哈希表数据结构详解:插入、扩容与查找
需积分: 49 170 浏览量
更新于2024-09-08
1
收藏 215KB DOCX 举报
"哈希表是一种高效的数据结构,它结合了数组和链表的优点,能够实现快速的查找、插入和删除操作。哈希表的核心在于它的哈希函数,它能够将键(key)映射到数组的特定位置,使得数据访问变得高效。然而,由于哈希冲突的存在,哈希表通常会采用链地址法来解决这一问题,即将相同哈希值的元素存储在一个链表中。"
在哈希表中插入元素的过程如下:
1. 首先,判断插入的键(key)是否为null。根据哈希表的定义,键不能为null。
2. 计算键的哈希值。这通常是通过调用键对象的hashCode()方法,然后可能再经过哈希函数的处理,以确保哈希值的分布更均匀。
3. 使用哈希值和哈希表的大小计算出插入位置的索引。这个索引是哈希值与表长度取模的结果,确保了哈希值始终在数组范围内。
4. 检查索引对应的数组位置是否已有元素。如果存在,会遍历该位置的链表,比较新插入的键是否已经存在于链表中。如果找到相同的键,更新对应的值并返回旧值;如果未找到,则继续插入新的键值对。
5. 插入新键值对时,可能会涉及到链表的操作。如果链表为空,直接创建一个新的Entry(哈希表中的内部类,包含键和值以及指向下一个节点的引用)并插入;如果链表非空,新键值对会被添加到链表的末尾。
哈希表的自动扩容机制是为了保持较低的负载因子(即已存储元素数量/数组大小),以维持高效的查找性能。当哈希表中的元素数量达到一定阈值时,哈希表会进行扩容,通常会将数组大小扩大一倍。原有的元素需要重新哈希到新数组中,这个过程称为再哈希。
查找元素在哈希表中是非常高效的。首先,同样计算键的哈希值并找到对应的数组索引。然后,遍历该索引处的链表,通过键的equals()方法比较找到匹配的键,返回对应的值。
在Java中,当我们自定义类作为哈希表的键时,通常需要重写hashCode()和equals()方法。这是因为哈希表依赖这两个方法来正确地计算键的哈希值并进行键值匹配。重写这些方法确保了相同的对象具有相同的哈希值,并且根据业务逻辑正确地判断两个对象是否相等。
验证哈希表的数据结构,可以通过阅读和理解相关类的源代码来实现,例如Java中的HashMap或HashSet。在HashMap的源码中,可以看到它使用一个Entry[]数组来存储键值对,每个Entry实际上是一个链表节点,包含键、值和指向下一个节点的引用。通过这种方法,哈希表能够在平均情况下实现O(1)的时间复杂度进行操作。
哈希表是一种重要的数据结构,通过巧妙地结合数组和链表,实现了快速的键值查找、插入和删除,广泛应用于各种场景,如缓存、数据库索引等。理解其工作原理对于优化程序性能至关重要。
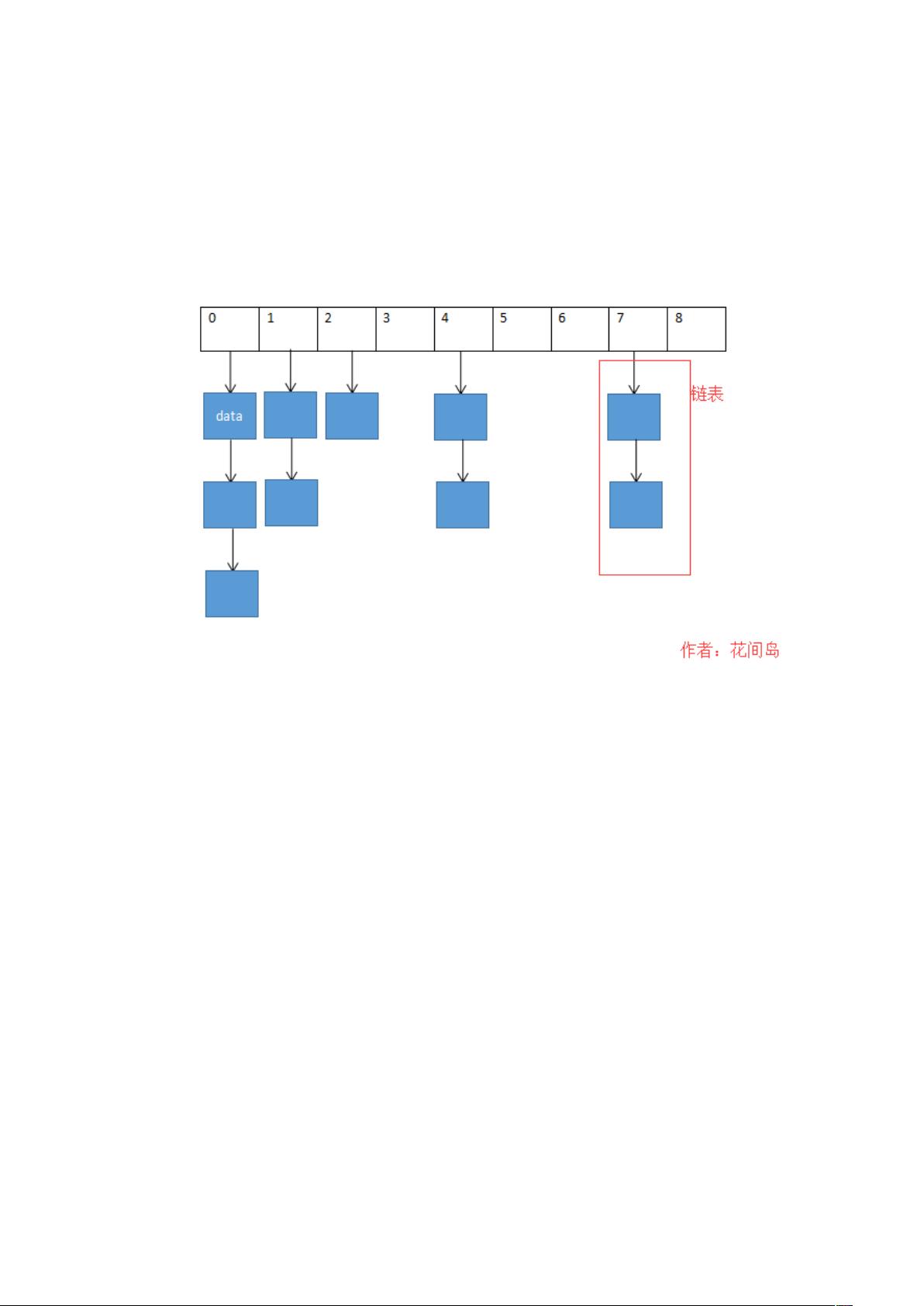
一、哈希表的数据结构?
哈希表是由数组和单链表两种结构组成。数组的查询效率高,增删效率低,
而链表的查询效率低,增删效率高。
如图所示,可以很直观的看到哈希表的数据结构。
带着下面几个问题来继续讨论哈希表:
1. 哈希表如何插入元素?
2. 哈希表如何自动扩容?
3. 哈希表如何查找元素?
4. 为什么要重写 hashcode 和 equals 方法?
二、验证哈希表的数据结构。
代码:
下载后可阅读完整内容,剩余5页未读,立即下载
2014-04-07 上传
2023-10-22 上传
2023-10-17 上传
2023-12-30 上传
2023-04-05 上传
2023-07-08 上传
2023-10-05 上传

Super-Henry
- 粉丝: 16
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
