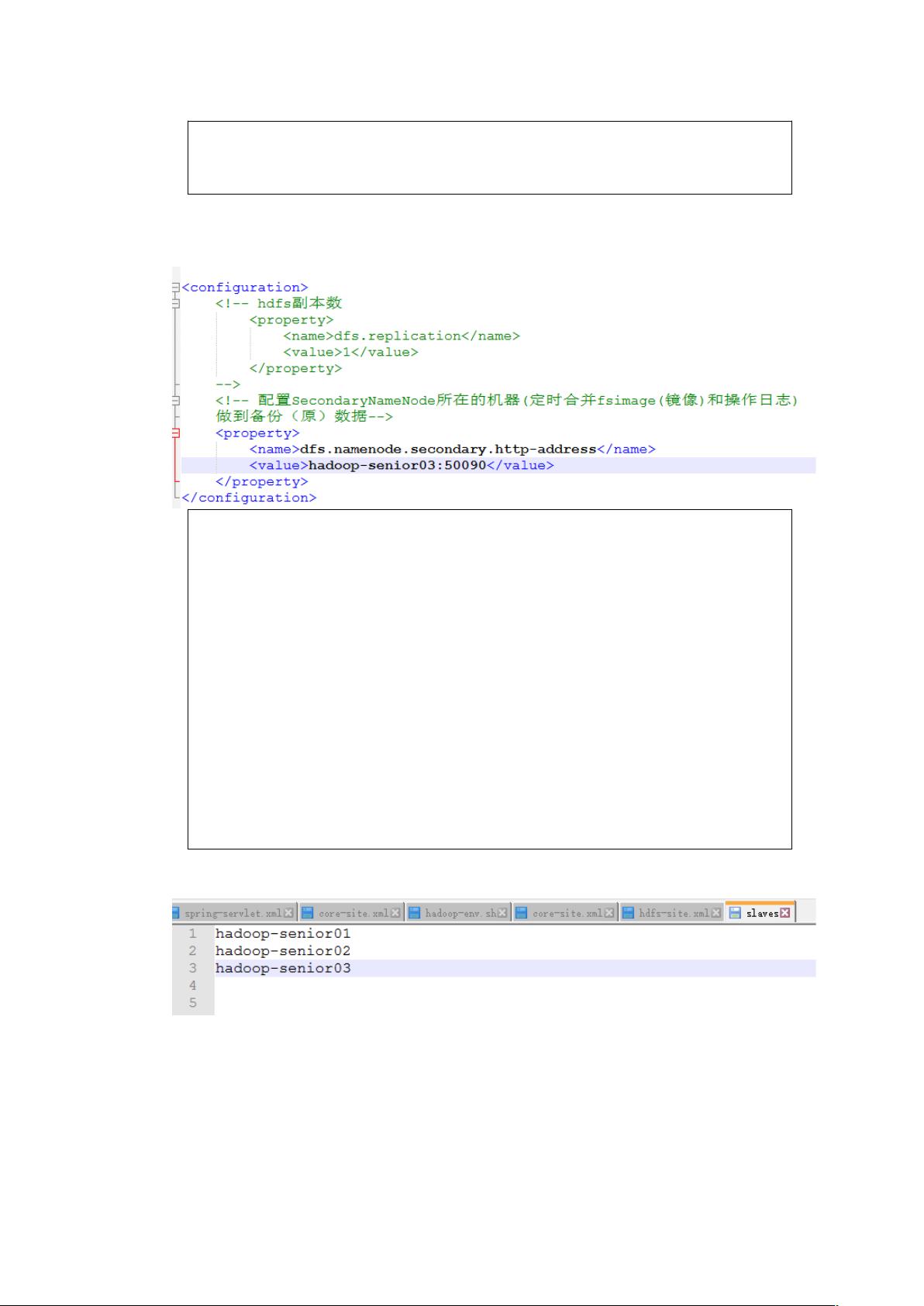
- `hdfs-site.xml`: 用于SecondaryNameNode配置。
- `slaves`: 数据节点清单。
- YARN相关文件:
- `yarn-env.sh`: 配置YARN使用JDK。
- `yarn-site.xml`: ResourceManager配置。
- `slaves`: NodeManager节点列表。
- MapReduce相关文件:
- `mapred-env.sh`: 同样配置JDK。
- `mapred-site.xml`: 用于JobHistoryServer的地址配置。
在HDFS配置方面,特别提到了`/opt/modules/hadoop-2.5.0-cdh5.3.6/etc/hadoop`目录下的三个配置文件:
1. `hadoop-env.sh`: 进一步配置JDK路径,确保Hadoop使用正确的Java环境。
2. `core-site.xml`: 关键性配置,包括NameNode数据的存储路径。
3. `hdfs-site.xml`: 包含SecondaryNameNode的配置,影响集群的副本策略和数据备份。
在整个过程中,SSH配置没有直接提及,但通常在Hadoop集群中,SSH被用于安全地远程访问和管理各个节点,尤其是进行集群管理和故障排查。因此,尽管文档未明确列出SSH的配置步骤,但理解它在Hadoop运维中的重要性是必要的。在安装Hadoop后,确保SSH服务正常启动,并且用户拥有正确权限,以便通过SSH连接到集群节点。
总结来说,本文详细描述了如何在Linux系统上搭建一个Hadoop 2.5.0 CDH5.3.6集群,涉及目录管理、JDK和Hadoop的安装,以及部分关键配置文件的调整。同时,虽然没有直接提到SSH,但在实际操作中,SSH的配置和使用是必不可少的。
EG77,7E)G
E)CG
E).FG
=-&%
E.FG
EH-& 副本数
ECG
EG&FE)G
EGE)G
E)CG
G
EH配置 BCAA 所在的机器定时合并 &镜像和操作日志
做到备份(元)数据G
ECG
EG&C-IE)G
EG-7=<77J7E)G
E)CG
E).FG
'(5)
<C%
剩余17页未读,继续阅读
154 浏览量
125 浏览量
114 浏览量
196 浏览量
125 浏览量
174 浏览量
106 浏览量
点击了解资源详情
229 浏览量

睡着了的鱼儿
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 微波网络分析仪详解:概念、参数与测量
- 从Windows到Linux:一个UNIX爱好者的心路历程
- 经典Bash shell教程:深入学习与实践
- .NET平台入门教程:C#编程精髓
- 深入解析Linux 0.11内核源代码详解
- MyEclipse + Struts + Hibernate:初学者快速配置指南
- 探索WPF/E:跨平台富互联网应用开发入门
- Java基础:递归、过滤器与I/O流详解
- LoadRunner入门教程:自动化压力测试实践
- Java程序员挑战指南:BITSCorporation课程
- 粒子群优化在自适应均衡算法中的应用
- 改进LMS算法在OFDM系统中的信道均衡应用
- Ajax技术解析:开启Web设计新篇章
- Oracle10gR2在AIX5L上的安装教程
- SD卡工作原理与驱动详解
- 基于IIS总线的嵌入式音频系统详解与Linux驱动开发
