手把手教你搭建Hadoop HA与Zookeeper集群
需积分: 9 94 浏览量
更新于2024-07-17
收藏 770KB DOCX 举报
"本文介绍了如何使用Hadoop和Zookeeper搭建高可用(HA)环境,包括Hadoop HA的基本原理、解决方案和具体的服务器准备与集群规划。"
Hadoop+Zookeeper搭建HA是为了克服Hadoop 2.0之前NameNode的单点故障问题。在没有HA的情况下,如果NameNode出现故障,整个Hadoop集群将无法正常工作。Hadoop 2.0引入了HA机制,通过Active/Standby两个NameNode的角色切换来保证服务的连续性。在一个时刻,只有一个NameNode处于Active状态,负责处理所有的客户端请求,而另一个NameNode则处于Standby状态,不断同步Active NameNode的元数据,以便在Active NameNode故障时迅速接管。
实现Hadoop HA的关键是共享存储系统,用于同步两个NameNode的元数据。这可以是NFS、Quorum Journal Manager (QJM)或Zookeeper。在这个过程中,Active NameNode会将编辑日志(editlog)写入共享存储,而Standby NameNode会持续监控并读取这些日志,保持其状态与Active NameNode同步。此外,DataNode需要配置为同时向两个NameNode发送心跳和文件块信息,以帮助Standby NameNode实时了解集群状态。
在搭建Hadoop HA环境时,通常需要多台服务器进行分布式部署。在本例中,使用了4台CentOS 7.3服务器,配置了Hadoop 2.7.5、Zookeeper 3.4.10和JDK 1.8。在服务器准备阶段,需要进行以下操作:
1. 设置系统启动模式为命令行界面,以避免图形界面带来的资源消耗。
2. 关闭防火墙,因为防火墙可能阻止Hadoop集群间的通信。
进一步的集群配置包括网络设置、主机名解析、SSH无密码登录、Hadoop和Zookeeper的安装与配置,以及相关的安全配置,如Hadoop的HDFS和YARN的配置文件修改,添加NameNode的HA设置,以及Zookeeper的配置,确保它能支持Hadoop的HA切换。
在所有配置完成后,需要进行格式化命名空间、启动所有服务并进行测试,包括模拟NameNode故障进行手动或自动切换,确保在实际环境中能正确地进行HA操作。
Hadoop+Zookeeper搭建HA是一个涉及多个步骤和技术的复杂过程,需要深入理解Hadoop的架构和Zookeeper的工作原理。通过正确配置和测试,可以实现NameNode的高可用性,显著提高Hadoop集群的稳定性。
[root@hadoop1 ~]# systemctl list-unit-files |grep chronyd
-&%-%$$$$$$$$$$$$$$$$$$$$$$$$$$$$$&!%&
注意:如果没有,请在每个主机上都安装后再进行下面的操作;
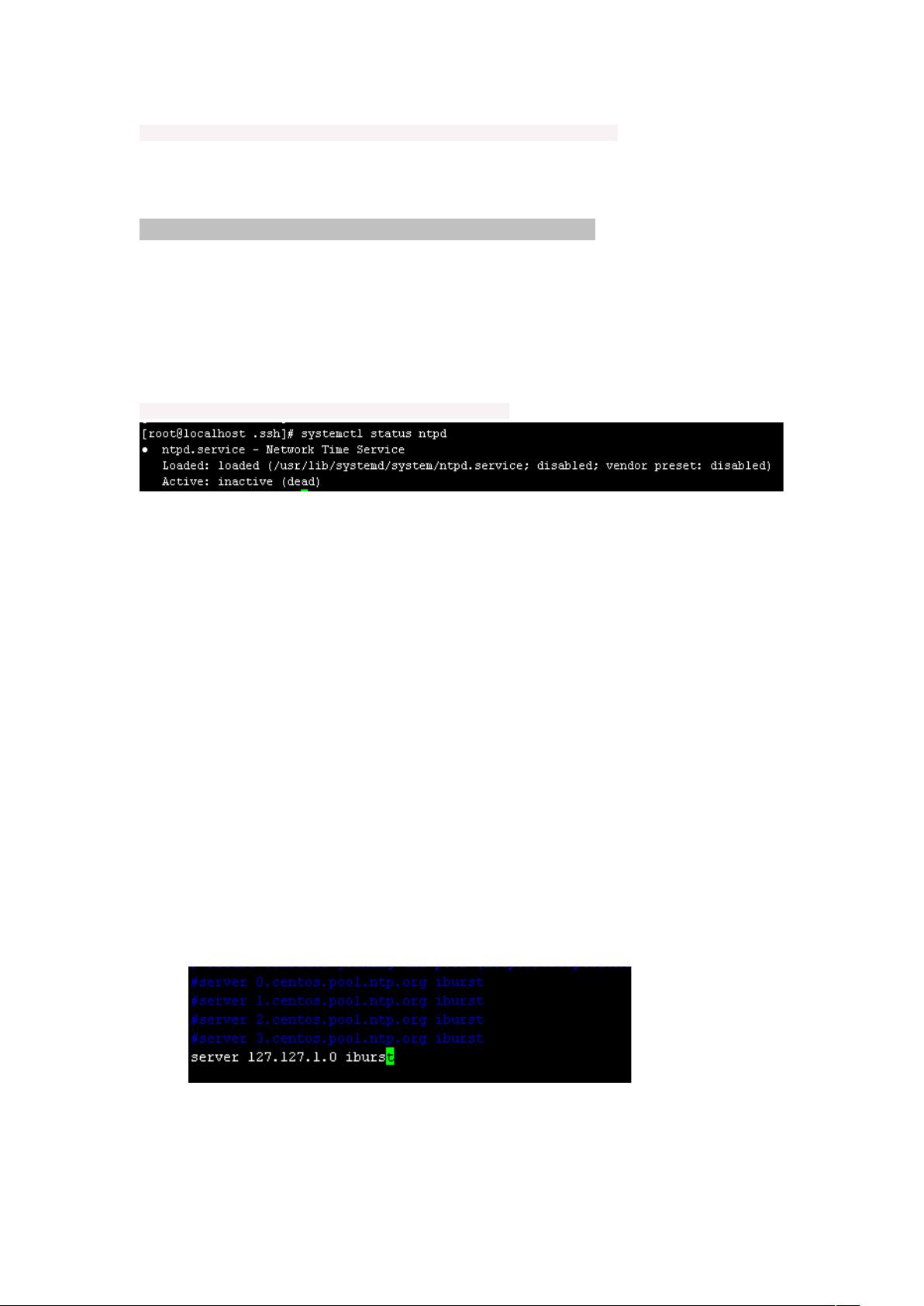
7.3.0 查看 ntpd 服务的状态
[root@localhost .ssh]# systemctl status ntpd
&%!&说明没有启动
7.4.0 配置 hadoop1 上的/etc/ntp.conf 文件
这里以 !& 作为时间同步服务器,!&/$!&/$!& 上的时间分别从
!& 上进行同步;
注释到如下的四行代码:
F%-%-$%-$-
F%-%-$%-$-
F%-%-$%-$-
F%-%-$%-$-
同时添加如下代码:
%-%-$44$-

剩余40页未读,继续阅读
2019-03-30 上传
2022-06-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2017-12-06 上传
2018-12-26 上传

听雨1
- 粉丝: 3
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
